
先实际感受一下我们要抓取的福利是什么?点击 今日头条,在搜索栏输入街拍 两个字,点开任意一篇文章,里面的图片即是我们要抓取的内容。
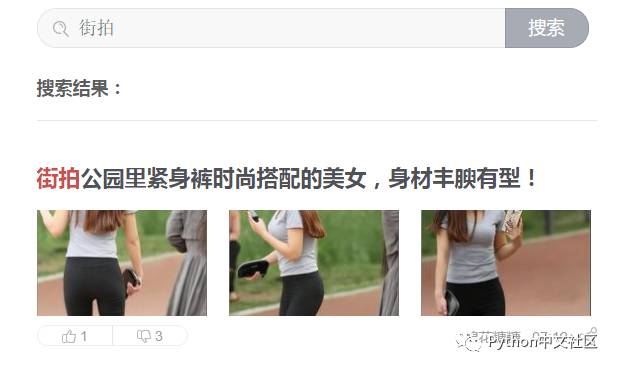
可以看到搜索结果默认返回了 20 篇文章,当页面滚动到底部时头条通过 ajax 加载更多文章,浏览器按下 F12 打开调试工具(我的是 Chrome),点击 Network 选项,尝试加载更多的文章,可以看到相关的 http 请求:
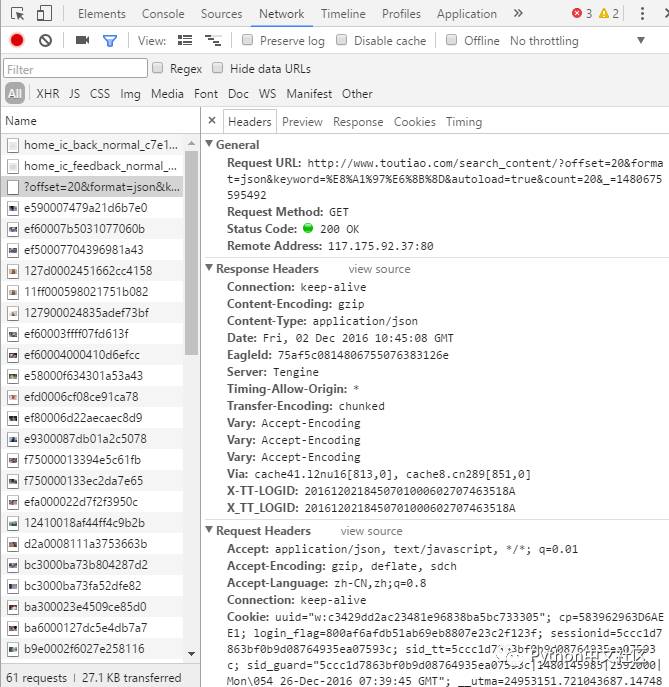
可以看到请求的 URL(Request URL)为:http://www.toutiao.com/search_content/, 其请求参数为:
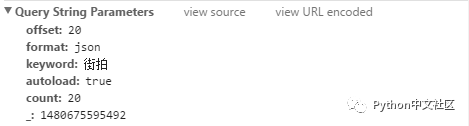
很容易猜测 offset 表示偏移量,即已经请求的文章数;format 为返回格式,这里返回的是 json 格式的数据;keyword 是我们的搜索关键字;autoload 应该是自动加载的指示标志,无关紧要;count 为请求的新文章数量;_ 应该是请求发起时的时间戳。将请求的 URL 和这些查询参数拼接即组成完整的 Request URL,例如这次的 Request URL 是: http://www.toutiao.com/search_content/?offset=20&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&_=1480675595492。
先让我们来看看这个请求为我们返回了什么样的数据。
import json
from pprint import pprint
from urllib import request
url = "http://www.toutiao.com/search_content/?offset=20&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&_=1480675595492"
with request.urlopen(url) as res:
d = json.loads(res.read().decode())
print(d)
这里我们首先通过 request.urlopen(url) 向这个 url 发送请求,返回的数据保存在 res 中,res 是一个 HttpResponse 对象,通过调用其 read 方法获取实际返回的内容,由于 read 方法返回的是 Python 的 bytes 类型的字符串,通过调用其 decode 方法将其编码成 string 类型字符串,默认为 UTF-8 编码。由于数据以 json 格式返回,因此通过 json.load 方法将其转为 Python 的字典形式。
打印出这个字典,可以看到字典中有一个键 ‘data’ 对应着一个由字典组成的列表的值,分析可知这个值就是返回的全部文章的数据列表,稍微修改一下代码,来看看 ‘data’ 对应的值是什么样的:
with request.urlopen(url) as res:
d = json.loads(res.read().decode())
d = d.get('data')
pprint(d)
这里使用了 pprint 让字典打印的出来的值更加的格式化,便于分析。可以看到这是一个由字典组成的列表,列表的每一个项代表一篇文章,包含了文章的全部基本数据,例如标题,文章的 URL 等。于是我们可以通过如下的方式来获取我们本次请求的全部文章的 URL 列表:
urls = [article.get('article_url') for article in d if article.get('article_url')]
这里使用了列表推导式,循环文章列表,通过 get('article_url') 获取到文章的 URL,加上 if 判断条件是为了防止因为数据缺失而得到空的文章 URL。我们将通过不断请求这些文章的 URL,读取其内容,并把图片提取出来保存到我们的硬盘里。
先来处理一篇文章,看看我们如何把文章里的全部图片提取出来。
随便点开一个文章链接,按 F12 查看网页源代码,可以看到文章的主体部分位于一个 id="article-main"
的 div 里。这个 div 下有 h1 标签表示文章标题,另外一系列 img 标签,其 src 属性即保存着图片所在的链接,于是我们通过访问这些链接把图片下载下来,看看具体怎么做:
url = "http://www.toutiao.com/a6351879148420235522/"
with request.urlopen(url) as res:
soup = BeautifulSoup(res.read().decode(errors='ignore'), 'html.parser')
article_main = soup.find('div', id='article-main')
photo_list = [photo.get('src') for photo in article_main.find_all('img') if photo.get('src')]
print(photo_list)
# 输出:
['http://p9.pstatp.com/large/111200020f54729cd558', 'http://p3.pstatp.com/large/11100005d3e8b9e69a88', 'http://p3.pstatp.com/large/106b00058387c12351c7', ...]
这里我们请求文章的 URL,将返回的内容(html)传递给 BeautifulSoup 为我们做解析。通过 find 方法找到 article-main 对应的 div 块,在该 div 块下继续使用 find_all 方法搜寻全部的 img 标签,并提取其 src 属性对应的值,于是我们便获得了该文章下全部图片的 URL 列表。 现在要做的就是继续请求这些图片的 URL,并把返回的图片数据保存到硬盘里。以一张图片示例:
photo_url = "http://p9.pstatp.com/large/111200020f54729cd558"
photo_name = photo_url.rsplit('/', 1)[-1] + '.jpg'
with request.urlopen(photo_url) as res, open(photo_name, 'wb') as f:
f.write(res.read())
此时就可以在当前目录下看到我们保存下来的图片了。这里我们使用了 URL 最后一段的数字做为图片的文件名,并将其保存为 jpg 的格式。
基本步骤就是这么多了,整理下爬取流程:
指定查询参数,向 http://www.toutiao.com/search_content/ 提交我们的查询请求。
从返回的数据(JSON 格式)中解析出全部文章的 URL,分别向这些文章发送请求。
从返回的数据(HTML 格式)提取出文章的标题和全部图片链接。
再分别向这些图片链接发送请求,将返回的图片输入保存到本地。
修改查询参数,以使服务器返回新的文章数据,继续第一步。
完整代码挂在了 GitHub 上 ,代码中已经加了详细的注释,我运行此代码后一共爬取了大概 1000 多张图片。
优秀人才不缺工作机会,只缺适合自己的好机会。但是他们往往没有精力从海量机会中找到最适合的那个。
100offer 会对平台上的人才和企业进行严格筛选,让「最好的人才」和「最好的公司」相遇。
扫描下方二维码,注册 100offer,谈谈你对下一份工作的期待。一周内,收到 5-10 个满足你要求的好机会!

— Life is short,we use Python —











