来自:博客园,作者:王的博客
链接:https://www.cnblogs.com/cnblogs-wangzhipeng/p/8270075.html
Factom这个Solution在2014年的时候就已经推出了,但是它依然十分具有参考价值的。因为现阶段来开区块链虽然炒得火热--养猫、养狗、草泥马之类的,但是真正成熟的应用比较少,有很多连基本的链平台都没有开发完全。而bitcoin作为区块链的1.0时代的代表,也是区块链行业的标杆存在,它的生态是最完整的--矿池、钱包、交易所。但是相对于区块链2.0Ethereum来讲功能就比较单一了,它的智能合约--公钥脚本功能单一,不是图灵完备的。基于bitcoin开发的应用就比较少,而ethereum上面的应用就多达800多个(养猫应该是最火的了)。
但bitcoin不是说不能基于它去做一些事情,它也有一些扩展协议可以让bitcoin Blockchain来发挥更大的作用,比如说 OP_RETRUN 扩展交易。而Factom就是基于这个协议,如果换做此时此刻的话,Factom的创始人可能会选择更加方便的Ethereum,而不是Bitcoin,但在14年的时候以太坊还不是很成熟,而Bitcoin则更加的稳定可靠,时至今日Bitcoin很少会因为本身的漏洞而造成财产损失,大多数都是因为交易所遭受攻击而导致大量的Bitcoin被黑客盗取。这一点一要归功于 pow这个被人‘诟病’的协议,二、它没有支持图灵完备的智能合约,功能单一也有好处,有时越简单粗暴的越可靠,像以太坊就因为智能合约sdk的漏洞造成过两次大规模的ether泄露。
一、Bitcoin的 OP_RETRUN协议介绍
OP_RETURN是一个脚本操作码,用于将事务输出标记为无效。由于任何带有OP_RETURN的输出可证明是不可靠的,OP_RETURN输出可以用来烧毁比特币。
比特币社区的许多成员认为使用OP_RETURN是不负责任的,部分原因是比特币旨在为金融交易提供记录,而不是任意数据的记录。此外,对于外部大规模复制数据存储的需求本质上是无限的,这一点显而易见。
尽管如此,与在区块链中存储数据的一些其他方式相比,OP_RETURN具有不会创建虚假UTXO条目的优势。 从比特币核心版本0.9.0: 这种变化并不意味着将数据存储在区块链中。
OP_RETURN类型的交易请求创建了一个可证明的可修剪txo,以避免数据存储方案(其中一些已经部署)将诸如图像之类的任意数据存储为永远不可用的TX输出,从而膨胀了比特币的UTXO数据库。 在区块链中存储任意数据仍然是一个坏主意,在其他地方存储非货币数据的成本更低,效率更高。
二、Factom的基本原理
在阐述基本原理之前,我先说几个有关于Factom的关键词:
Factoids :
factom发行的代币,使用factom的服务时要消耗代币,而且不可以交易。
Entry Credits:
提交Entry时要消耗 Credits,而Credits是用Factoids换取的,可以交易。
Entry:
提交到Factom上存储的文件
Entry Block:
记录Entry完整性(Hash值)证明的区块
Directory Block:
记录Entry Block块完整性(Hash值)证明的区块
ChainID:
APPlication的账本ID
APPlication:
基于Factom服务开发的应用
Federated Servers:
用来管理运行Factom的分布式服务集群
Auditing Servers:
审查节点,这些审查节点负责审查
Federated Servers的生成的账本是否合法
看到这,你想必应该猜测到了,Factom是有自己的账本--chain的,不光Factom有每一个App都有自己对应的chain。
factom存证充分的利用了Merkle Hash tree,它的最基本原理就是: 首先将一段时间内上传的数据都纳入到Merkle Hash tree(间接或者直接);然后每隔10min中Root Hash加入到OP_RETRUN交易中,锚定到bitcoin区块链。
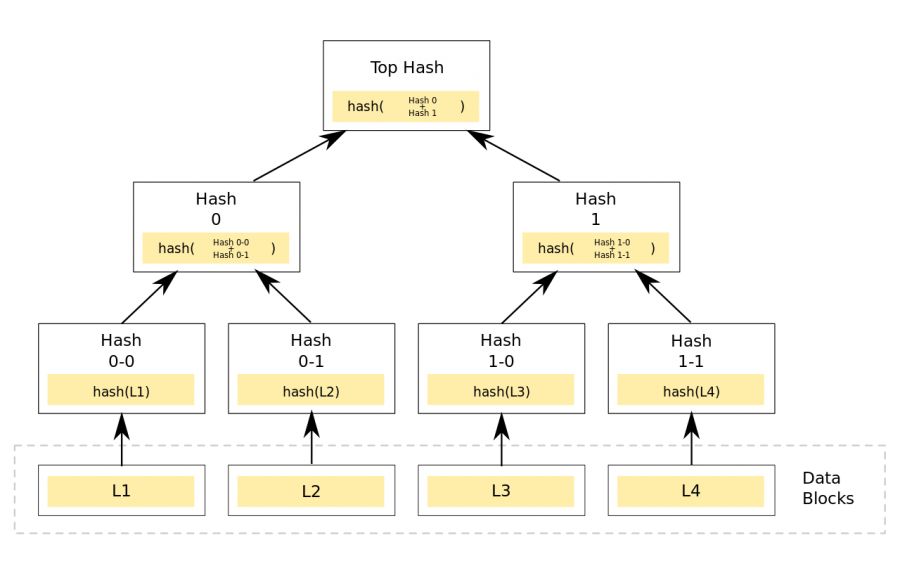
稍微了解过bitcoin原理的老铁应该都知道Merkle tree的精妙之处--假定root hash是正确的,则在不知道其他叶子节点的情况下,仍然能证明单个叶子结点的完整性。
这样做的好处就是你可以不需要关心其他叶子结点(在Bitcoin中是Utxo,在factom中是Entry数据),也能证明自己的完整性,有老铁可能就问了这么费劲干啥?咋不直接把Entry的Hash锚定到Bitcoin上?贵啊!现在一个Bitcoin市值$14,000左右,矿工费最低要0.0009(不同矿池收费标注不同),而且十分钟才能添加一块,还要等待6个块确认,不说矿工费开销大,效率也低啊。利用Merkle tree可以上传最少的数据 32bytes(上面说过一个OP_RETURN最多40),同时又能证明大量的数据完整性,何乐而不为?
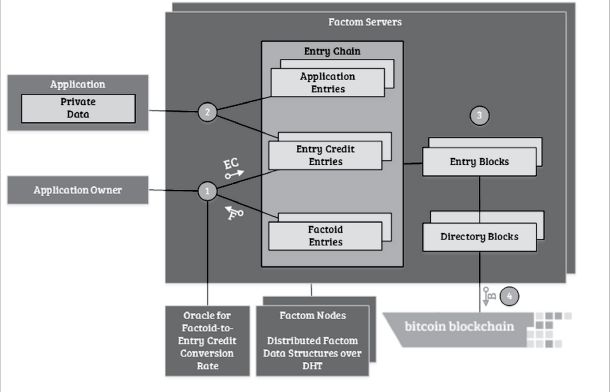
本图将Factom大致的逻辑关系已经呈现的很清楚了:
1.APP的运营者先去Factom上买Factoids,然后将Factoids兑换成Entry Credit
2.APP将数据提交到Factom Servers,加入该APP对应的Entry Chain
3.将 当前周期内上传 Entry 打包成 EntryBlocks(白皮书上显示 1min钟生成一个块);
4.将 当前周期内生成的EntryBlocks 打包成 Directory Blocks;
5.间隔一段时间(白皮书显示是10min,正好是比特币生成区块的平均时间)将未锚定的Diretory Blocks加入到一个Merkle tree中(按照白皮书说法应该是10块);
6.将root hash 锚定到Bitcoin中
APP参照了中本聪在bitcoin白皮书中提到的SPV原理,只要关心和自己相关的数据就好了。
三、Factom的组织架构
Factom整个架构体系中有三层,如下:

Factom 的账本有四层,如下:
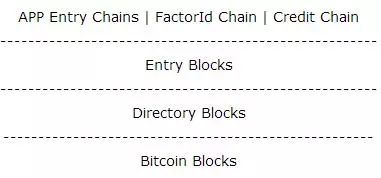
3.1 我们先按照架构体系来说:
APPlication :
由开发者开发面向用户的应用,它们都使用了Factom的服务来做数据存储证明。我们下面描述一下APP加入Factom的过程:
setup 0:
一个APP在初始化加入Factom体系时候做的第一件事就是充钱(不充钱你怎么能变强?),你将公钥发送给Factom Server,Factom Server会分配给你一笔 Factoids,这笔交易会记录在FactorId Chain中。
setup 1 :
服务器 会向你反馈一个Entry 确认信息, 同时会向外广播这个确认信息(我们前面说过factom 是有一个分布式服务集群的)
setup2:
APP用Factoids换取Entry Credit, 服务器会将这笔交易记录在Credit Chain中,同时向外广播。
setup3:
APP上传第一个实体Entry(初始化,里面包含着你自己定义的Entry校验规则的Hash值,或其他细则),服务器会帮你创建一个对应ChainId的账本,同时扣除相应的Credit,向外广播消息。
ps: ChainId ID是由APP自己定义的ChainName的Hash值。
创建后提交一个Entry的过程就是setup 1~3的过程,当然客户端看起来就这么简单,在服务端就复杂多了。同时这里面我们要重点强调的是,Factom服务器不负责校验Entry 数据的合法性,数据的合法性是在APP这一端校验的。我们可以在创建账本的时候将校验规则(比如一个审计程序)的Hash加入到第一个Entry中,这个审计程序在APP运行,这样就能屏蔽掉那些无效的Entry。
Factom Servers:
factom有一个分布式的服务集群,每一个服务器都会负责一维护部分APP的账本,同时将更新同步到其他服务器中。Factom中服务器有两种类型,一种是记账服务器,一种是审查服务器。
我们来讲一下servers的工作过程,首先介绍几个关键词:
process list:
每一个服务器都要维护一个list,这个列表里面存储着本服务器和其他服务器负责的chain。
Weighted Number of Entry Credits:
根据消费的Credits计算出投票权重用于选择Factom Server
Weighted Number of Entries:
根据Entry计算出投票权重用于选择Factom Server。
Factom Servers一个记录周期如下:
1、对最后一分钟的Entry块创建梅克尔根(Merkle Root),按ChainID排序。
2、创建最后一分钟的目录区块,并计算其梅克尔根(Merkle Root)。
3、
用10个目录区块的梅克尔根(Merkle Root)创建一个锚定。
4、用服务器的反向哈希值集合来创建一个种子,再用其选择下一个服务器来把锚定写到比特币区块链
5、所有服务器重设其进程列表(Process List)为空。
6、用户通与其Entry信用的积分(Entry Credit)相关的公钥提交付款
7、
根据用于支付的公钥,轮值服务器接受该付款。
8、该服务器向网络广播该支付被接受。
9、用户看到支付被接受, 然后提交Entry。
10、根据Entry的ChainID,其中一台服务器把Entry加入其进程列表,并添加进入到相应链的区块中(如果这是该链的第一个Entry, 那就创建这个新链)。
11、服务器对网络广播该Entry的确认,内容含有Entry在Process list 中的位置(Index) + Hash(Entry)(链接到Entry付款)+ Hash(process list)。
12、所有其他服务器更新该服务器的process list,验证该列表,并更新该链的区块。
13、只要用户可以验证到相关的 process list 中包含自己的提交的数据Entry,那么他们就可以有相当的信心相信它会被成功地被录入到Factom上。
14、在一分钟结束时,所有服务器确认process list 的 高度,揭示一个确定性的秘密数值(该值为一个Reverse Hash 值,即一条较长的,连续的区块链哈希值的原像值),还有被处理区块的一系列哈希值(将与 process list 中的最后一项相匹配)。
15、那一分钟的目录区块(Directory Block)是由所有服务器中定义的所有Entry区块(Entry Block)组合到一起建造而生成的。因此,每个服务器都拥有所有的Entry区块(Entry Block),所有的目录区块(Directory Block),和所有Entry(all Entries)。
16、使用Reverse Hash值的集合来创造一个种子,为下一轮的ChainIDs重新分配服务器。
17、在完成10个目录区块后,请执行以下操作:
18、重复。 (又从第1部开始循环)
Factom 为了防止腐败发生,所以它的Servers集群中记账的服务器是会不断变化的,每隔4个小时进行一次选举,由user投票来决定哪些服务器能够成为Factom的记账服务器,用户投票的权重是根据Weighted Number of Entry Credits和Weighted Number of Entries计算出来的,所有的服务器都会参选最后进行一个排名,然后选择前n名成为Federated Servers 其余的为Auditing Servers。
为了防止被选择的服务器发生故障,每隔四秒就要广播心跳包(Entry 确认信息),如果一台服务器没有收到 X 的心跳包就会发送一个SFM信息认为X是故障的,如果大多数(没有给出阈值)认为X服务器是故障的,那么X服务器就会降级,由第n+1名服务器升级为Federated Servers,X 降级为Auditing Servers。
ps0:大家可能会困惑既然合法性校验放在了client side,那么Auditing Servers有个卵用?Auditing Servers 有两个作用: 一、审查Federated Servers生成块是否符合规则;二、为Entry 提供存在性证明(Proof of existence)(这是从Factom社区里面得到的回复)。
ps1:Weighted Number of Entry Credits: 加权最近六个月购入的入场券数量(每月购买金额,当月加权6次,前5次加权等) ;Weighted Number of Entries: 加权最近六个月使用的条目数量(每月使用的条目数量,当前月份加权6个,前一个加权5个)。
bitcoin miner:这一层我就不多说了。
上面就是按照体系架构来讲述一下它工作的基本流程,Factom的实现比较复杂。
3.2 我们再按照账本层次来说:
Directory Blocks
目录块中引用的每个Entry块占用64个字节(两个32字节散列,Entry Block的ChainID和Merkle根)。一百万个这样的条目将导致一组目录块大小约为64MB。如果平均的每个Entry Block有5个Entry,64 MB的Directory Blocks将提供500万个不同Entry的高级管理。
Factom服务器收集Entry Block的Merkle根并将它们打包到目录块中。十个连续的目录块通过Merkle树散列,Merkle根被记录在比特币区块链中。这允许区块链的最小扩展,并且仍然允许通过比特币散列权限保护分类账。
将Merkle根加入比特币区块链的过程称为“锚定”。
有关更多详细信息,请参阅“附录:比特币时间戳”部分。从带宽和存储的角度来看,输入到目录块中的数据是最昂贵的。如果Factom用户希望在链中找到数据,那么他们需要从账本创建时开始的所有目录块。
会增加目录块大小的Active 包括 APP chain 的创建和首次更新。这些Active将 APP 程序细化账本规则的 花费 进行了公示。相比记录一个Entry,APP必须要花费更多的Entry积分来执行这些特殊的Active,这样可以阻止目录块的膨胀。也就是说实际上Directory block中记录的是一个map
的表。
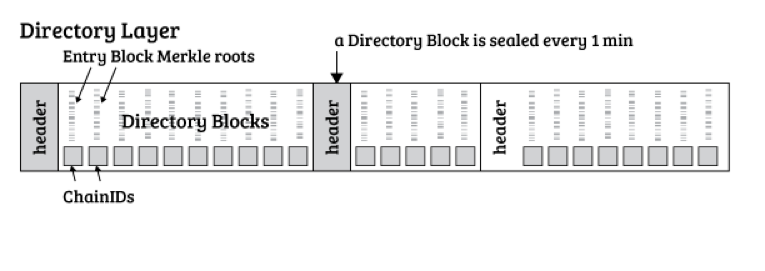
Entry Blocks
Entry Block Later 是系统中的第二层级。APP 将拥有各自的ChainID。在 Entry Blocks 里,APP可以ChainID为线索扩展搜索所有相关的条目。
每个目录块中包含的chainId 都会有一个更新的Entry Block。Entry Block包含上传的Entry的散列值。
Entry的哈希证明了数据的存在,同时也充当在分布式哈希表(DHT)网络中查找Entry的Key。 (更多细节参见“Factom点对点网络Entry Block 有意不包含 Entry 本身。这使得Entry Block 很小。从Entry Block 中分离 Entry 还可以使审计人员更容易审计。审核员可以在一个单独的链中,这个链用来记录那些来自普通链中的被批准或被拒绝的Entry。
审核员可以在其Entry中增加拒绝的理由。如果应用程序信任审核员,他们可以交叉引用审核员批准或拒绝每个Entry,而不需要知道Entry是什么。然后应用程序将只尝试下载通过审计的Entry。多个审计人员可以引用相同的Entry,并且条目将只在分布式散列表(DHT)上存在一次。









