
阅读小组第一期,我们精读的文章是
Image Caption
方向的
MAT: A Multimodal Attentive Translator for Image Captioning
。
首期活动得到了大家的积极响应,我们收到了很多同学发来的笔记,大家也就各种细节进行了很多高质量讨论。
>
>
>kyleyang<
<
<
该模型的核心观点:首先对图像进行 object detection,将检测到的 object 序列逐个输入到 RNN 中,在 decoding 阶段输出单词。图中,O 为检测到的 object representation,最后还需要输入全图的 CNN feature 作为 global environmental information。
在以往 image captioning 研究中,attention 机制都建立在图像的 feature map 之上,这在一定程度上提高了对图像内容描述的准确度,但是并没有在 encoding 时很好地利用语境信息。
我们可以观察到,在 object sequence 中距离开头非常近的 object 可能和 decoding 时靠后的单词有较大的关联。例如,图片中可能有一只狗的检测分数最高,因而会在 encoding 时排在序列的第一位,但是“dog”这个词也许会出现在句子的末尾(A man is playing with a dog)。所以在生成单词时,作者使用了 attention layer 计算当前 decoding 状态与所有 encoding 隐状态的相关性。
>
>
>carrot<
<
<
讨论下更 general 的问题,现在 image caption 基本是只要物体识别做的好,出来的句子就不会差,现在大部分方法也都是在做物体识别,把物体识别的信息加到模型里。那 image captioning 这个问题的独特性在哪里? 而且模型之间的能力感觉现在的评测标准根本反应不出来,就算能说一句对的话也不一定代表能理解图片的意思,感觉 image QA 才更加 well defined 能体现不同模型的能力,大家怎么看?
>
>
>Issac<
<
<
本文最有新意的是把 image caption 做成了 machine translation ,形成了一种 CNN+encoder+decoder 的 multimodel,在 encoder 中多次将 detection 输入(不同于 ACVT 在 feature 层级上融合),并且对于每个预测单词,结合所有 detection 进行评分(简直套用 machine translation 里面的思想,不同于 show attend an tell 在 feature 层级上找关注点),attention layer 相当于对词图匹配,不同点主要在于应用的层级。
>
>
>rwang<
<
<
我感觉这篇文章做的还不够完善。比如说,需要额外一个实验把 encoder 去掉,但是保留 attention layer,看看结果如何。这样才能证明 encoder 所编码的 context 信息有用。你们觉得呢?
rwang
:感觉文章里实验结果好,主要来自于对多个物体的独立表示和 attention layer 的 sequential 选取 object's representation,而非 encoder 对 objects representations 的 sequential encoding。你们怎么看?
kyleyang
:对,把 detection 的结果拿出来做翻译确实是个比较新的方法。encoder 应该目的在于对接上 seq2seq 的框架。
rluo
:不知道定论,只能说他的实验绝对有欠缺。我也同样好奇。
xmyqsh
:基本同意你的看法,如果想反驳你的看法的话,就应该从 objects representation 序列中 object 的先后顺序能不能反映出一些信息量这个角度思考。
kyleyang
:attention layer 的目的其实就在于减少顺序的影响,你认为能反映出什么信息量?
rwang
:同感。所以这边文章里用 encoder 去做序列编码所起到的作用很不清楚,其作用也就不具有说服力。
xmyqsh
:说的不是 attention 的信息量,是 objects 按 score 排序的信息量,我觉得 objects 随机排序影响也不大。
sophieag
:我想问一下,他 finetune resnet 了么?
rluo
:我觉得他是把 rfcn 用作预处理步骤的,要不不可能 12 小时。 而且从 coding 角度,我觉得直接用会比较方便一点2333。
kyleyang
:确实是直接用最方便,所以他不是 end2end training。
rwang
:应该没有 fine-tune,只是拿过来直接用的吧。
kyleyang
:文中没有提及,理论上来说可能 fine-tune 可能会好一点。
xmyqsh
:数据有标注的话 finetune 一下还是有提升的,不如 pooled featuremap 可能不太准。
rluo
:我觉得发邮件问吧,就是 1. sequence encoding 有必要吗?2. highest to lowest 是最好的 order 嘛?或者换了 order 结果会有什么区别吗?
本期阅读小组的关键词为,我们将一起精读下文并通过在线协作工具进行交流,参与者需具备当期 topic 的研究背景,并在活动开始前完成论文阅读(活动细则详见文末)。
A Character-Level Decoder without Explicit Segmentation for Neural Machine Translation
文章来源
https://arxiv.org/abs/1603.06147
作者
Junyoung Chung, Kyunghyun Cho, Yoshua Bengio
单位
University of Montreal, New York University
关键词
Neural Machine Translation, Character-level
问题
无论是 SMT 还是 NMT 一般都是基于"词"的,本文在经典的 attention-based seq2seq 模型之上,提出了一种在 decoder 端基于“字”的翻译,并验证了其有效性。
模型
Motivation
研究"字"级别的机器翻译主要的原因是:在任何语言中都很难得到一个完美的分词模型。分词模型带来的误差会极大影响到“词”级别翻译模型的效果。例如:在英语中,利用较简单的分词模型,会认为 run, runs, ran, running 是四个不同的词,因此对应着四个不同的词向量。而我们更希望得到的是将其分词为 run, s, ing。
另外,在基于词的翻译中,词表一般只考虑最常见的几万个词,而不常见的词会被标记为 UNK。尤其有些时候,某个不常见的词其实是一个常见词的不常见变体。而在基于字的翻译中则不存在这个问题。
同时,NMT 的发展给基于字的翻译提供了可能。因为传统的 phrase-based 的翻译本质上是子串的概率统计,而基于词的子串个数远远少于基于字的子串个数。因此传统方法并不适合去做字级别的翻译,但是 NMT 则不存在这个问题。另外,基于“字”翻译使得序列长度增长,需要解决长期记忆的问题,换句话说就是要解决梯度弥散的问题。而近些年被广泛使用的一些精心设计的 RNN 单元,例如 LSTM,GRU,给出了解决这个问题的方向。
Challenges
基于字的翻译有两个比较大问题 1)是否“字”的组合能都映射出整句的意思?2)基于字处理使得状态空间指数级增长,是否能生成出一长串有含义的字的序列?由于 encoder 端只存在第一个问题,而 decoder 端两个问题都存在,因此本文只考虑了在 decoder 端基于“字”的翻译,encoder 端还采用 subword (BPE)。
Model
本文的基本模型结构沿用了论文“NEURAL MACHINE TRANSLATION
BY JOINTLY LEARNING TO ALIGN AND TRANSLATE”中经典的模型结构,如下图所示。
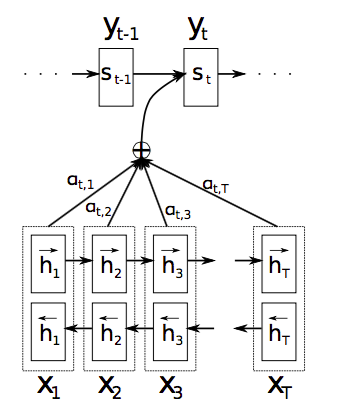
不同之处是,在 decoder 部分的(...,y_t-1,y_t)对应字,而非词。同时为了适应字的处理,作者采用了两种 RNN 单元,一种是熟悉的 GRU,另一种是本文新提出的“Bi-scale”,如下图所示:
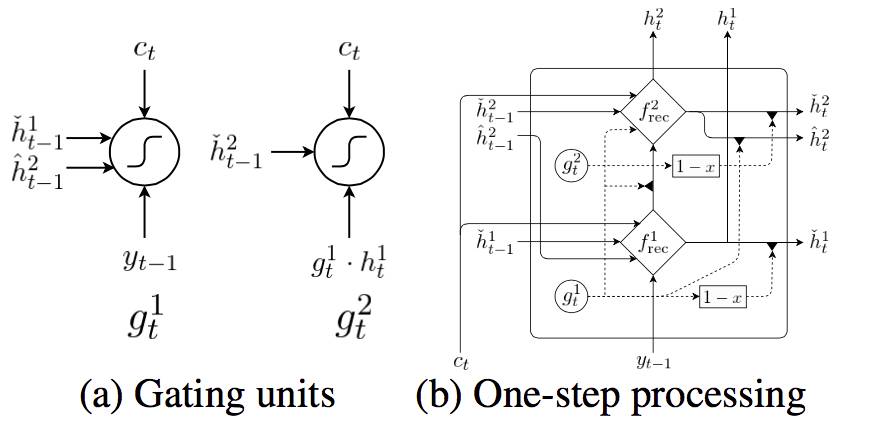
这是一个 2 层的结构,分别为“fast layer”和“slow layer”。具体的计算过程如下所示,其中上标为‘1’代表“fast layer”;上标为‘2’代表“slower layer”。之所以这样命名是因为,fast layer 直接接收 y_t 的信息,slow layer 接收来自 fast layer 的信息。从最后一个公式可以看出,当且仅当 fast layer 完成了信息处理将要重置的时候(g_t^1 ~= 1),slow layer 才能得到 fast layer 传来的信息,也就是其要比 fast layer 接收信息慢。我个人认为,这正代表了“字”和“词”之间的关系。
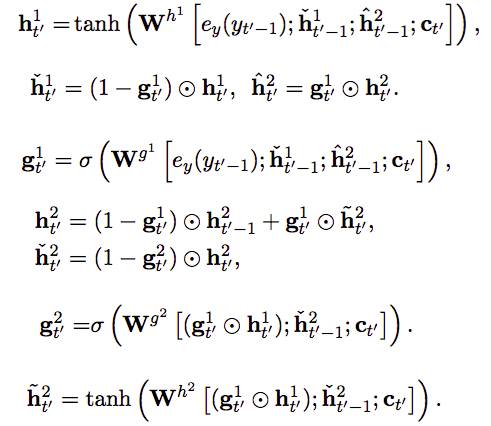
Experiments
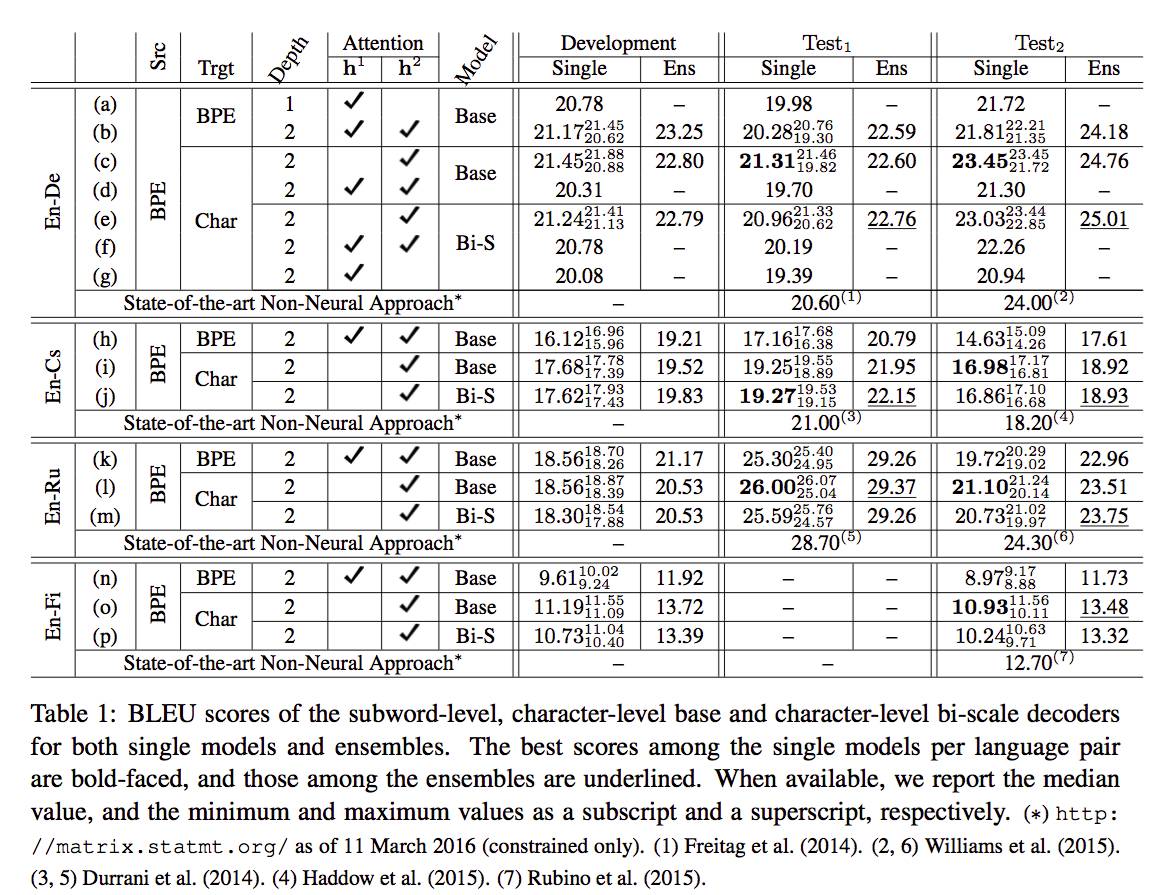
文章中做了比较详尽的实验,如上图所示。对比了 subword-level 和 character-level 的翻译效果,发现 character-level 的翻译基本上能超越或者可比 subword-level 的翻译。对比了利用 fast layer(h^1)和 slow layer(h^2)在 alignmemt model 中的效果,发现 slow layer 更胜一筹(在 Base model,也就是 GRU 的 model 下,slow layer 是指模型的第二层)。这个比较好理解,因为 slow layer 捕捉了词的信息,而源端就是词。对比 GRU 和 Bi-scale,看起来效果差别不大。还有 sigle model 和 ensemble 的对别,这里就不赘述了。
资源
本文中用到的数据代码资源均可从以下链接找到:
https://github.com/nyu-dl/dl4mt-cdec
相关工作
Character-level document classification:
Yijun Xiao and Kyunghyun Cho. 2016. Efficient character-level document classification by combin- ing convolution and recurrent layers. arXiv preprint arXiv:1602.00367.
Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text clas- sification. In Advances in Neural Information Pro- cessing Systems, pages 649–657.
Character-level RNN-LM:
Ilya Sutskever, James Martens, and Geoffrey E Hin- ton. 2011. Generating text with recurrent neural networks. In Proceedings of the 28th International Conference on Machine Learning (ICML’11), pages 1017–1024.
Character-level NMT:
https://github.com/swordyork/dcnmt
简评
本篇文章启发性很大,一定程度上证实了字符级翻译的可能性。文章中花了很大的篇幅说明字符级翻译的必要和好处,也是比较有说服力的。但是文章最终只验证了 decoder 端的字符级翻译,而没有做整套的字符级翻译。可能是因为文章只是想先验证可能性,还未来得及继续深入。
完成人信息
张诗悦
,硕士在读
[email protected]
zhangshiyue.github.io
__________________
阅读小组参与细则
1. 参与者需具备当期 topic(本期为
机器翻译
)的研究背景,并在活动开始前完成论文阅读。
2. 扫描下方二维码添加主持人微信,注明
“reading group”
,本期阅读计划期限为 3 月 31 日-4 月 3 日,报名截止时间为 4 月 2 日(本周日) 20:00。
3. 待通过验证后,向主持人提交当期测试题答案。
本期测试题如下:
本文为解决字符级别的翻译,使用了一种特殊设计的RNN单元,是什么?有什么特点?

关于PaperWeekly
PaperWeekly 是一个分享知识和交流学问的学术组织,关注的领域是 NLP 的各个方向。如果你也经常读 paper,喜欢分享知识,喜欢和大家一起讨论和学习的话,请速速来加入我们吧。
关注微博: @PaperWeekly
微信交流群: 后台回复“加群”





