
(没看过、忘了的童鞋点进去)
1. 学前准备。给大家基本说明了课程的内容大纲和学习思路。
2. 深度学习和机器学习的关系。emmm……这个回去看上篇文章。
3. 模型是什么。同上~
4. 模型的质量。建议大家看视频😳
5. 模型训练的概念。我觉得需要数学基础了~
6. 课间休息。对上述学习内容的小总结。
今天的内容:
7. 数据预处理
数据预处理是数据方(甲方)能做的最重要的工作,模型训练的过程太难且有随机性,数据方完全可以将训练的工作外抛给专业团队或者外部厂商去做模型训练,甚至挂到众包市场上让乙方自由竞争。
如下图是我们手头这份数据,按照前文学习的内容,我们应该将下图表述为,这个数据集有506个样本,每个样本有13个Feature,具体的房价数字就是Label。
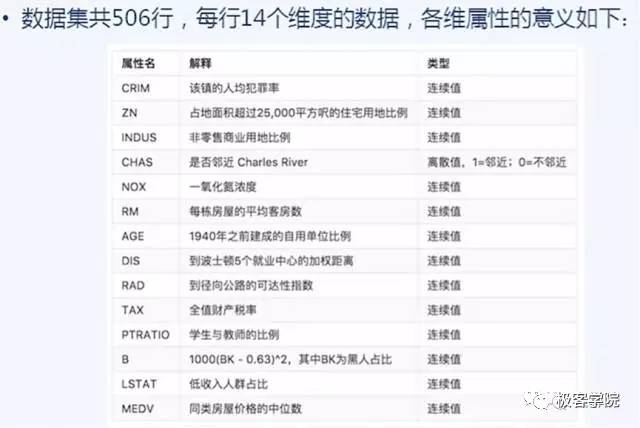
在这个时候我们就可以看到一个很有意思的特性,如果没有前一个图中对数据的标识,模型训练者只拿着数据集可以训练模型,但很难理解和解释这个模型中每个Feature是什么意思,也不知道最后的Label就是房价。对于数据拥有方来说,并不太担心模型训练方会泄密这份数据集,或者将训练好的模型同时卖给几个友商。
即使模型训练方能从原始样本中猜出来这是什么信息,
数据集预处理过后就更不用担心泄密问题了
,甚至银行的交易数据都可以脱敏导出来。
数据预处理主要不是为了保密脱敏,而是因为Feature的数值提供的是“趋势”和“相关性”参考,而非绝对值参考,用绝对数值无法描述Feature和Label的相关性。首先数值范围太大可能造成浮点溢出,比如到说房价信息用美分甚至津巴布韦币来表示,很快就会超出计算机可处理的数值范围。这些数值只能用于在样本之间同Feature进行对比的,样本内不同Feature之间没有可比性;比如说房价信息跟距离河流是1500米还是1800米有关系,也跟该社区的犯罪率是0.01%还是1%有关系;但如果不做数据预处理就直接做运算,距离米数的1500肯定会将犯罪率的0.01压缩到忽略不计的地步。此外还有属性用0或1表示“Ture”和“False”的离散值,并没有谁大谁小的关系。
基于上述原因,我们需要将原始样本数做“归一化”处理,即将大部分数据处理成“-1到0到+1”的趋势指向数据,很多机器学习的框架和技巧对归一化数据都有很好的优化。
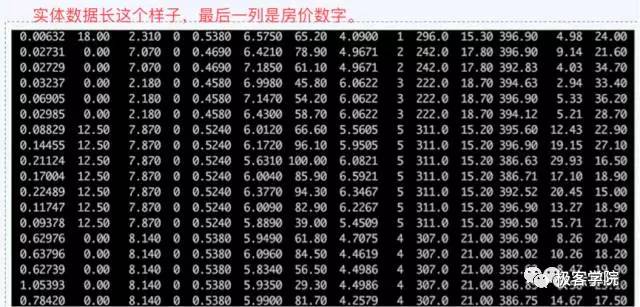
归一化处理过的数据会变成这个样子,可想而知这类数据并不怕泄密。

上述工作描述起来复杂但执行很简单,使用PaddlePaddle的处理框架,一行代码即可完成读取数据集、数据归一化、生成小批量样本三个工作。





