为什么会有足球流氓,警察和社会学家的观点完全不同,最靠谱的方式或许是借用数学进行分析。
文|孙鑫伟
提到足球流氓,人们首先会想到英国,当然,由于俄罗斯组建了世界第一支足球流氓国家队,谈到这个话题也会让人们想起俄罗斯。

▍英国西汉姆球迷和切尔西球迷之间冲突的新闻
问题是——
该领域权威之一大卫·V.·坎特将之描述为“包括多种从简单到复杂的暴力行为”;另一个权威埃里克·邓宁则称之为“与足球相关的,各式各样的引起冲突的行为”——看上去像是废话。当代学者甚至会回避它的定义。
因为它既可以是球迷与球员之间的,也可以是球迷之间的,既可以是场内的也可以是场外的,有口角、推搡,也有造成 1 至 5 人受伤的使用武器的斗殴,也有类似 1985 年海瑟尔惨案这样的悲剧(双方球迷冲突导致看台坍塌,死 39 人,伤 600 多人)。


当我们谈足球流氓时,我们谈到的现象其实会涉及到多个变量:行为的危害程度、发生地点、组织形式、是否会造成伤害以及伤害程度,是否会构成犯罪、犯罪等级、发生原因、涉及对象等等。每个变量都会有多种可能的取值。
所以,谨慎而靠谱的描述方式是看上述变量各种取值所占的比率。比如,在 The Nature and Extent of Football Hooliganism in England and Wales(《英格兰及威尔士的足球流氓程度及背后的本质》)一文中,作者便分析了包括 NCIS(国家犯罪情报局)1999 年至 2003 年四个赛季的数据,发现如下现象:
地点:球场内的足球流氓现象并不比市中心公共场合更多;
时间:比赛前比赛中和比赛后三个时段中,比赛后最危险;
受伤程度:大部分冲突都不会造成受伤,有时受伤警察会远多于球迷,因为球迷很难被统计;
武器:排列前两位的武器是瓶子和石头,实际上它们造成伤害很少,因为投中太难了。
研究者认为,足球流氓是世界性问题,之所以英国显得格外显眼,除了它本身确实严重之外,媒体夸大也功不可没。
足球流氓现象伴随着英国足球历史,只是程度及方式不同,前期更多体现在球迷对比赛官员及对方球员的暴力。1960 年代开始,才逐渐转为球迷间的斗殴,且愈演愈烈。
这与当时英国工人阶级家庭的年轻一代有关。约翰·克拉克认为,这一代人更少受父母管制,非常容易形成自己的亚文化。从最早的泰迪男孩(Teddy Boy)到摩斯族(Mods)、摇滚派(Rockers),再到后来的光头党(Skinheads)。

泰迪男孩:1950 年代出现在伦敦,随后风靡全国。他们身着工人阶级流行的爱德华王朝七世的穿衣风格,双排纽扣披肩夹克,白色或灰色领带,紧身裤,带扣的鞋子。

摩斯族和摇滚派是两种对立的流行于 1960-1970 年代的英国亚文化。前者(下图左)崇尚时尚与音乐,骑“速可达”摩托车,梳法式犀利短发,配意大利式西装、七分西裤、手工制皮鞋。后者(下图右)重点在于骑摩托车上,喜欢黑色皮夹克、摩托车皮靴,留着“将头发高高梳起、刘海向后留、后脑勺部分用发胶贴上”的庞毕度发型。

1960 年代末期,光头党文化开始流行,他们留短发,穿宾舍曼衬衫和背带,普雷斯特裤子以及马汀大夫的靴子,强调男子气概、侵略性、强健的身体。

这些亚文化群体都来自底层工人阶级,“情绪激动、动辄用武力解决问题”,他们通常会位于场内最廉价的票区。发生冲突时,往往各司其职,有负责领导唱歌的,有负责与对方球迷叫骂的,还有旅途的组织者,当然最主要的,还是喝醉酒的打手。伴随着这些亚文化群体规模的扩大,场内的冲突和火药味越来越浓。
1966 年英国举办世界杯前后,媒体开始关注“足球流氓”。有学者称,尽管当时冲突频率并没有什么变化,但媒体报道和电视普及,将足球流氓现象放大,让年轻人觉得球场是释放暴力的好去处。

早期的解决办法除了增加警卫,就是用栅栏分隔主客场球迷,并用专车接送客场球迷。然而,这反而有副作用——两方球迷被强行分开,增加了他们的认同感以及对群体外的敌对感。
而警方制定规则越多,流氓团体越会想法逃脱警方管控。这种博弈让警察管得越来越宽,规则越定越细,惩罚手段越来越严厉;另一方面也滋生了几个组织精密的超级流氓团体。
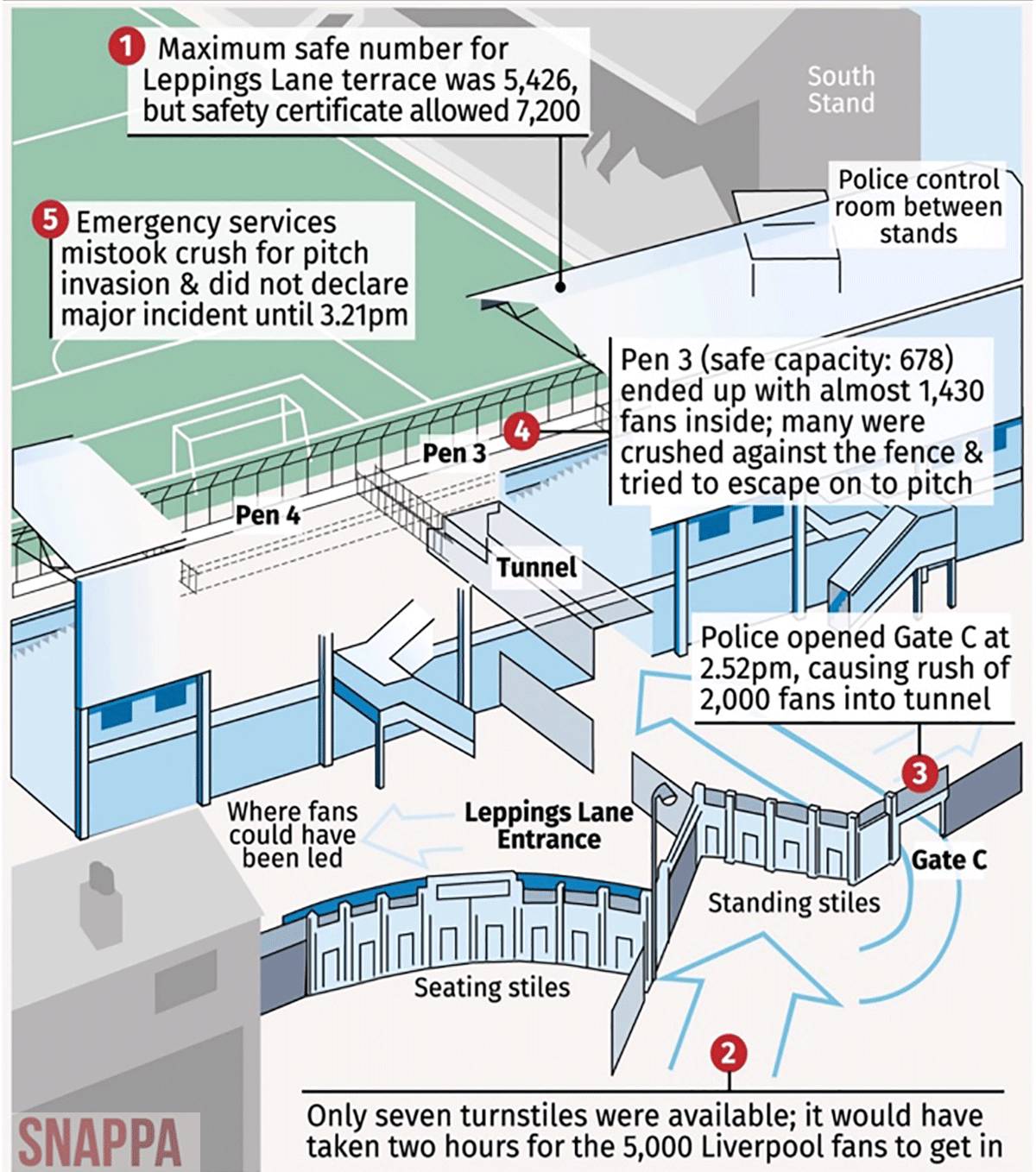
最能体现这种副作用的事件,就是 1989 年 4 月 15 日的希尔斯堡惨案——在希尔斯堡球场的利物浦和诺丁汉队比赛中,由于栅栏过高,警察疏导不利,造成了严重的踩踏事故,致使 96 人死亡,700 多人受伤。

▍希尔斯堡球场
英国上诉法院法官彼得·泰勒表示,“希尔斯堡惨案的发生,正是由于这些越来越高,上面还长满刺的遍布球场内外的栅栏,它们让大部分观众在预感到危险那一刻无处逃脱”。下图右边的 Pen 3 区域,最多能承载 678 个人,可在那时有 1400 人左右想挣脱栅栏,往赛场方向逃脱。大部分伤亡人员都在该区域。
尔后,英国足球俱乐部又推出“会员制度”,旨在筛出不想看球的那部分球迷。米尔沃尔俱乐部甚至只对主场球迷开放。撒切尔还在 1989 年推出“足球观众法案”,它试图制定“卡片制度”,球迷需要凭借包括姓名、照片卡片才能到客场看球。
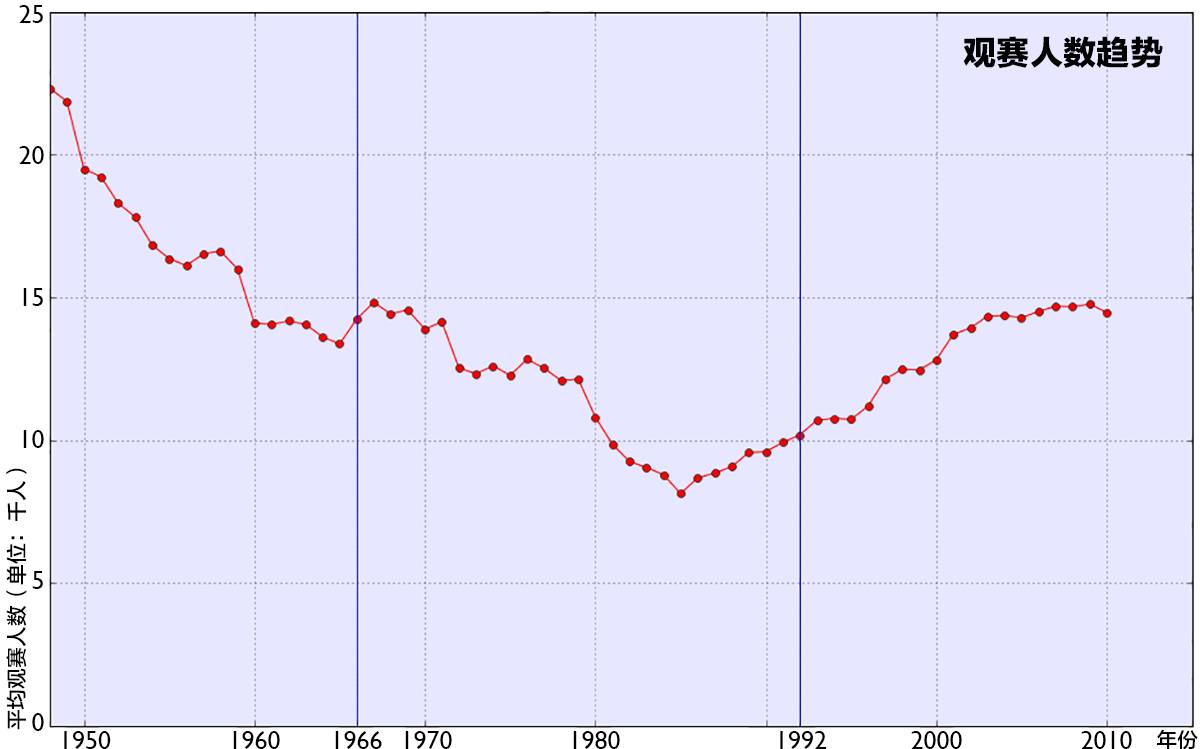
这些措施给那些真心想看球的球迷带来了麻烦,并随之影响了俱乐部的收益。从 1950 年代开始到 1990 年代前,到场观赛人数一直稳步下降,除了 1966 年在本土举办的世界杯有小幅的上升。
实际上,加强警力增加了场内球迷的紧张情绪,认为“冲突”随时有可能发生。克利福德·斯托特精心组织了一个多人参与的实验,对比分析了 2000 年欧洲杯和 2004 年欧洲杯的警力、球迷情绪和他们之间的互动。
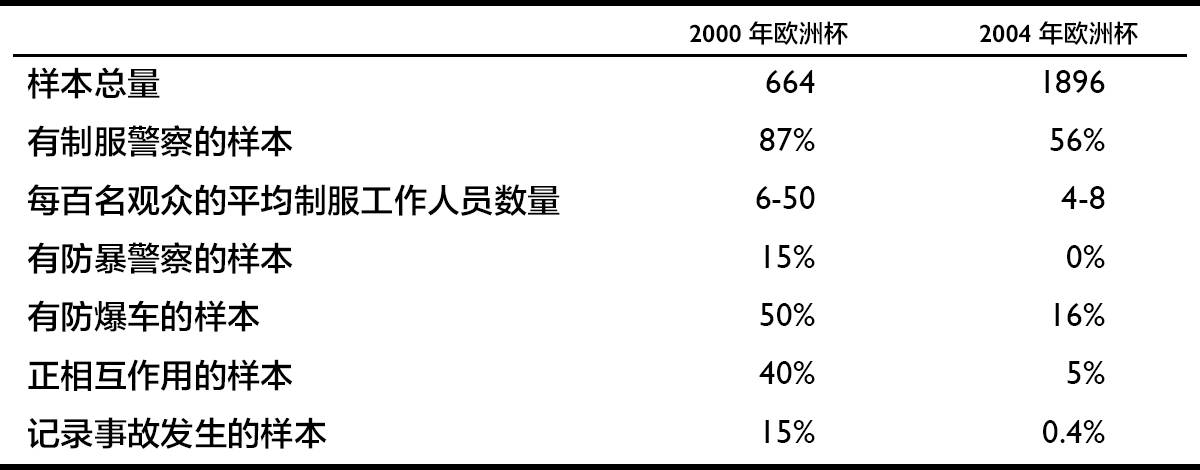
▍2000 年和 2004 年欧洲杯警卫部署的观测数据对比
研究发现,2004 年欧洲杯比 2000 年欧洲杯的警卫密度要小得多,但事故率却是前者的 1/60。作者发现“本方球迷内认同感 × 时间”变量对于“球迷与警察的亲切感”呈显著正相关(p-value<0.001,值得一提的是,尽管 p-value 被认为并不能反映选变量的错误率,另外两个决定错误率的量 prevalence 和 power 都不确定,但它是与错误率成正相关的,只是一般的标准 0.05 会带来较大的错误率而已,p-value 越低,其他量不变情况下,错误率也越低,因此这里 p-value<0.001 可以用作参照)。
1989 年,泰勒出具了一份研究希尔斯堡惨案的报告,报告提到在球场内用座位来代替台阶,它照顾了观众的舒适度并有效解决扎堆现象;在安全问题方面,通过安装闭路电视监控设施来预防、取消 2.2 米以上的栅栏;从俱乐部收益方面,停止使用会员制度。

▍泰勒法官关于“希尔斯堡惨案”最终报告的第二章部分目录
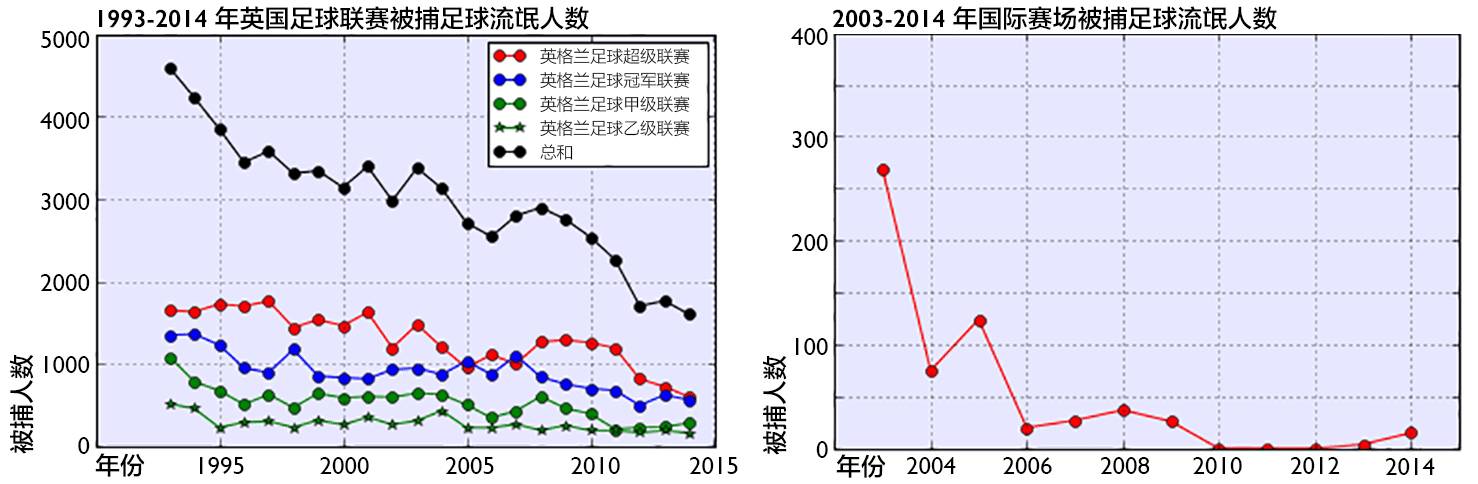
为提高那些顶尖俱乐部的收视率和收入,原来的甲组俱乐部于 1992 年 5 月 27 日组建英超联盟有限公司——英超联赛被正式引入。球场座位席、草坪等硬件设施以及监控系统、安全立法等软件方面的改善使得上座率稳步上升,而每年 在联赛及国际赛场上被逮捕的足球流氓人数都在这之后平稳下降。
“青年人的亚文化”这一因素远不能解释清楚英国的足球流氓现象,它只是促成媒体报道的导火索,让英国足球闻名于世。
学术界对官方的解释并不买账,但又各执一词。后者把原因归结为酒精和球场上的暴力冲突。但是,没有数据表明喝醉的球迷都会闹事或闹事的球迷都是由于酒精造成的。同样,场外的冲突、看台上的骚动也不都是发生在球场上的暴力之后。
早期影响力比较大的是泰勒。他指出早期的足球俱乐部是从工人阶级内产生的,从球员到经理。那时,经理和工人阶级关系更紧密,属于相同的亚文化圈——通过比赛来展示他们的求生欲望和阳刚之气,甚至,后者还可以十分“民主”地为俱乐部提意见,参与俱乐部的管理。
随着球员和老板的收入、社会地位越来越高,他们逐渐和观众们产生了隔阂。这些工人阶级观众失去了认同感和参与感,试图通过以暴力方式来表达自己的不满。
但是,没有证据表明早期那些观众可以“民主”地参与俱乐部建设,也没有这些观众对此表达不满的有参考价值的佐证——R.·卡罗尔在《足球流氓在英国》一书中指出,大多数年轻人根本不了解这些背景,他们看球只是感兴趣或追星。
另一种解释非常干脆利索:足球流氓群体有天生超出正常人的暴力基因。简言之,这些人就喜欢打架,要么受酒精或毒品影响,要么患有精神疾病,像动物一样不能控制自己行为。所以,唯一的解决方案就是警卫越多越严厉。只是这种观念没有任何数据支撑。


巴黎的阿纳斯塔西娅·苏卡拉(Anastassia Tsoukala)教授长期研究足球流氓现象,她认为谈论足球流氓不能脱离社会背景,而是应该把“犯罪率”、“失业率”等社会问题一起放到大的社会环境中讨论。研究者 1980 年代就发现,足球闹事者 80.1%来自底层工人阶级和失业人员。

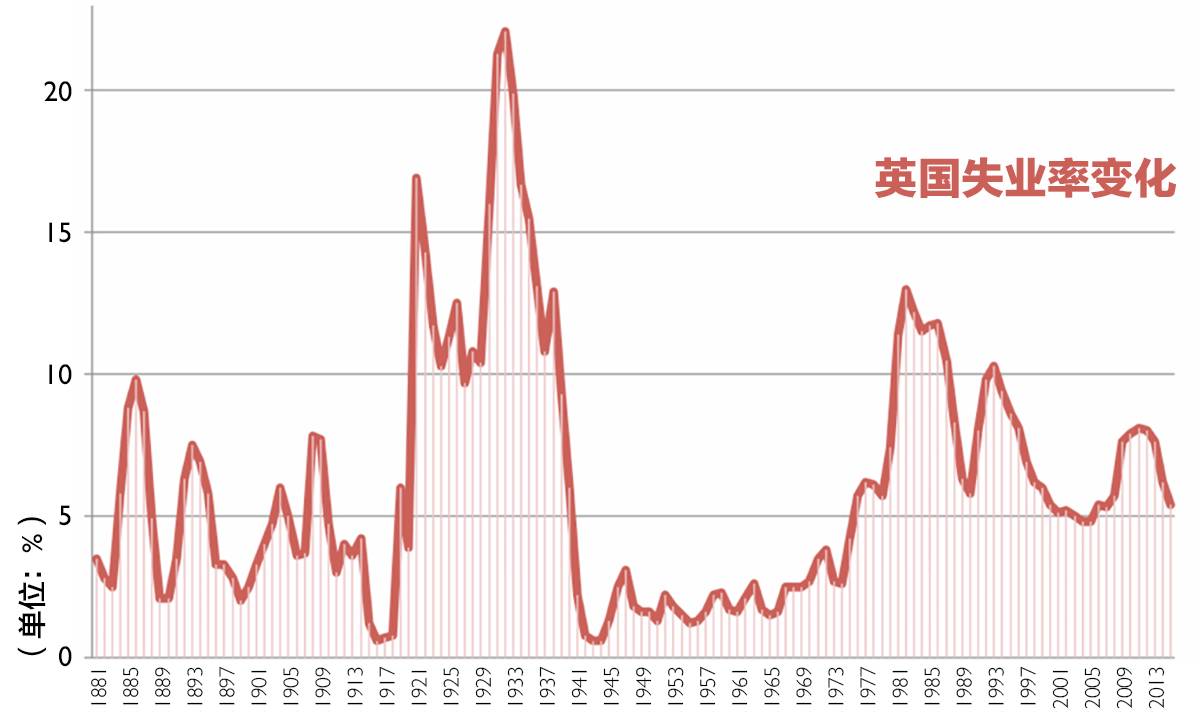
除了这些低收入阶层之外,“失业率”这一因素也被学者认为是关键因素。从下面英国失业率的曲线中可以看出,1980 年的失业率在此前后 20 年达到顶峰。
但学者邓宁指出,失业率和足球流氓并不能完全建立联系。比如 1930 年代失业率最高的时候,与足球暴力相关的报道是最少的。同样,在 1960 年代足球流氓开始猖狂时,失业率也很低。但报道的足球流氓数字并不一定能够反映真实情况。
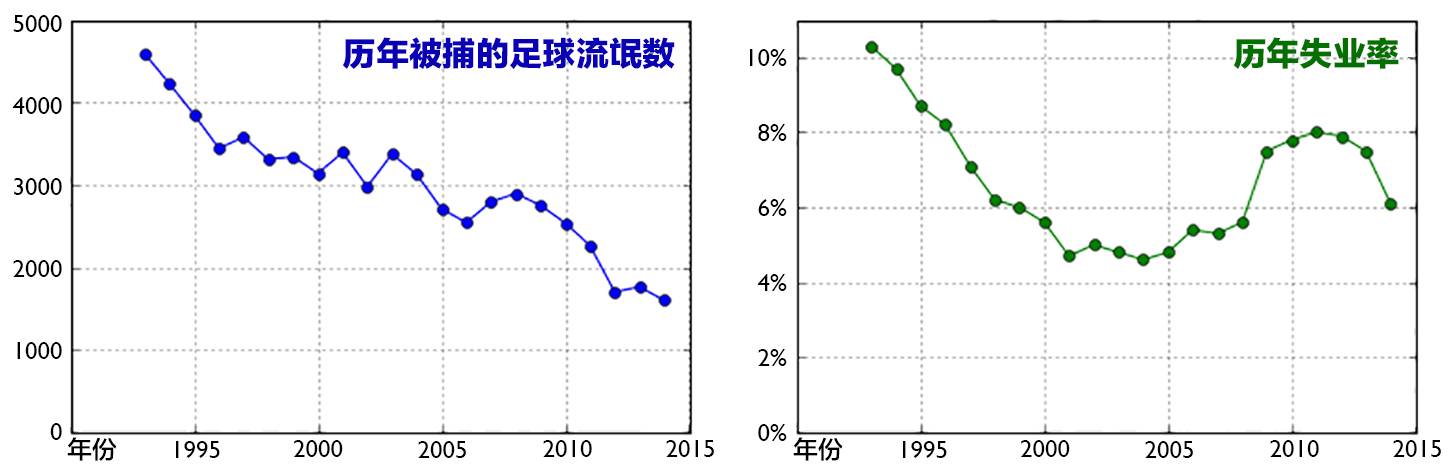
我们通过横向和纵向比较两个方面来看失业率与英国足球流氓的关系。首先是随时间横向地来看英国每年的失业率和被逮捕的足球流氓数的关系。由于后者 1992 年后官方才有统计数据,因此我们看 1993-2014 年的情况。下图可以看出,两者并没有十分明显的相关性(相关系数为 0.29)。
下面我们纵向地来比较。为此,我们查询了 2004-2013 年这 10 年英超的数据,并计算了每一赛季不同俱乐部足球流氓逮捕人数与当地失业率的皮尔森相关系数。(有超过 1 家俱乐部的城市,取平均数)

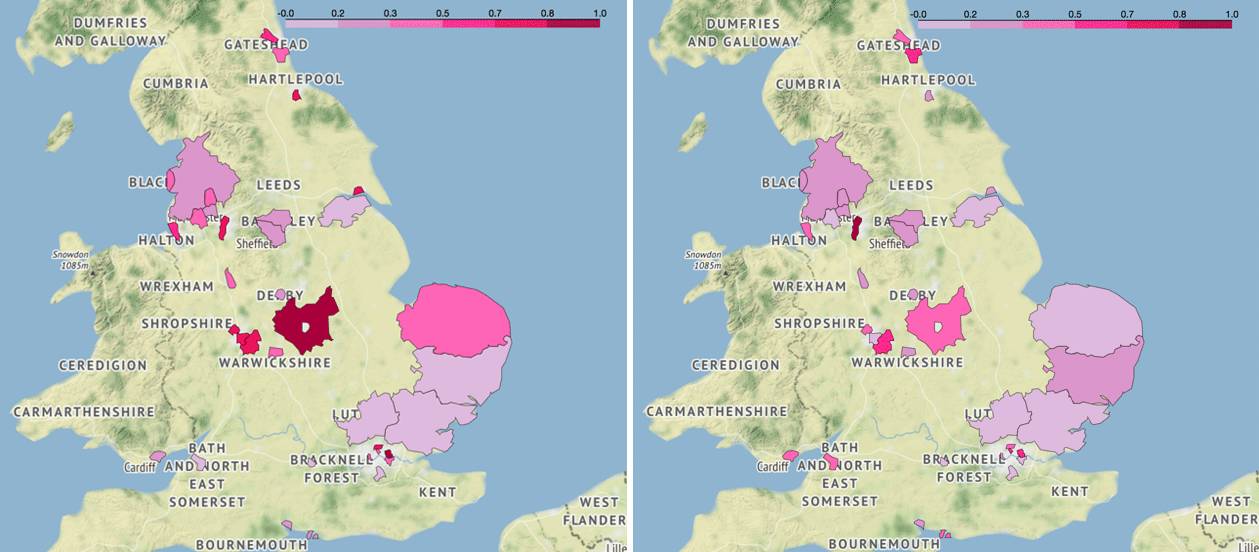
由结果可以看出,平均来看,不同地区的失业率和当地足球流氓活动有一定相关性,但比较弱且波动(标准差)较大,最高的是 07-08 赛季,可以达到 0.652,最低的是 08-09 赛季,仅为 0.103。我们分别画出这两者失业率与足球流氓逮捕人数的分布图,从颜色上看 07-08 赛季的两张图呈一定强度的相关性,而后者几乎看不出来。
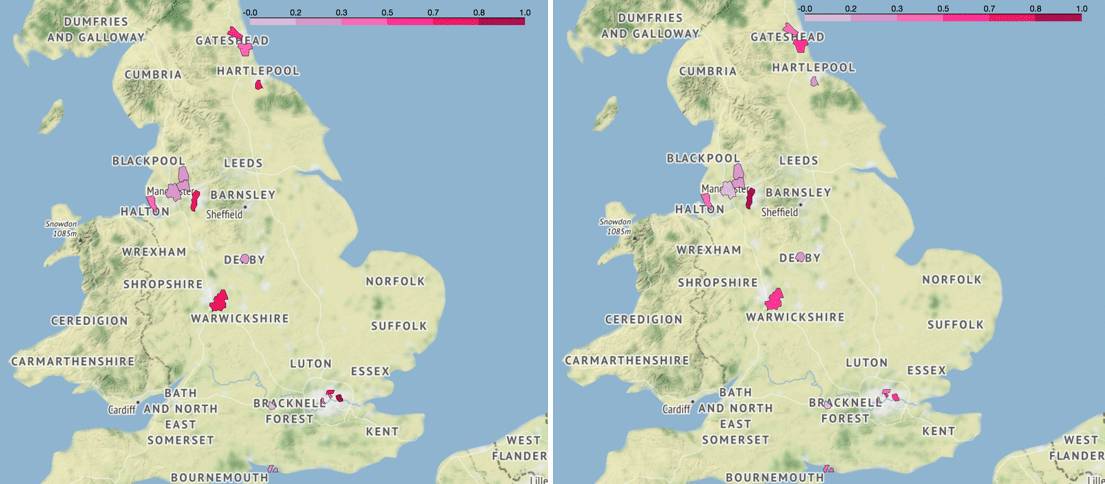
▍左:07-08 赛季年失业率分布图(英超),右:07-08 赛季足球流氓逮捕人数分布图(英超)
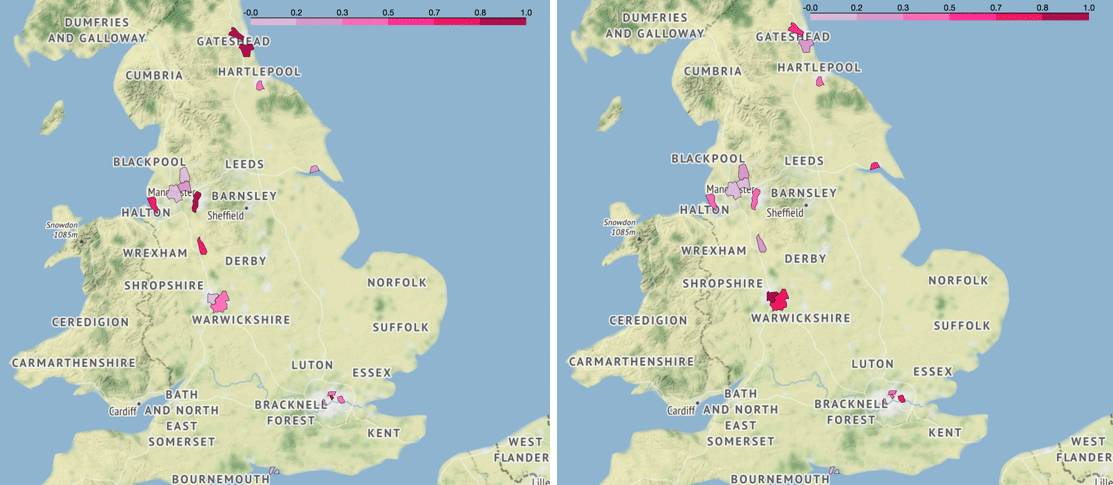
▍左:08-09 赛季年失业率分布图(英超),右:08-09 赛季足球流氓逮捕人数分布图(英超)
我们还可以计算英超、英冠,甚至是前 n(n≥3) 联赛。但这样会引入联赛级别不同而带来的不公正性,由于英超最受关注,因此足球流氓数很有可能要比低级别联赛更高。
从 2007-2008 年的例子就可以说明这一点,如果只是英超的话,相关性为 0.652,引入英冠联赛后降为 0.554,算上英甲联赛后骤降为 0.242。
▍左:07-08 赛季年失业率分布图(英超、英冠),右:07-08 赛季足球流氓逮捕人数分布图(英超、英冠)
同样,我们也可以画出引入这两级联赛后的对比图。引入英冠后(上图),依然能看出一定的相关性;而英甲联赛算进来后相关性就不是很明显了(下图)。显然,失业率与足球流氓的关联性并不像社会学家想象得那么强。
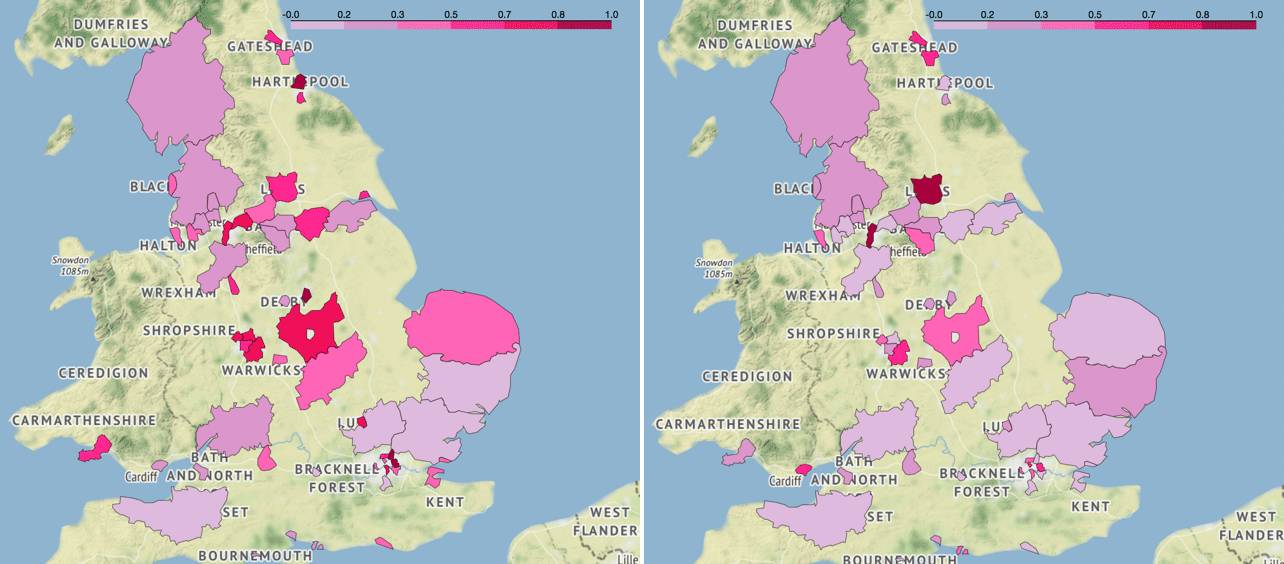
▍左:07-08 赛季年失业率分布图(英超、英冠、英甲),右:07-08 赛季足球流氓逮捕人数分布图(英超、英冠、英甲)
看来,研究足球流氓现象与社会关系还需要加入更多的指标。现有文献对这一部分的量化研究并不多,因此我们尝试自己来做一些研究。
为分析哪个变量或哪几个变量更影响足球流氓的严重程度,我们决定以每个俱乐部,每个赛季足球流氓逮捕人数为响应变量“y”,并与该俱乐部或所在城市有关的各种指标(解释变量)配套起来分析。
这些解释变量包括四大块,分别是联赛相关因素、人口相关因素、经济相关因素以及社会相关因素。联赛相关因素包括该赛季这个俱乐部的排名,联赛等级,平均观众人数(Attendence),上赛季是否升降级等。
人口相关因素包括该城市每年的人口(Population),男性人口比例,16-64 岁人口比例等。经济相关因素包括人均总增加值(GVA),人均总增加值年增长率(Growth rate of GVA),不同类型工作人口比率,经济不活跃比率(Economic inactivity)等。
社会因素包含的因素较多,比如失业率,失业率年增长率,犯罪率,房价中位数,房价年增长率,消费者物价指数(CPI)年增长率等等。这四大因素合在一起共 29 个指标。
我们根据英国国家统计局、“欧洲足球统计”以及各支球队情况提取出了 21 家俱乐部在 2004-2013 年这 10 年间上述指标的数据。
为更清楚地认识每个指标对响应变量“y”的影响,在对数据进行 MinMax 归一化处理之后,我们画出了部分指标与 y 的散点图,以及线性关系。
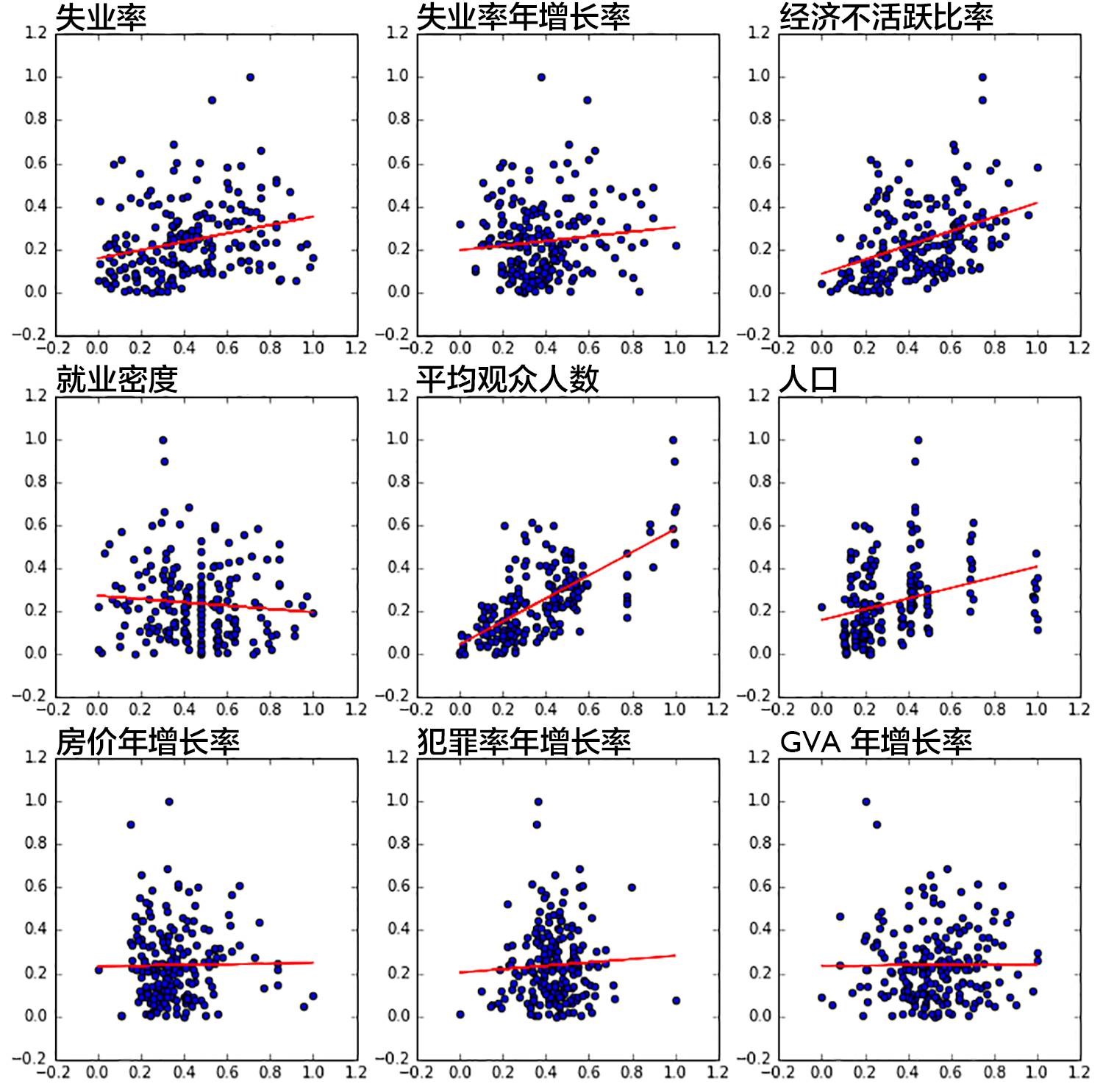
▍部分指标与 y 的散点图及线性关系
不难看出,即使是拥有最强线性关系的“平均观众人数”指标也无法对 y 拟合地很好。因此模型并不是由单一指标构成的,也就是说,y 一定是受多变量影响的。
因此,我们假定模型是由多变量决定的线性模型:
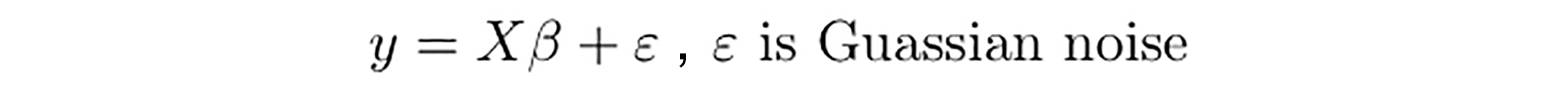
其中 y 是目标变量,X 是上面 29 个解释变量组成的矩阵,每一列代表一个指标:
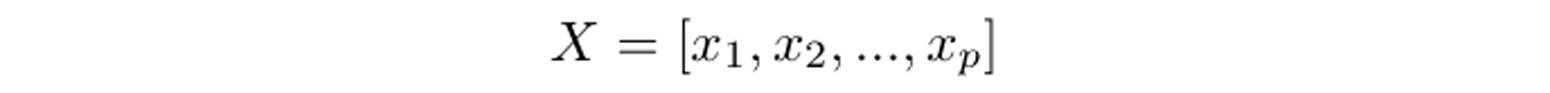
同时,我们假设:
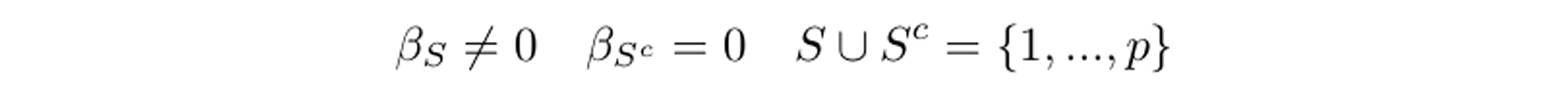
也就是说,只有下标集合为 S 的解释变量对应的系数是非零的,这说明,这些解释变量就是我们需要的变量(其他变量系数为 0,因此没有影响)。问题转化为如何正确地选出下标集合为 S 的变量,我们尝试用一些统计模型来解决这一问题。
LASSO 是 1996 年由罗伯特·提布施瓦尼提出来的统计模型,它能够得到稀疏(大部分系数都是 0)的解,并在 2006 年由 Peng Zhao,Bin Yu 证明出当满足一定条件的时候,LASSO 可以具有“model selection consistency”,即正确地挑选出下标集合为 S 的解释变量。
在写成拉格朗日形式之后,LASSO 模型可以转化为解如下的优化问题:

其中:
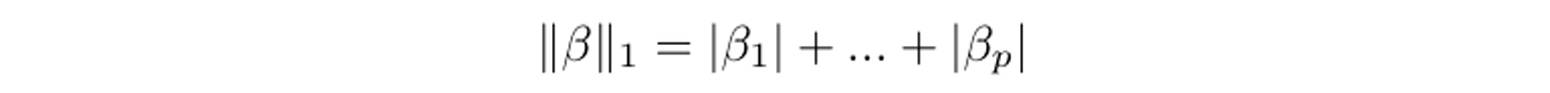
我们可以看到,当 λ=+∞ 时,β=0,也就是说,所有的变量都没有被选出来。而当 λ=0 的时候,所有的变量以 100%的概率被选出来。两种情况都没有什么意义,因此我们要在 (0, +∞) 内选择合适的 λ 值,从而挑选出我们需要的变量。
我们可以观察到,当 λ 值从正无穷减少的时候,会倾向于有越来越多的变量被选出来,模型的拟合能力越来越强,这会使得模型在数据上拟合地越来越准确,这有一定的好处,因为变量太少则拟合力度不够(Underfiiting),但过于精确则会导致过拟合(Overfitting)的问题。比如下面左图,蓝色的直线就没有能够很好地拟合黄色的点,而最右边图的蓝色曲线又拟合得太过。
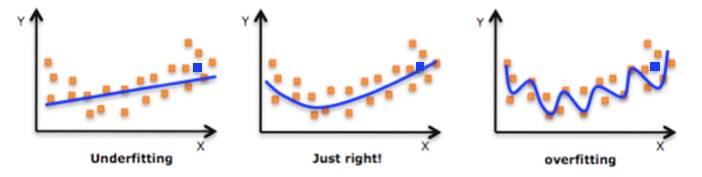
▍因此在出现新的数据时(上面三幅图的蓝点),左边的直线及右边的曲线会分别由于欠拟合和过拟合的原因,距离蓝点有一定距离
为解决这一问题,我们引入了 BIC 这个概念,它是模型选择的衡量指标,BIC 值越小,代表这个指标认为欠拟合和过拟合之间平衡的越好。
将数据代入 LASSO 这一模型当中,我们画出了 BIC 关于 1/λ 的曲线图:
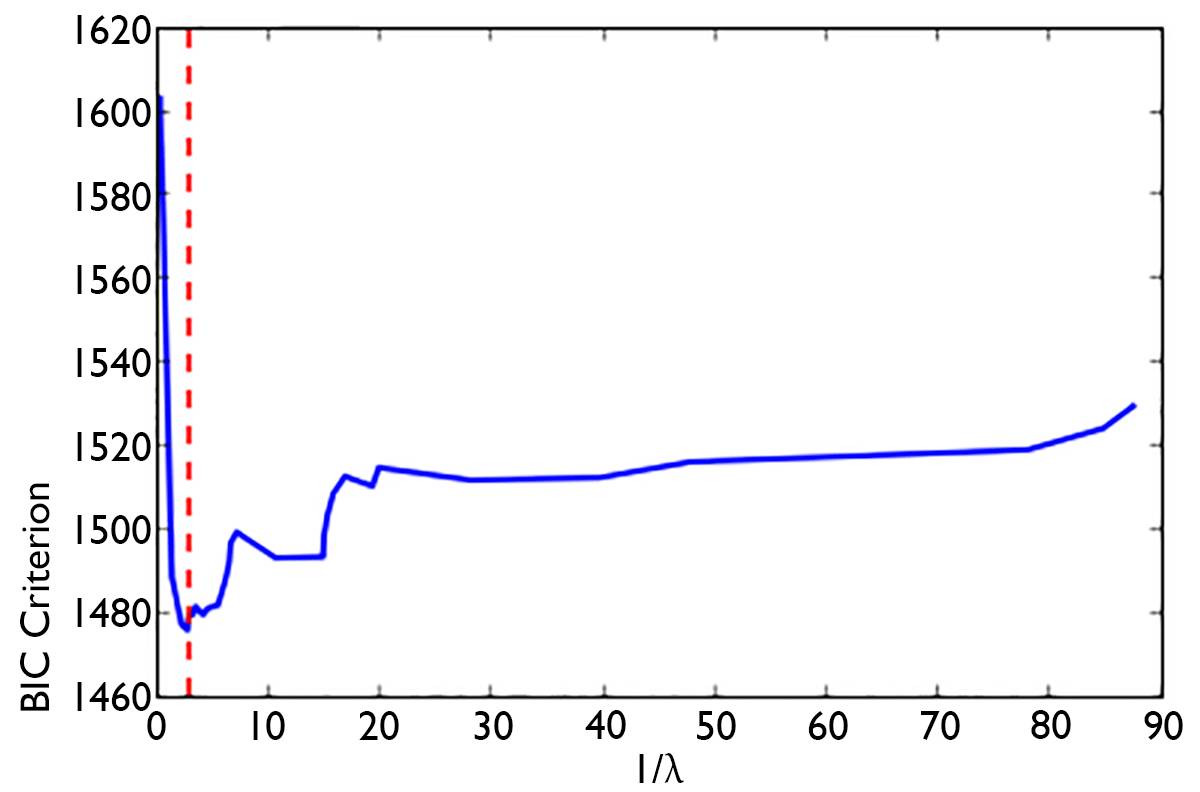
由图可以看出,在红色虚线对应的位置上,BIC 值最小,认为选择的模型最优。这时,选出的变量是“平均观众人数”、“人口”和“失业率年增长率”。
除了“人口”这一比较显然的因素之外,“平均观众人数”可以反映球迷对俱乐部的关注程度,它的系数是正的,证明模型认为它与目标变量 y 呈正相关,球迷的关注度越高,足球流氓现象就越有可能滋生。
同样,“失业率年增长率”也被认为和 y 呈正的相关关系,因此相比较“失业率”,更有影响的因素是“失业率年增长率”,后者越高,越容易引发社会的不满,社会问题也会越来越多,包括足球流氓现象。
事实上,我们还可以做得更好。
在被今年 NIPS(神经信息处理系统大会)接受的论文 Split LBI: An Iterative Regularization Path with Structural Sparsity(《Split LBI:一种可以给出结构稀疏路径解的迭代算法》)中,作者提出基于 Variable Splitting 和 LBI solution path 的迭代算法 Split LBI,并从理论和实验上证明,相比较于 LASSO,它可以得到更好的模型选择结果。理论部分,感兴趣的读者可以去读论文,这里不再赘述。
对于实验部分,作者采用“Area under the Curve of ROC(AUC)”来作为变量选择的评价指标。我们结合 ROC 曲线一起来解释。纵轴 TPR 表示选对变量的数量与真实变量数量的比率,而横轴 FPR 表示选错变量的数量占所有非真实变量数量的比率。
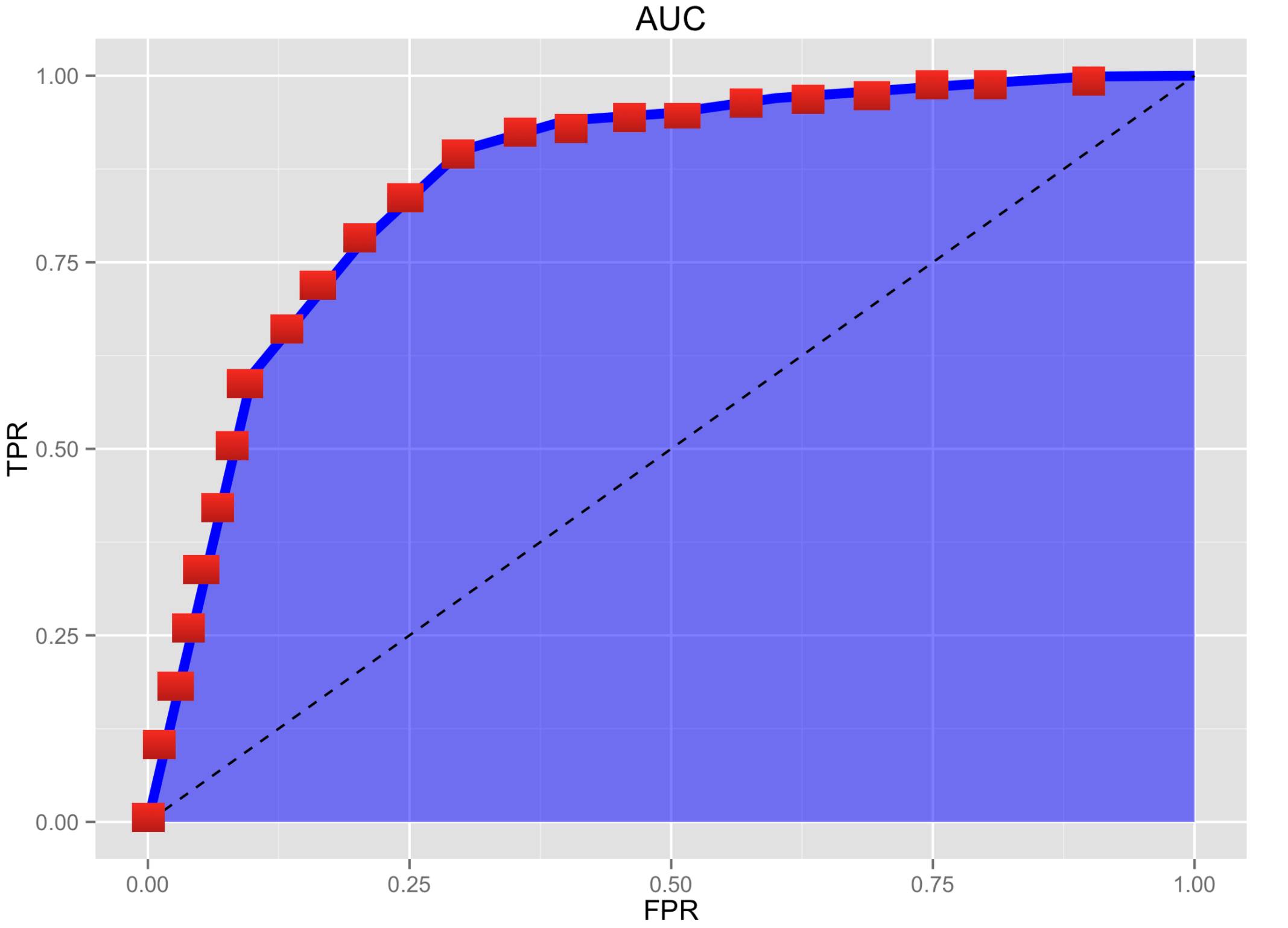
每一次迭代,算法都会选出一些变量,我们可以根据这些选出来的变量以及真实的变量集合 S,来计算出 TPR 和 FPR,上图中的红点代表每次迭代的(TPR, FPR)。把这些红点连接起来,就是 ROC 曲线,曲线下面的蓝色部分的面积,就是 AUC。可以看出,AUC 的取值范围是 0~1,值越大,代表模型选择越好。
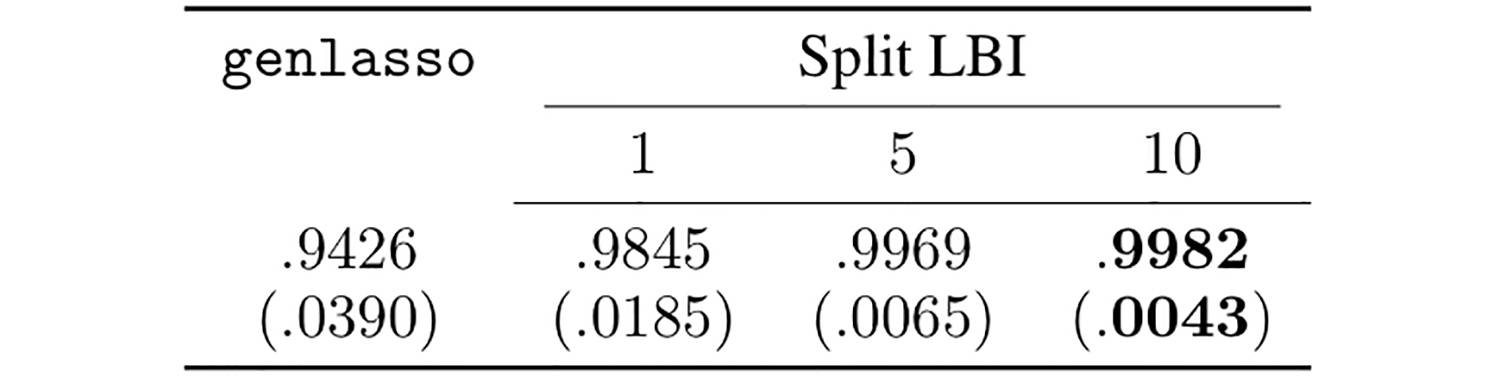
上面的表格列出了 LASSO 与 Split LBI 的 100 次模拟的 AUC 平均值及标准差。左边的 genlasso 就是 LASSO(genlasso 的矩阵 D=I 时),右边的 Split LBI 最好的时候可以达到 0.9982,要好于 genlasso 的 0.9426。
相比较用于解 LASSO 的 LARS 算法,Split LBI 的迭代算法形式上更简单,我们还可以将选出的变量关于时间进行可视化。如下图:
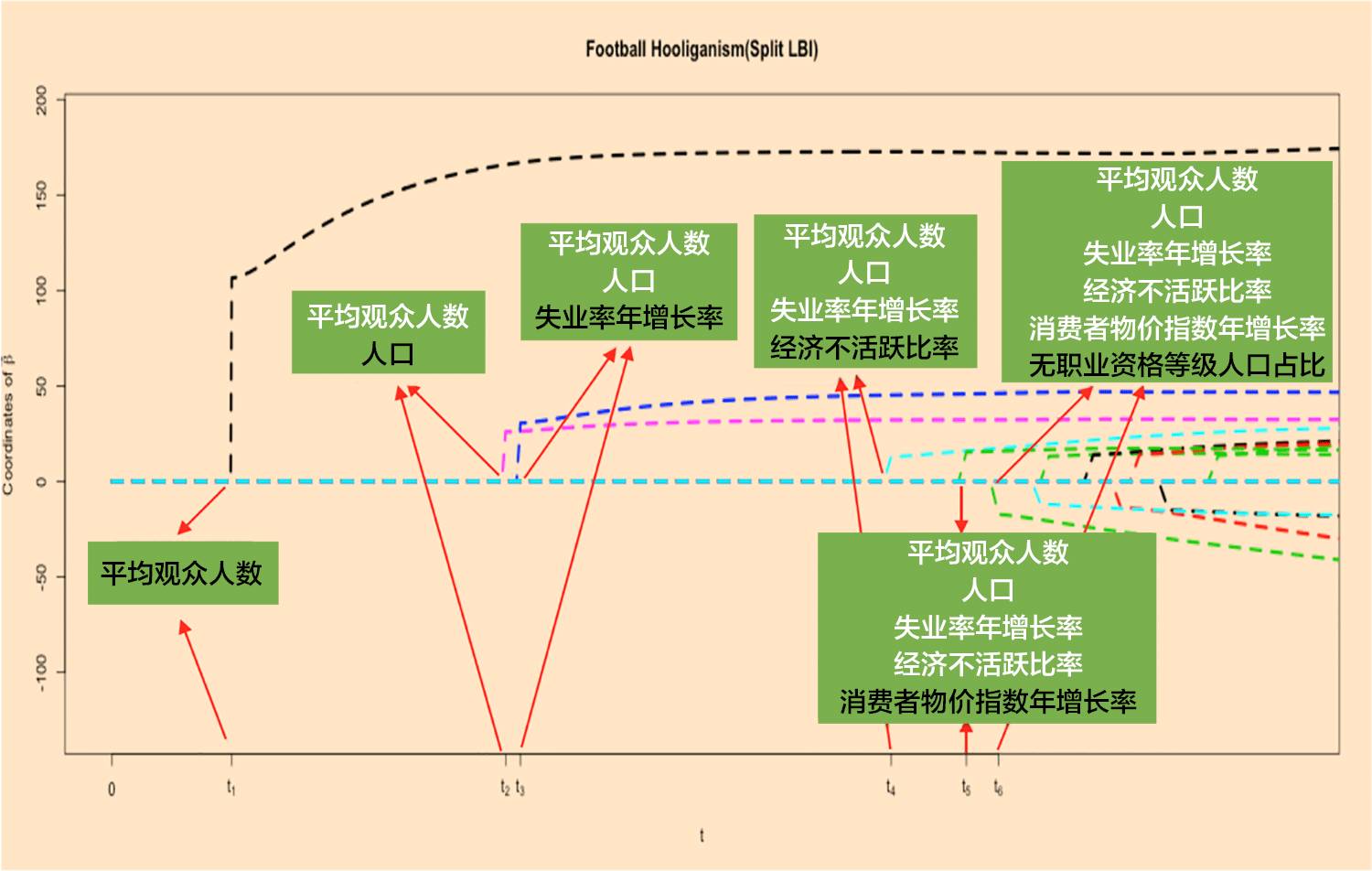
▍横坐标代表时间,纵坐标表示变量的值,每条曲线表示该变量随着时间变化的值。绿色方块记录着变量的名称。红色箭头表示在相应的时间点上,指向的变量被算法选出来,即认为非零。
在算法刚开始时,是没有变量选进来的。而后,“平均观众人数”这个变量被选到模型中来,紧接着是“人口”,当“失业率年增长率”被选进来之后,模型就是上面利用 BIC 最小时得到的模型。后面“经济不活跃比率”、“消费者物价指数年增长率”,“无职业资格等级人口占比”被陆续选了进来。
在这里面,“经济不活跃比率”表示非工作人群占人口比例,非工作人群包括学生,老人等群体。这些群体所占比例越大,社会压力也就相对越大。同样的还有“消费者物价指数年增长率”,也与社会压力呈正相关。
值得一提的是,第六个选出的变量“无职业资格等级人口占比”(Rate of No qualification),指的是没有 NVQ 等级的人占人口的比例。NVQ 是英国的国家职业资格证书制度,用于衡量执业人员职业能力,包括知识水平,运用能力,操作能力等。它共分为 5 个等级,级别越高代表职业能力越强。
而模型认为“无职业资格等级人口占比”是与 y 是呈负相关的,这一方面说明近些年,这些“职业素养”相对低的人群不一定再是闹事人员的主导因素,因为它的比例越低,表明具有职业资格的人的比例越高。
需要说明的是,解释变量间都是有相关关系的,因此也不好针对单一因素来解释。此外,算法跑到了这里,选出变量的解释性相对之前就变弱了一些,随着迭代的进行,算法还会选出认为那些更不重要的,解释性更弱的变量。将这一过程可视化后,这种现象也看起来更加直观。
很遗憾,这里只分析了最近 10 年的数据。理想情况应该从 1960 年代就开始分析,但当时并无官方统计数据。此外,有一些指标,比如各个地区的经济不活跃指标、各种职业所占比例等也都是在 2004 年开始才有数据。
最后必要说一句,近些年英国足球流氓现象稍有好转,至少逮捕数据逐渐下降,但它不能完全代表球场内外的看球文化。而由于之前定性的研究已经溃烂,学术界也失去了研究它的新鲜感。媒体再度开始讨论足球流氓,是因为 2016 年 “战斗民族”加入了这个话题。











