周六,由于要赶一个月底的Deadline,因此选择了在家VPN加班,大半夜就爬起来跑用例,抓数据……自然也就没有时间写文章和外出耍了,不过利用周日的午夜时间(
不要问我为什么可以连续24小时不睡觉,因为我觉得吃饭睡觉是负担
),我决定把工作上的事情先放下,还是要把每周至少一文补上,这已经成了习惯。由于上周实在太忙乱,所以自然根本没有更多的时间去思考一些“与工作无关且深入”的东西,我指的与工作无关并非意味着与IT,与互联网无关,只是意味着不是目前我在做的。比如在两年前,VPN,PKI这些是与工作有关的,而现在就成了与工作无关的,古代希腊罗马史一直都是与工作无关的,直到我进了罗马历史研究相关的领域去领薪资,直白点说,老板不为之给我支付薪水的,都算是工作无关的东西。玩转与思考这些东西是比较放得开的,不需要对谁负责,没有压力,没有KPI,没有Deadline,完全自由的心态对待之,说不定真的很容易获得真知。
我认识一个草根鼓手朋友,玩转爵士鼓的水准远高于那些所谓的专业鼓手,自然带有一种侠客之风传道授业解惑,鼓槌随心所欲地挥舞在他自己的心中,没有任何负担和障碍,任何的节奏都可以一气呵成,从来不打重复鼓点,那叫一个帅!然而他并非专业考级出来的,是拜师出来后自己摸索的。
要兴趣去自然挥洒,而不是迫于压力去应对。
我也是鼓手,但我打的不是爵士鼓,我是鼓噪者,技术的鼓噪者。本文与TCP BBR算法相关。
0. 说明
BBR热了一段时间后终于回归了理性,这显然要比过热地炒作要好很多。这显然也是我所期望的。
本文的内容主要解释一些关于BBR的细节问题。这些问题一般人可能不会关注,但是针对这些问题仔细思考的话,会得到很多有用的东西。在解释这些问题时,我依然倾向于使用图解的方式,但这一次我不再使用Wireshark的tcptrace图了,而是使用时序图的方式,因为这种时序图既然能够令人一目了然地解释TCP三次握手,四次分手,TIME-WAIT等,那它自然也能解释更复杂的机制,比如说拥塞控制。
1. 延迟ACK以及ACK丢失并不会影响TCP的传输速率
在大的时间尺度上看,延迟ACK以及ACK丢失并不会对速率造成任何影响,比如一个文件4个TCP段正好发完,即便前面几个ACK全部丢失,只有最后一个到达,那它的传输总时间也是不变的。
但是在细微的时间段内,由于延迟ACK或者ACK丢失带来的时间偏差却是不可忽略的。
首先我们再次看一下BBR是如何测量即时速率的。测量即时速率需要做一个除法,分子是一段时间内成功到达对端的数据包总量,分母就是这段时间。BBR会在每收到一次ACK的时候测量一次即时速率。计算需要的数据分别在数据传输和数据被ACK的时候采样。很显然,我们可以想当然地拍脑袋得出一个算法:
设数据包x发出的时间为t1,数据包x被应答的时间为t2,则在数据包x被应答时采集的即时速率为:
Rate=(从x被发出到x被应答之间一共ACK以及SACK了多少个数据包)/(t2-t1)
但是这会造成什么问题呢?这会造成误差。如下图所示:
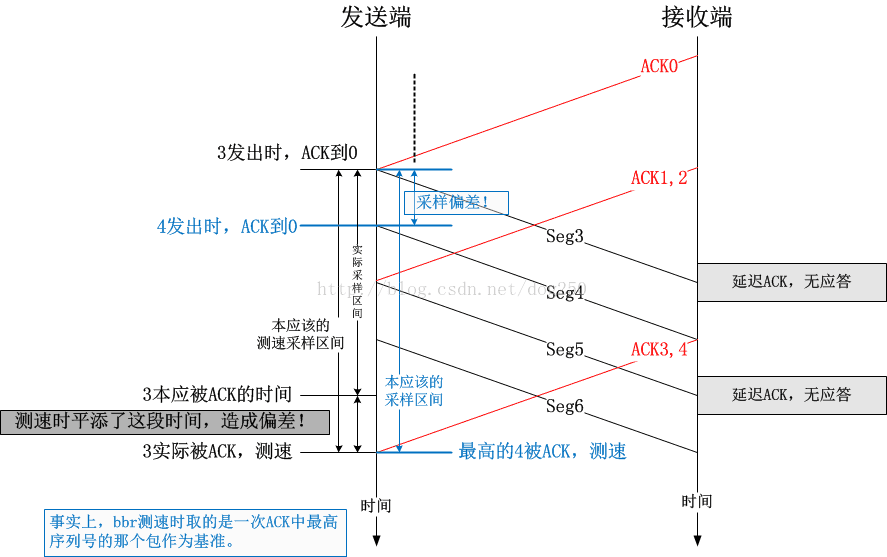
BBR如果依赖这种即时的速率测量机制来运作的话,在ACK丢失或者延迟ACK的情况下会造成测量值偏高。举一个简单的例子:
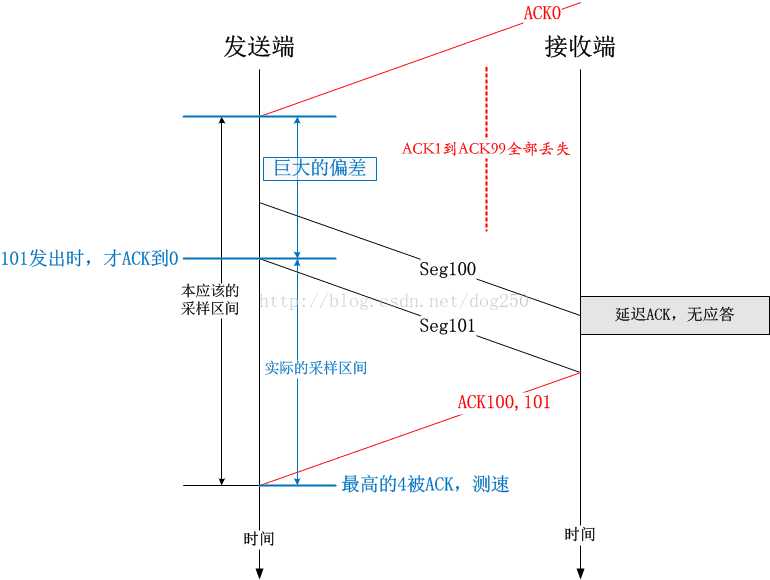
那么,BBR是如何做到不引入这种误差从而精确测量即时速率的呢?很简单,将t1改成至数据包x发出时为止,最后一个(S)ACK收到的时间即可。
详情请参考内核源码的net/ipv4/tcp_rate.c文件,原理非常简单。
所以说,BBR的速率测量值并不受延迟ACK,ACK丢失的影响,其测量方法是妥当的。之所以上面给出一个错误的方法,是想展示一下什么样的做法是不妥当的,以及容易引起质疑的点在哪里。
结论很明确,延迟ACK,ACK丢失,并不影响BBR速率的采集值。
接下来谈第二个问题,关于BBR的拥塞窗口大小的问题。
2. 为什么BBR要把计算出来的BDP乘以2作为拥塞窗口值?
这个问题可以换一种问法,即BBR的bbr_cwnd_gain值如何解释:

我们知道,BBR将Pacing Rate作为第一控制要素,按照计算得到的Pacing Rate平缓地发送数据包即可,既然是这样,拥塞窗口的存在还有何意义呢?
BBR的拥塞窗口控制已经退化到了规定一个限额,它主要是为了灌满管道,解决由于ACK丢失导致的无包可发的问题。
我先来阐述问题。
BBR第一次把速率控制计算和实际的传输相分离,又一个典型的控制面与数据面相分离的案例。也就是说,BBR核心模块计算出一个速率,然后就把数据包扔给Pacing发送引擎模块(当前的实现是FQ,我自己也实现了一个),具体何时发送由Pacing发送引擎来控制,二者之间通过一个发送缓冲区来交互,具体结构如下图:
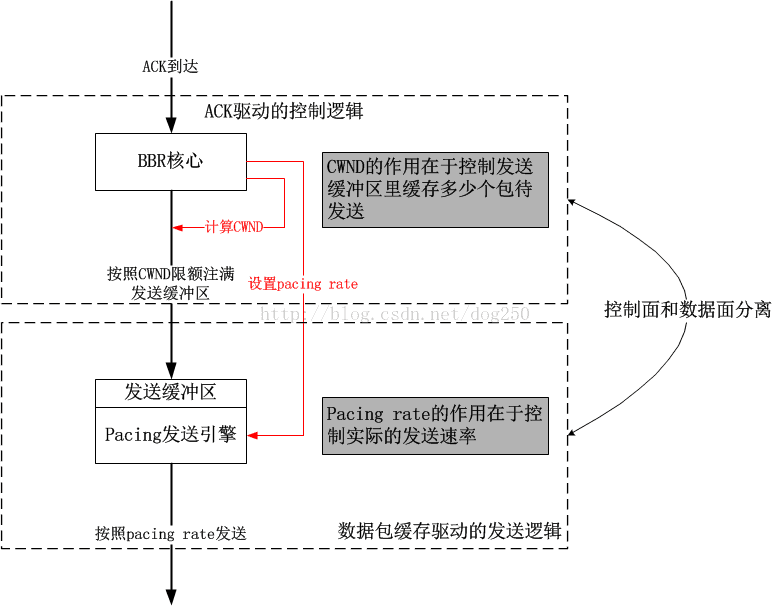
可见,拥塞窗口控制的是“到底扔多少数据到发送缓冲区合适”的。接下来的问题显然就是,拥塞窗口到底是多少合适呢?
虽然BBR分离了控制逻辑和数据发送逻辑,但是TCP的一切都是ACK时钟驱动的,如果ACK该来的时候没有来,比如说丢了,比如延迟了,那么就会影响BBR整个核心的运作,进而影响Pacing发送引擎的数据发送动作,BBR要做的是,即便没有ACK来驱动,也可以自行发送本该发送的数据包,因此Pacing发送引擎的发送缓冲区的意义重要,说白了就是,发送缓冲区里一定要有足够的数据包才行,就算ACK没有来,引擎还是有包可发的。
下面来展示一幅图:
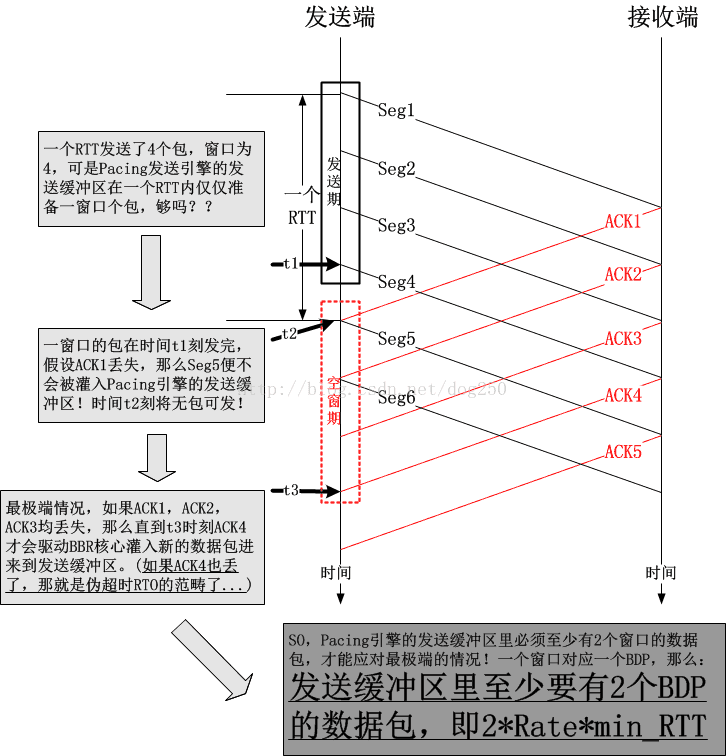
如果这个图有不解之处,像往常一样,大家一起讨论,但总的来讲,我觉得问题不大,所以说才会基于上图产生了下图:
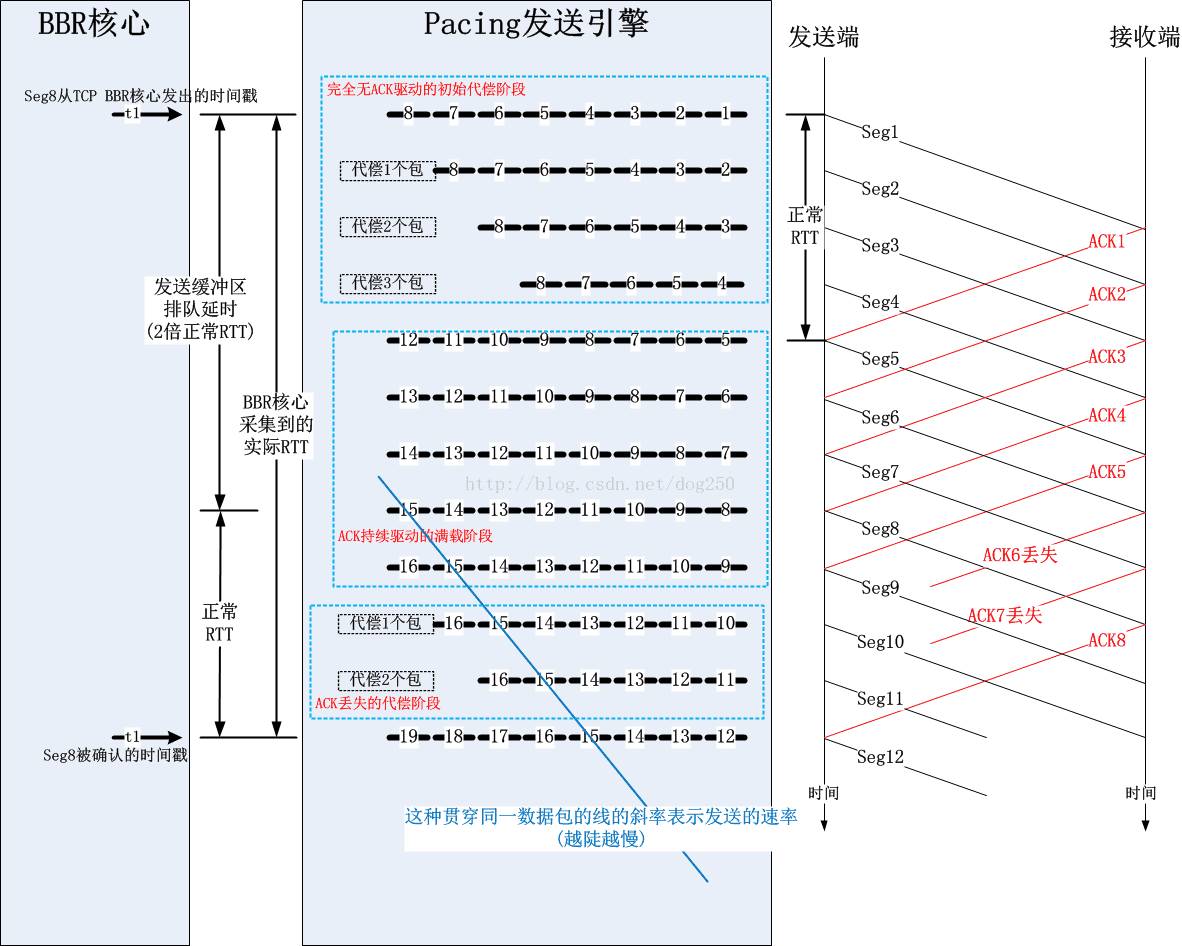
该图示中,我把TCP层的BBR核心模块和FQ的发送模块都画了出来,这样我们可以清晰看出拥塞窗口的作用。实际上,BBR核心模块按照拥塞窗口即inflight的限制,将N个数据包注入到Pacing发送引擎的发送缓冲区中,这些包会在这个缓冲区内部排队,最终在轮到自己的时候被发送出去。由于这个缓冲区里有足够的数据包,所以即使是ACK丢失了多个,或者接收端有LRO导致ACK被大面积聚集且延迟,发送缓冲区里面的数据包也足够发送一阵子了。
维护这么一个发送缓冲区的好处是在缓冲区不溢出(为什么不溢出?那是算出来的,正好两倍)的前提下时时刻刻有包可发,然而代价也是有的,就是增加了RTT,因为在发送缓冲区里排队的时间也要被算在RTT里面的。不过这无所谓,这并不影响性能,数据包不管是在TCP层的发送队列里,还是在FQ的队列里,最终都是要发出去的。值得注意的是,本地的FQ队列和中间节点的队列性质完全不同,本地的队列是独占的,主动的,而中间节点队列是共享的,被动的,所以这里并没有因为RTT的增加而损失性能。这就好比你有一张银行卡专门用来还房贷,由于利息的浮动,所有每月还款金额不同,为了不欠款,你每个月总是要存进足额的钱进去,一般要远多于平均的还贷额度才最保险,但这并不意味着你多存了钱这些钱就亏了,在还清贷款之前,存进去的钱早晚都是要还贷的。
3. 为什么在探测最小RTT的时候最少要保持4个数据包
首先要注意的是,用1个包去探测最小RTT会更好,然而效率可能会更低;用5个包去探测最小RTT效率更好,但是可能会导致排队,为什么4个包不多也不少呢?
我尝试用一个时序图来说明问题:
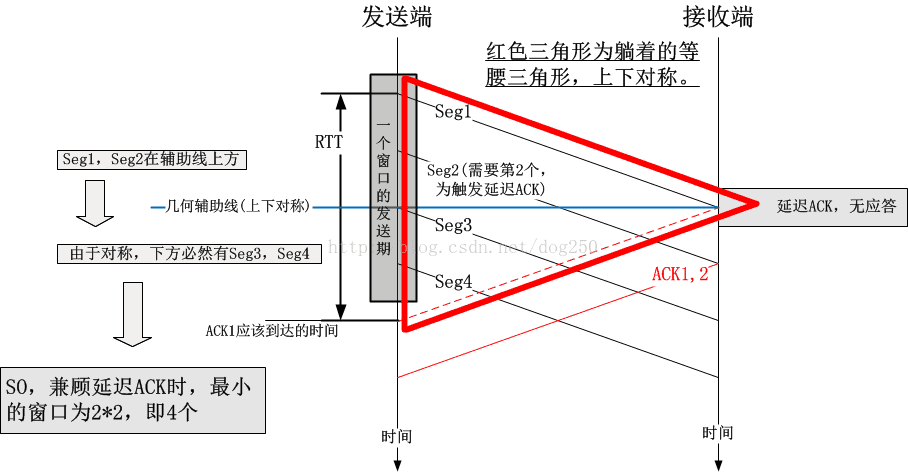
可见,4个包的窗口是合理的,infilght分别是:刚发出的包,已经到达接收端等待延迟应答的包,马上到达的应答了2个包的ACK。一共4个,只有1个在链路上,另外1个在对端主机里,另外2个在ACK里。路上只有1个包,这绝对合理,如果一条路连1个包都容纳不下了,那还玩个屎啊!
以上的论述,仅仅为了帮大家理解以下一段注释的深意:

4. 用时序图总览一下BBR的Startup/Drain/ProbeBW阶段
我以下面的时序图展示一下BBR的流程:
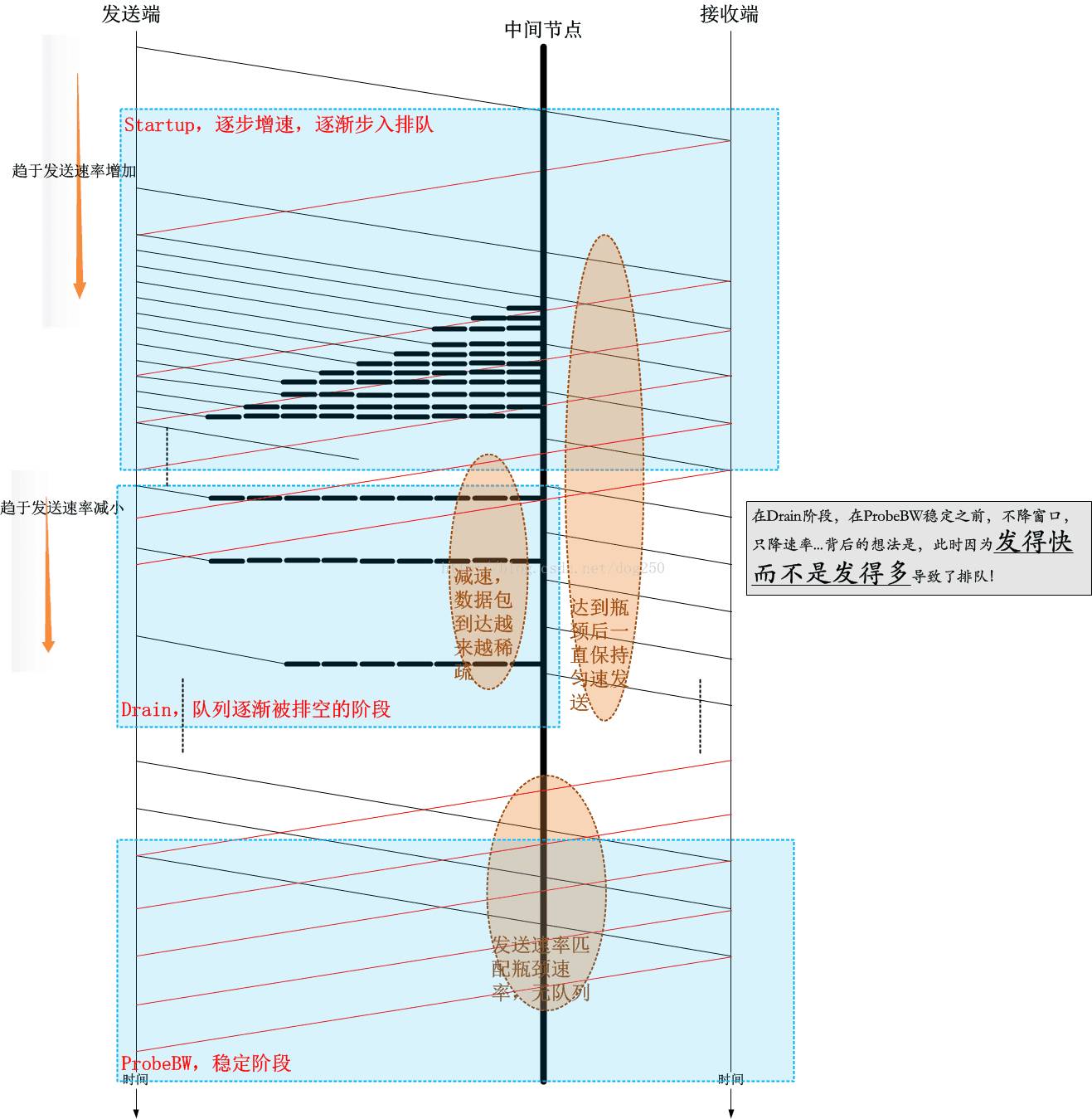
5. Startup阶段拥塞窗口计算的滞后性
我们知道,BBR里面拥塞窗口已经不再是主控因素,事实上它的名字应该改成“发送缓冲区限额”会比较合适了,为了方便起见,我仍然称它为拥塞窗口,虽然它的含义已经改变。
在Startup阶段,发送速率每收到一个ACK都会提高bbr_high_gain:

这个其实跟传统拥塞算法的“慢启动”效果是类似的。
然而BBR计算拥塞窗口是用“当前采集到的速率”乘以“当前采集到的最小RTT”来计算的,这就造成了“当前发送窗口”和“当前已经提高的速率”之间的不匹配,所以,计算拥塞窗口的时候,gain因子也必须是bbr_high_gain,从而可以吸收掉速率的实际提升。
6. 由ACK通告的接收窗口还有意义吗?
在以往的Reno/CUBIC年代,窗口的计算是根据既有的固定数学公式算出来的,完全仅仅由ACK来驱动,无视事实上的传输速率,所以彼一时的拥塞窗口仅仅可以代表网络的情况,即便如此,这种网络状态的结论也是猜的。
到了BBR时代,主动测量传输速率,将网络处理能力和主机处理能力合二为一,如果网络瓶颈带宽为10,而主机处理能力为8,那么显然采集到的带宽不会大于8!反之亦然。如果BBR测量的即时速率很准确的话,我想通告窗口就完全没有意义了,通告的接收窗口会被忠实地反映在发送端采集到的即时速率里。BBR只是重构了拥塞控制算法,但还没有重构TCP处理核心,我想BBR可以重构之!
7. BBR在计算拥塞窗口时其它的关键点
1) 延迟ACK的影响
计算拥塞窗口的时候,会将目标拥塞窗口进行一下调整:

此处向上取偶数就是为了平滑最后一个延迟ACK的影响,如果最后一个延迟ACK该来的没来,那么这个向上取偶数可以为之补上。
2) Offload的影响

8. 关于我的Pacing发送引擎
我在今年1月份写了一版和TCP BBR相结合的Pacing发送引擎,以消除FQ对RTT测量值(增加排队延迟)的影响,
个人觉得我这个要比FQ那个好很多,毕竟是原汤化原食的做法吧。
直接在TCP层做Pacing其实并不那么Cheap,因为三十多年来,TCP并没有特别严重的Buffer bloat问题,所以TCP的核心框架实现几乎都是突发数据包的,完全靠ACK来驱动发送,这个TCP核心框架比较类似一个令牌桶,而不是一个整型器!
令牌桶:
决定能不能发送;
整型器:
决定如何发送数据,是突发还是Pacing发送;
可见这两者是完全不同的机制!要想把一个改成另一个,这个重构的工作量是可想而知。因此我实现的那个TCP Pacing只是一个简版。真正要做得好的话,势必要重构TCP发送队列的操作策略,比如出队,入队,调度策略。
现阶段,我们能使用的一个稳定版本的Pacing替代方案就是FQ,我们看看Linux的注释怎么说:

本文来自CSDN博客:http://blog.csdn.net/dog250/article/details/72042516




