主要观点总结
英伟达创始人兼CEO黄仁勋在英伟达GTC 2025大会上公布了基于下一代Rubin GPU架构的Vera Rubin超级芯片、Vera Rubin NVL144机架和Rubin Ultra NVL576机架,并介绍了Blackwell Ultra、Blackwell进展、数据中心AI超算、AI推理、AI智能体软件、个人AI超算、工作站和服务器GPU、光电一体化封装网络交换机、物理AI/机器人、电信AI和自动驾驶等12项新发布和升级,同时展示了英伟达在AI领域的未来路线图。此外,英伟达还发布了针对物理AI和机器人技术的Isaac GR00T N1人形机器人基础模型,并与迪士尼研究院、谷歌DeepMind合作开发开源物理引擎Newton。英伟达宣布Blackwell GPU创下DeepSeek-R1推理性能的世界纪录,并计划在未来推出Feynman平台。英伟达还展示了各种数据中心、桌面、笔记本电脑GPU新品,并发布了光电一体化封装网络交换机,旨在将AI工厂扩展到数百万块GPU。此外,英伟达还公布了与通用汽车合作构建的GM AI和全栈自动驾驶安全系统NVIDIA Halos。
关键观点总结
关键观点1: Vera Rubin、Rubin Ultra芯片
英伟达公布了Vera Rubin NVL144和Rubin Ultra NVL576机架级解决方案,展示了基于Rubin的AI工厂性能提升900倍。
关键观点2: Blackwell Ultra芯片
英伟达发布了全球首个288GB HBM3e GPU,展示了其数据中心AI超算产品和GB300 NVL72机架级解决方案。
关键观点3: 数据中心AI超算
英伟达推出了DGX SuperPOD和DGX GB300系统,提供交钥匙AI工厂,并将AI工厂性能提升至70倍。
关键观点4: AI推理、AI智能体软件
英伟达发布了开源AI推理软件Dynamo和Llama Nemotron推理模型系列,并宣布向全球企业提供构建AI智能体的核心模块。
关键观点5: 个人AI超算
英伟达推出了全球最小AI超算DGX Spark和高性能桌面级AI超算DGX Station,方便开发者本地微调或推理深度思考模型。
关键观点6: Blackwell进展
英伟达正在全面生产Blackwell,销售量是上一代Hopper的3倍。
关键观点7: 工作站和服务器GPU
英伟达发布了RTX Pro Blackwell系列工作站和服务器GPU,提供加速计算、AI推理、光线追踪和神经网络渲染技术。
关键观点8: 光电一体化封装网络交换机
英伟达推出了硅光网络交换机,可将AI工厂扩展到数百万块GPU。
关键观点9: 物理AI/机器人
英伟达发布了Isaac GR00T N1人形机器人基础模型,并与迪士尼研究院、谷歌DeepMind合作开发开源物理引擎Newton。
关键观点10: 电信AI和自动驾驶
英伟达与通用汽车合作构建GM AI,并发布全栈自动驾驶安全系统NVIDIA Halos。
关键观点11: 未来路线图
英伟达公布了未来在AI领域的路线图,包括开发AI原生无线网络、Feynman平台、扩展AI工厂等。
正文



2小时激情演讲!黄仁勋剧透四年芯片路线图,Blackwell一年大卖超300万块。
刚刚,黄仁勋宣布推出全新旗舰芯片Blackwell Ultra GPU,并剧透基于下一代Rubin GPU架构的Vera Rubin超级芯片、Vera Rubin NVL144机架和
Rubin Ultra
NVL576机架,全场爆发出热烈的掌声!
芯东西美国圣何塞3月18日现场报道,顶着热烈的加州阳光,一年一度的“AI春晚”英伟达GTC大会盛大开幕。今日上午,英伟达创始人兼CEO黄仁勋穿着闪亮的皮衣,进行了一场激情澎湃的主题演讲,一连亮出四代全新Blackwell Ultra、Rubin、Rubin Ultra、Feynman旗舰芯片,公布四年三代GPU架构路线图,还多次提到中国大模型DeepSeek。

英伟达将每年升级全栈AI系统、发布一条新产品线,2026年、2027年切换到采用Rubin 8S HBM4、Rubin Ultra 16S HBM4e和Vera CPU,2028年推出采用下一代HBM的Feynman(费曼)平台,NVSwitch、Spectrum、CX网卡都将同步迭代,从而为千兆瓦AI工厂铺平道路。
整场演讲信息量爆棚,覆盖加速计算、深度推理模型、AI智能体、物理AI、机器人技术、自动驾驶等在内的AI下一个风口,新发布涉及十大重点:
1、Vera Rubin、Rubin Ultra芯片
:
两代旗舰芯片HBM内存升级,GPU“乐高拼装术”日臻成熟,提前公布Vera Rubin NVL144机架、Rubin Ultra NVL576机架性能,最高FP4推理性能达到15EFLOPS,基于Rubin的AI工厂性能达到Hopper的900倍。
2、Blackwell Ultra芯片
:
全球首个288GB HBM3e GPU登场,发布GB300 NVL72机架、HGX B300 NVL16机架系统方案,一个机架能像单个大型GPU一样运行。
3、数据中心AI超算
:
推出Blackwell Ultra DGX SuperPOD,采用全新DGX GB300和DGX B300系统,助力企业构建开箱即用的AI超级计算机,发布AI托管服务NVIDIA Instant AI Factory、AI数据中心运营和编排软件NVIDIA Mission Control。
4、AI推理、AI智能体软件
:
AI推理软件Dynamo在运行DeepSeek-R1模型时,可将每个GPU生成的token数量提高超过30倍;全新Llama Nemotron推理模型系列中,Super 49B版本吞吐量达到Llama 3.3 70B、DeepSeek R1 Llama 70B的5倍;宣布向全球企业提供构建AI智能体的核心模块;存储龙头们构建企业级AI数据平台。
5、个人AI超算
:
推出全球最小AI超算DGX Spark、高性能桌面级AI超算DGX Station,方便开发者本地微调或推理深度思考模型。
6、Blackwell进展
:
正在全面生产,销售量是上一代Hopper的3倍。
7、工作站和服务器GPU
:上新RTX Pro Blackwell数据中本GPU、桌面级GPU、笔记本电脑GPU。
8、光电一体化封装网络交换机
:
号称“世界上最先进的网络解决方案”,可将AI工厂扩展到数百万块GPU。
9、物理AI/机器人
:
开源Isaac GR00T N1人形机器人基础模型,与迪士尼研究院、谷歌DeepMind将合作开发开源物理引擎Newton。
10、电信AI和自动驾驶
:
与通用汽车一起为工厂和汽车构建GM AI,构建综合全栈自动驾驶安全系统NVIDIA Halos。
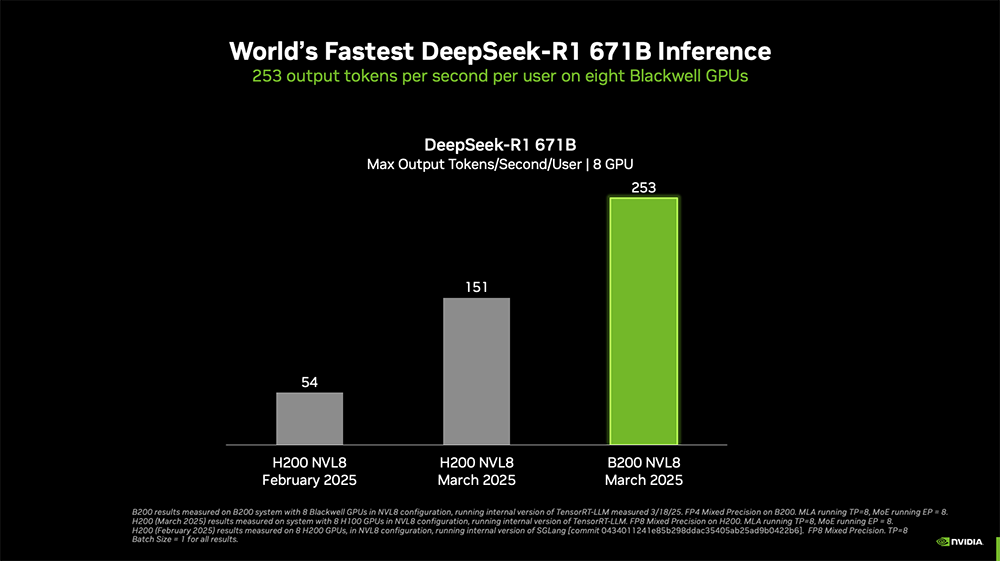
值得一提的是,英伟达宣布
Blackwell GPU创下满血版DeepSeek-R1推理性能的世界纪录
。
单个配备8块Blackwell GPU的NVIDIA DGX系统,可实现每位用户每秒超过250个token,或每秒超过30000个token的最大吞吐量。
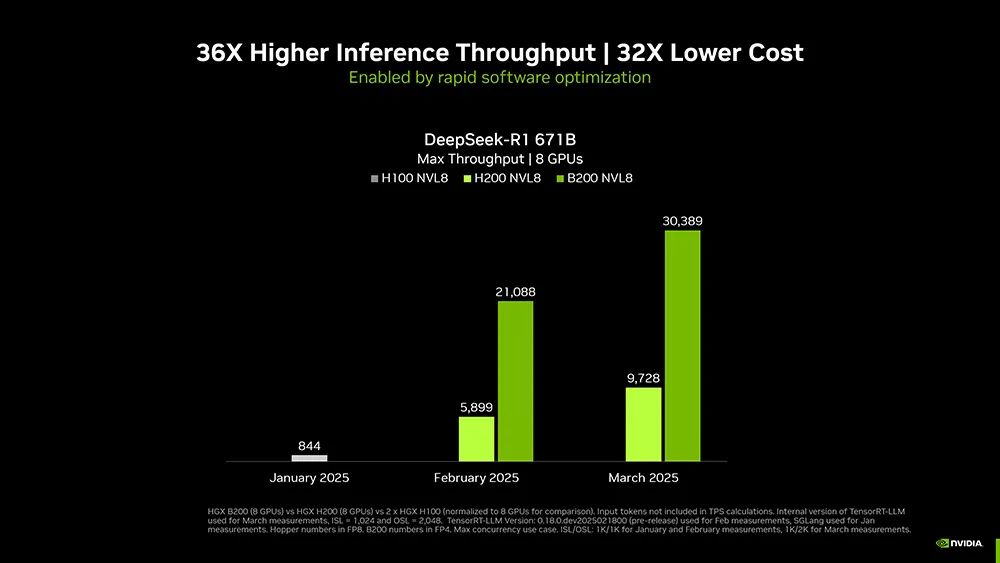
通过硬件和软件的结合,英伟达自今年1月以来将DeepSeek-R1 671B模型的吞吐量提高了约
36倍
,相当于每个token的成本提高了约
32倍
。
今年GTC人气火爆到史无前例,万元起步的门票悉数售罄,超过25000名观众齐聚现场,几乎整座圣何塞都染上了“英伟达绿”,从街巷、集市、高楼、餐厅、巴士到三轮车,到处都是醒目的英伟达GTC标识。

还有一个彩蛋,在黄仁勋主题演讲开始前,SAP中心大屏幕上播放的5人对话暖场视频中,画面最右边的正是前英特尔CEO帕特·基辛格,他的身份已经变成了Gloo董事长。

迪士尼机器人Blue作为黄仁勋主题演讲的惊喜嘉宾压轴出场,摇头晃脑向黄仁勋撒娇卖萌,还听从黄仁勋的指令,乖乖站到了他的旁边。

此外,本届GTC大会特设China AI Day - 云与互联网线上中文专场,涵盖大模型、数据科学、搜推广等领域的前沿进展,演讲企业包括字节跳动、火山引擎、阿里云、百度、蚂蚁集团、京东、美团、快手、百川智能、赖耶科技、Votee AI。
芯东西带你直击英伟达GTC大会现场,一文看尽英伟达重磅发布和黄仁勋主题演讲干货。
4月1-2日,智东西联合主办的2025中国生成式AI大会(北京站)将举行。35+位嘉宾/企业已确认,将围绕DeepSeek、大模型与推理模型、具身智能、AI智能体与GenAI应用带来分享和讨论。更多嘉宾陆续揭晓。欢迎报名~
上午9点59分,黄仁勋闪现圣何塞SAP中心舞台,朝不同方向的观众席连放5个冲天炮,然后慢慢走下舞台。

在参会观众翘首等待11分钟后,黄仁勋小步慢跑再度登场,笑容满面地向全场观众打招呼,还带观众云参观了下英伟达总部。

黄仁勋晒出了密密麻麻的GTC25企业logo,说几乎每个行业都有代表企业出现在了GTC现场。

至于为什么要提前展示路线图?黄仁勋说,构建AI工厂和AI基础设施需要数年的规划,不像买笔记本电脑,所以必须提前两三年制定土地、电力、资本支出的计划。
他公布了英伟达继Hopper、Blackwell之后的下一代GPU架构——
Rubin
。这一命名来自于发现暗物质的女性科学先驱薇拉·鲁宾(Vera Rubin)。
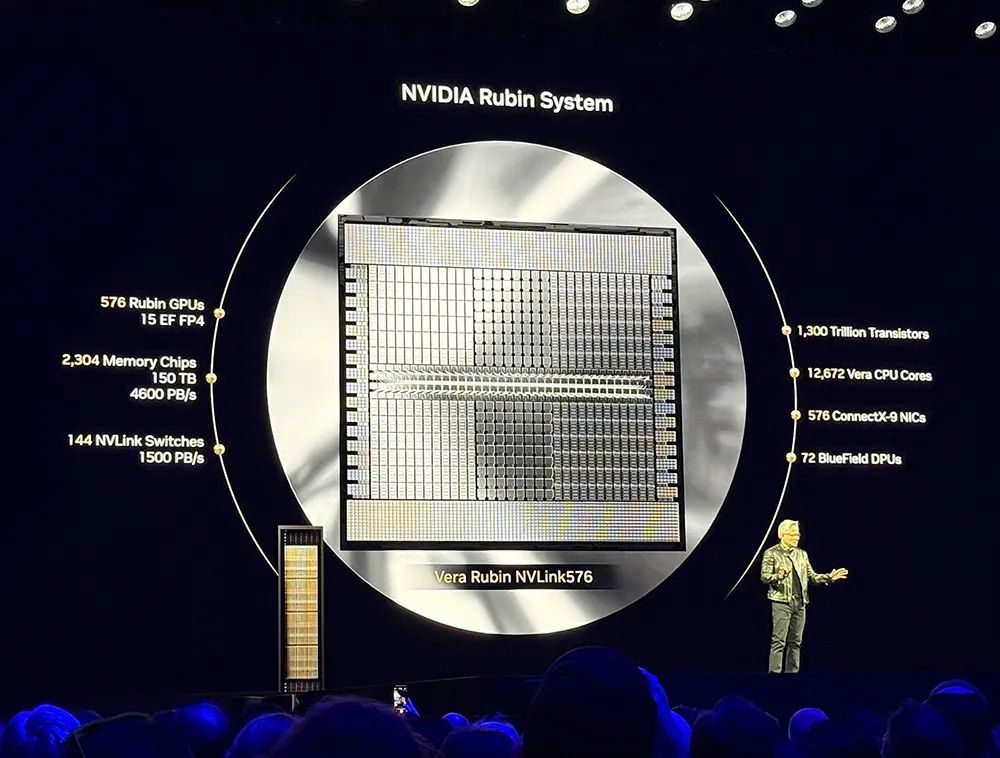
首先展示的是两个机架级解决方案,Vera Rubin NVL144和Rubin Ultra NVL576。
Vera Rubin
由Rubin GPU和Vera CPU组成。Vera CPU拥有88个定制Arm核心、176个线程。Rubin由两块掩模尺寸的GPU组成,拥有288GB HBM4内存,FP4峰值推理能力可达
50PFLOPS
。
Vera Rubin NVL144
的FP4推理算力可达到3.6EFLOPS,FP8训练算力可达到1.2EFLOPS,是今天新发布的GB300 NVL72的
3.3倍
,将于2026年下半年推出。

Rubin Ultra
系统由Rubin Ultra GPU和Vera CPU组成。Rubin Ultra由4块掩模尺寸的GPU组成,拥有1TB HBM4e内存,FP4峰值推理能力可达
100
PFLOPS
。
Rubin Ultra NVL576
的FP4峰值推理算力高达15EFLOPS,FP8训练算力达到5EFLOPS,足足是GB300 NVL72的
14倍
,将于2027年下半年推出。

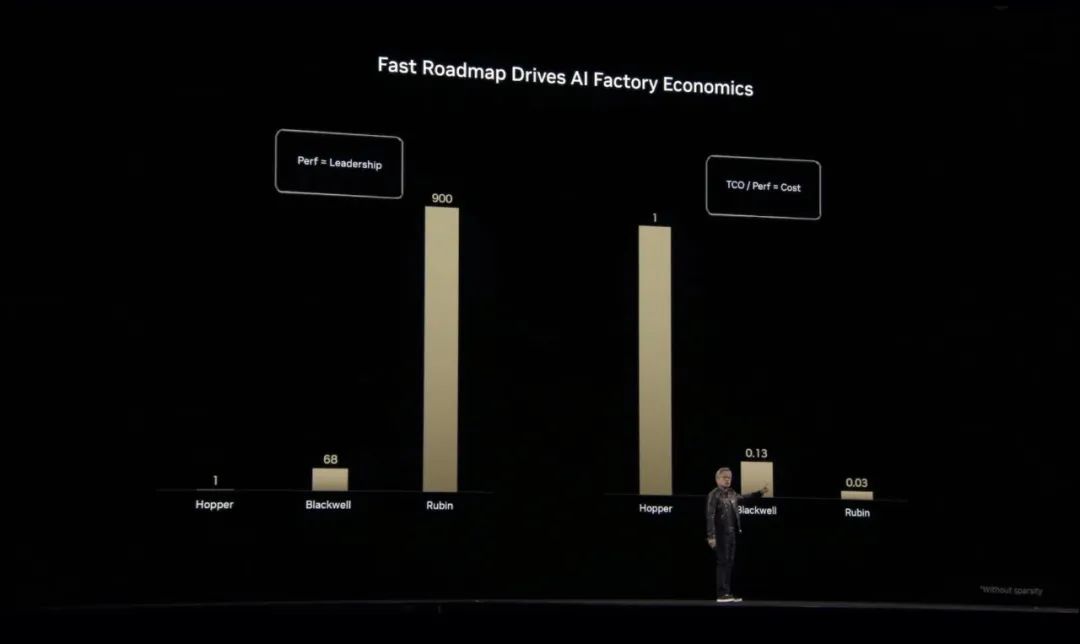
相较Hopper,基于Blackwell的AI工厂性能提高多达
68倍
,基于Rubin的AI工厂性能提高多达
900倍
。
新旗舰Blackwell Ultra:全球首个288GB HBM3e GPU,NVL72机架下半年问世
在万众期待中,英伟达新一代数据中心旗舰GPU
Blackwell Ultra(GB300)
正式登场。

Blackwell Ultra为AI推理时代而设计,是
全球首个288GB HBM3e GPU
,像拼乐高一样通过先进封装技术将2块掩膜尺寸的GPU拼装在一起,可实现多达
1.5倍
的FP4推理性能,最高15PFLOPS。
该GPU增强了训练和测试时推理扩展,可轻松有效地进行预训练、后训练以及深度思考(推理)模型的AI推理,构建于Blackwell架构基础之上,包括
GB300 NVL72
机架级解决方案和
HGX B300 NVL16
系统。
下一代模型可能包含数万亿参数,可以使用张量并行基于工作负载进行任务分配。如取模型切片在多个GPU上运行、将Pipeline放在多个GPU上、将不同专家模型放在不同GPU上,这就是MoE模型。
流水线并行、张量并行、专家并行的结合,可以取决于模型、工作量和环境,然后改变计算机配置的方式,以便获得最大吞吐量,同时对低延迟、吞吐量进行优化。
黄仁勋称,NVL72的优势就在于每个GPU都可以完成上述任务,NVLink可将所有GPU变成单个大型GPU。
GB300 NVL72
连接了72块Blackwell Ultra GPU和36块Grace CPU,采用机架式设计,密集FP4推理算力达到1.1EFLOPS,FP8训练算力达到0.36EFLOPS,是GB200 NVL72的1.5倍;总计有2倍的注意力指令集、20TB HBM内存、40TB快内存、14.4TB/s CX8。

升级的GB300 NVL72设计,提高了能效和可服务性,通过降低成本和能耗来推进AI推理民主化,相比Hopper将AI工厂的收入机会提高50倍。
GB300 NVL72预计将在英伟达端到端全托管AI平台DGX Cloud上提供。
与Hopper相比,
HGX B300 NVL16
在大语言模型上的推理速度加快至11倍,计算能力增加到7倍,内存增至4倍。
Blackwell Ultra系统与Spectrum-X以太网、Quantum-X800 InfiniBand平台无缝集成,通过ConnectX-8 SuperNIC,每个GPU有800Gb/s的数据吞吐量,提供了一流的远程直接内存访问功能,使AI工厂和云数据中心可在没有瓶颈的情况下处理AI推理模型。
英伟达合作伙伴预计将从
2025年下半年
起提供基于Blackwell Ultra的产品。
亚马逊云科技、谷歌云、微软Azure、甲骨文OCI、CoreWeave、Crusoe、Lambda、Nebius、Nscale、Yotta、YTL等云服务提供商将首批提供Blackwell Ultra驱动的实例。
数据中心AI超算:全新DGX SuperPOD,将AI工厂性能提升至70倍
英伟达
DGX SuperPOD
与
DGX GB300
系统采用GB300 NVL72机架设计,提供交钥匙AI工厂。
英伟达将NVIDIA DGX SuperPOD称作“全球最先进的企业级AI基础设施”,旨在为实时推理和训练提供强大的计算能力。
企业可采用全新DGX GB300和DGX B300系统,集成英伟达网络,获得开箱即用的DGX SuperPOD AI超级计算机。
DGX SuperPOD提供FP4精度和更快的AI推理速度,可扩展到数万块Grace Blackwell Ultra超级芯片,预计将在今年晚些时候从合作伙伴处可获得。

DGX GB300
系统采用英伟达Grace Blackwell Ultra超级芯片(包含36块Grace CPU和72块Blackwell GPU),以及一个为先进推理模型上的实时智能体响应而设计的机架级液冷架构。
与采用Hopper系统和38TB快内存构建的AI工厂相比,DGX GB300系统可提供
70倍
的AI性能。
每个DGX GB300系统配备72个ConnectX-8 SuperNIC,加速网络速度高达800Gb/s,是上一代性能的
2倍
。
18个BlueField-3 DPU搭配Quantum-X800 InfiniBand或Spectrum-X以太网,可加速大规模AI数据中心的性能、能效和安全。
与上一代Hopper相比,
DGX B300
系统可提供
11倍
的AI推理性能和
4倍
的AI训练加速。
每个系统提供2.3TB HBM3e内存,包含由8个英伟达ConnectX-8 SuperNIC和2个BlueField-3 DPU组成的先进网络。
英伟达还推出了一项以DGX SuperPOD为特色的托管服务
NVIDIA Instant AI Factory
,计划在今年晚些时候开始上市,并发布适用于Blackwell架构DGX系统的AI数据中心运营和编排软件
NVIDIA Mission Control
。
Equinix将率先在其位于全球45个市场的预配置液冷或风冷AI-ready数据中心提供新DGX GB300和DGX B300系统。
企业正竞相建设可扩展的AI工厂,以满足AI推理和推理时扩展的处理需求。英伟达推出开源的AI推理软件
NVIDIA Dynamo
,其本质上就是AI工厂的操作系统。
Dynamo(发电机)的命名来源是,发电机是开启上一次工业革命的第一台工具,Dynamo也是现在一切开始的地方。
NVIDIA Dynamo是一个用于大规模服务推理模型的AI推理软件,旨在为部署推理模型的AI工厂实现token收入最大化。
它能够跨数千个GPU编排和加速推理通信,并使用分区分服务来分离不同GPU上大语言模型的处理和生成阶段,使每个阶段可根据特定需求独立优化,并确保GPU资源的最大利用率。
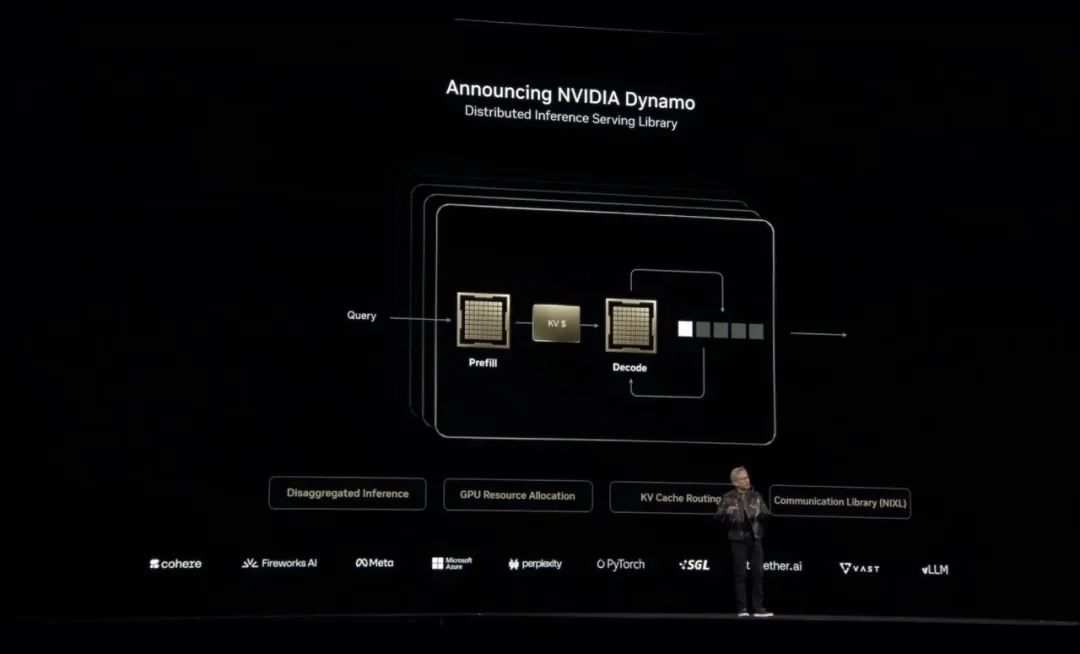
为了提高推理性能,英伟达采用Blackwell NVL8设计,之后又引入新的精度,用更少的资源量化模型。
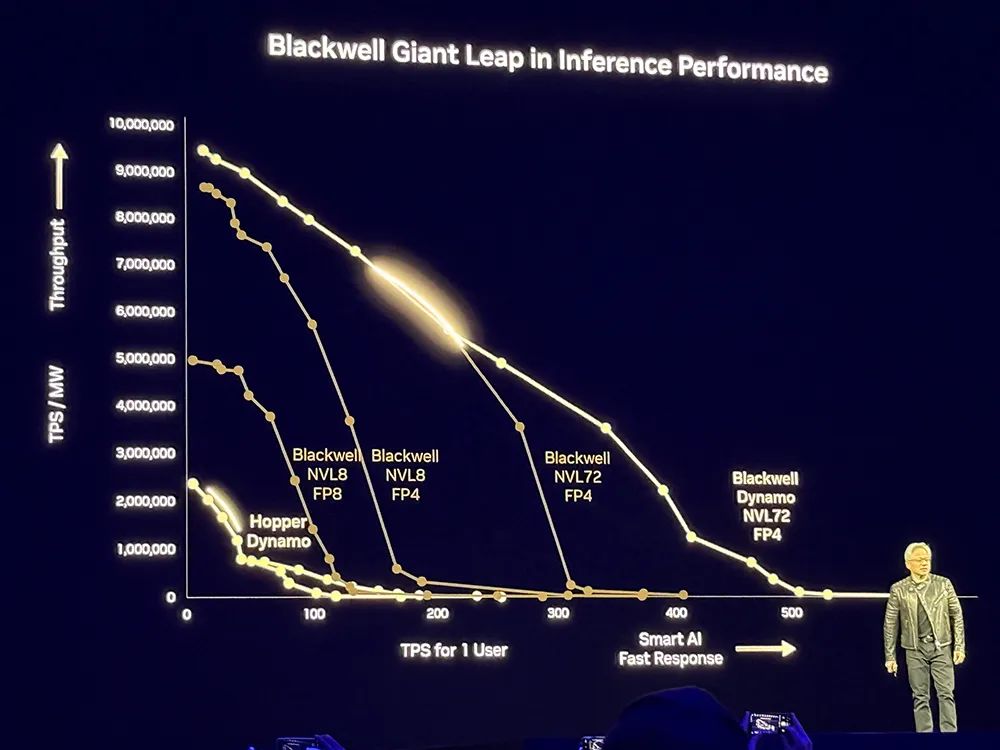
未来每个数据中心都会受到电力限制,数据中心的收入与之挂钩,因此英伟达用NVL72进行扩展,打造更节能的数据中心。
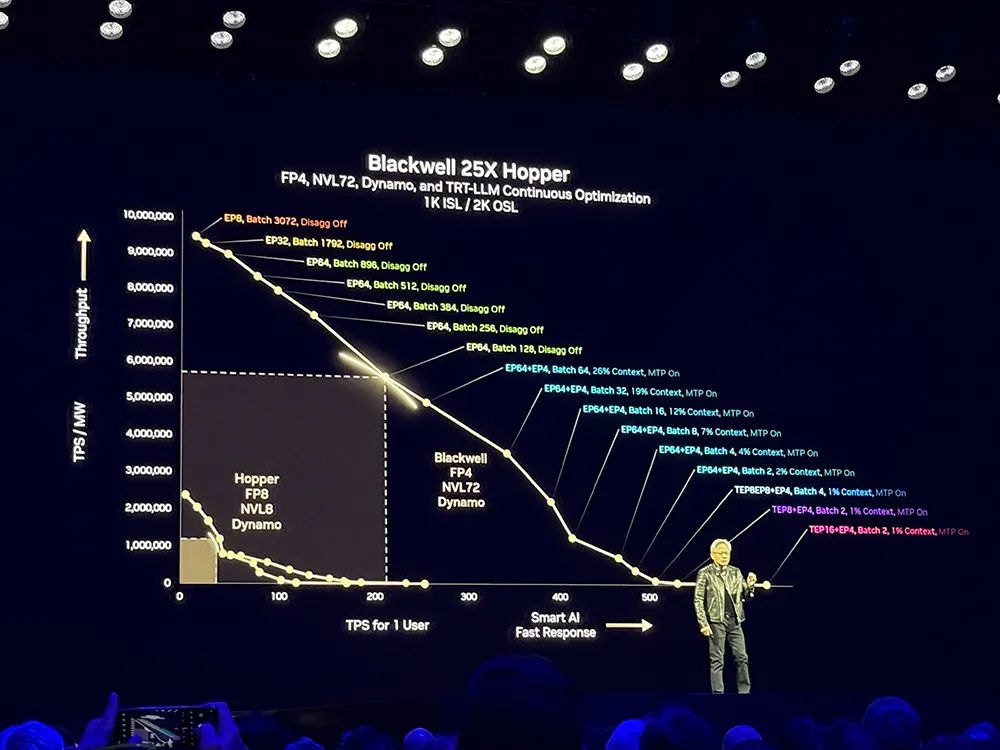
在GPU数量相同的情况下,Dynamo可将Hopper平台上运行Llama模型的AI工厂性能和收益翻倍。在由GB200 NVL72机架组成的大型集群上运行DeepSeek-R1模型时,Dynamo的智能推理优化也可将每个GPU生成的token数量提高
30倍
以上。
基于Dynamo,相比Hopper,Blackwell性能提升25倍,可以基于均匀可互换的可编程架构。在推理模型中,Blackwell性能是Hopper的
40倍
。
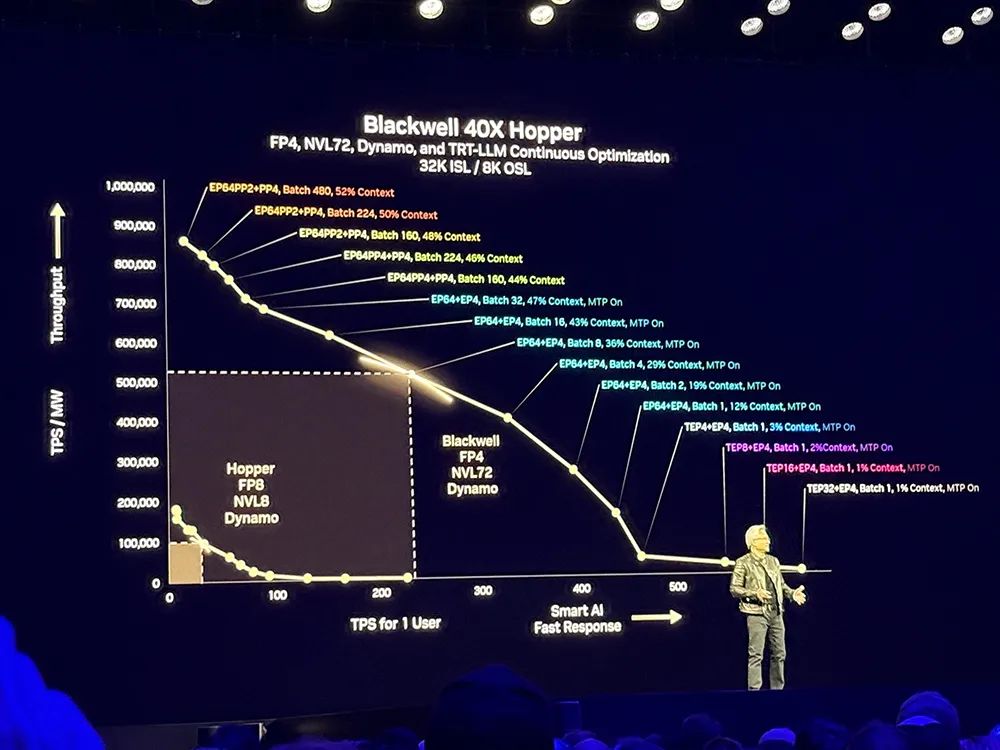
黄仁勋说:“这就是我以前为什么说,当Blackwell批量发货时,你不要把Hopper送人。”他调侃自己是“首席收入官”。
“买得越多,省得越多,赚得越多。”黄仁勋的经典带货名言又来了,这次他特别强调AI工厂收入的提高,100MW AI工厂会包含45000个GPU Die、1400个机架、每秒生成3亿个token。
相比Hopper,Blackwell能实现
40倍
的性能提升,对应产生
40倍
的token收入。

为了提升推理性能,NVIDIA Dynamo加入了一些功能,使其能够提高吞吐量的同时降低成本。
它可以根据不断变化的请求数量和类型,动态添加、移除、重新分配GPU,并精确定位大型集群中的特定 GPU,从而更大限度地减少响应计算和路由查询。
它还可以将推理数据卸载到成本更低的显存和存储设备上,并在需要时快速检索这些数据,最大程度地降低推理成本。
Dynamo可将推理系统在处理过往请求时于显存中保存的知识(称为KV缓存),映射到潜在的数千个GPU中。然后,它会将新的推理请求路由到与所需信息匹配度最高的 GPU 上,从而避免昂贵的重新计算,并释放GPU来响应新的请求。
该软件完全开源并支持PyTorch、SGLang、NVIDIA TensorRT-LLM和vLLM,使企业、初创公司和研究人员能够开发和优化在分离推理时部署AI模型的方法。
大模型公司Cohere计划使用NVIDIA Dynamo为其Command系列模型中的AI智能体功能提供支持。
英伟达还基于Llama开发了全新
Llama Nemotron推理模型系列
,提供Nano、Super、Ultra版本。其中Super 49B版本在生成速度和AI智能体任务的准确性两个维度超过DeepSeek-R1,吞吐量达到Llama 3.3 70B、DeepSeek R1 Llama 70B的
5倍
。
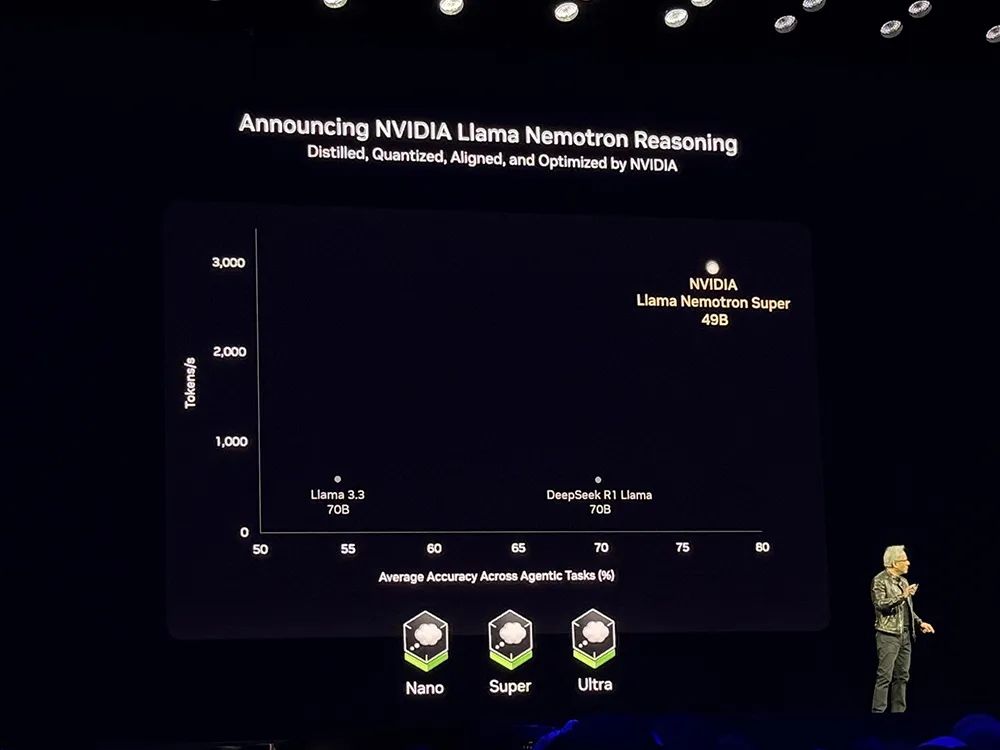
这些模型现已开源,企业可以通过NIM下载至本地运行。
英伟达正为全球企业提供
构建AI智能体的核心模块
,推动企业级AI技术的普及与创新。英伟达的Llama Nemotron可以在任何地方运行,包括DGX Spark、DGX Station以及OEM制造的服务器上,甚至可以将其集成到任何AI智能体框架中。
AT&T正在开发公司专用的的AI智能体系统。未来,英伟达不仅会雇佣ASIC设计师,还会与Cadence合作,引入数字ASIC设计师来优化芯片设计。Cadence正在构建他们的AI智能体框架,英伟达的模型、NIM和库已经深度集成到他们的技术中。Capital One、德勤、纳斯达克、SAP、ServiceNow、Accenture、Amdocs等企业也将英伟达技术深度融入AI框架中。
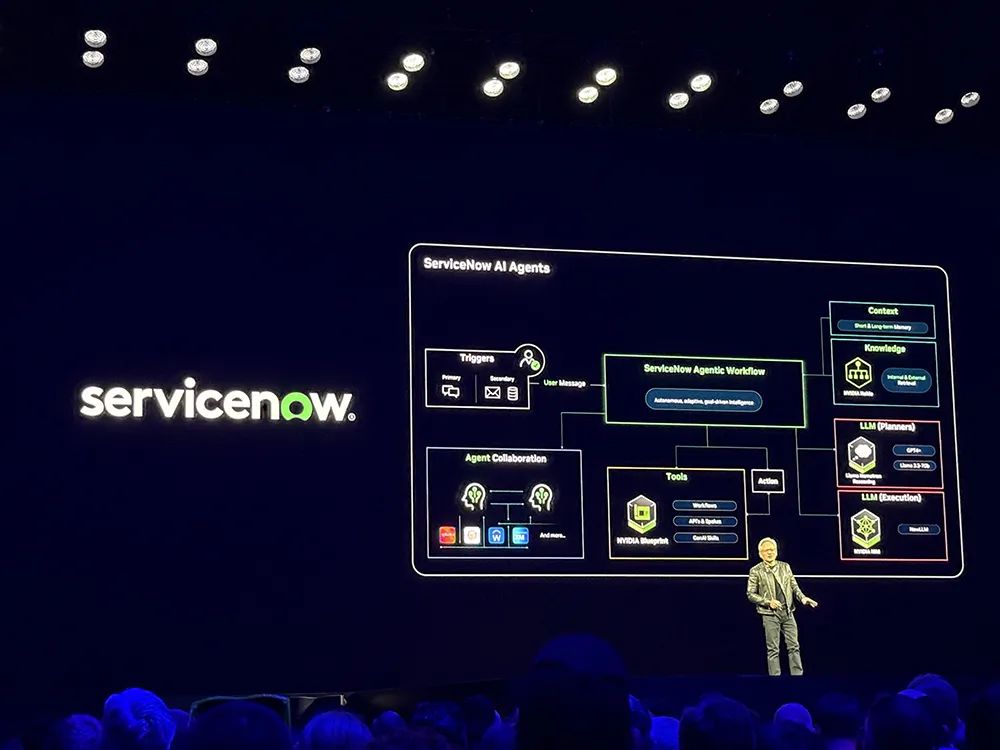
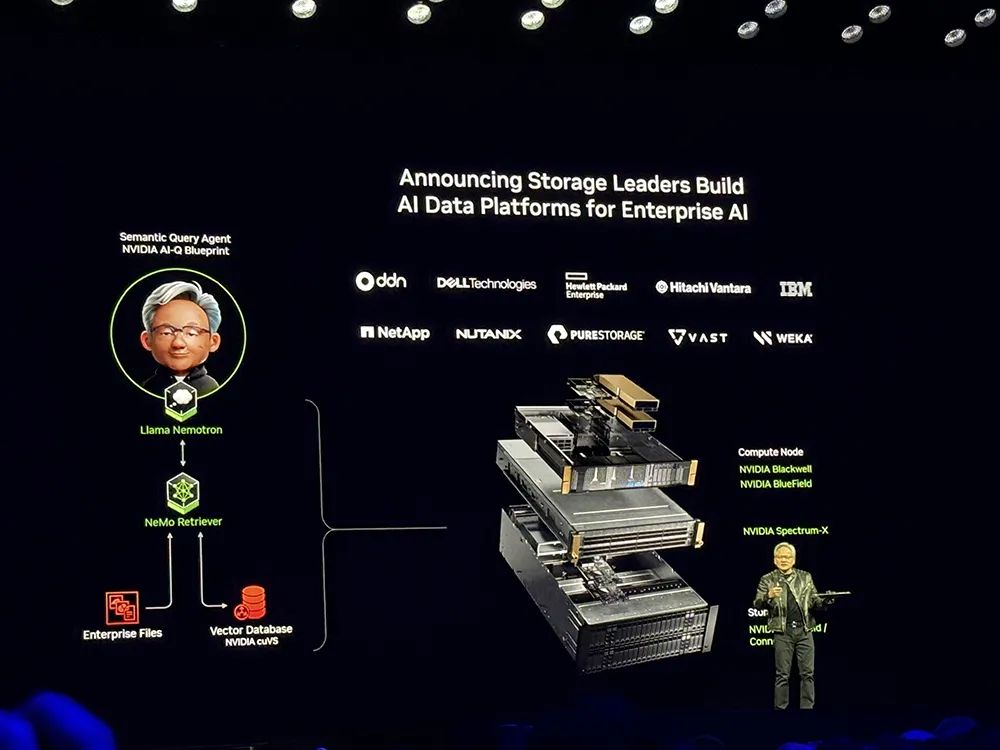
黄仁勋还宣布存储龙头们构建
企业级AI数据平台
。原本企业的存储系统是基于召回的,而如今的系统应该基于语义。基于语义的存储系统时刻在嵌入原始数据,用户使用数据时只需使用自然语言进行交互,便能找到需要的数据。
NVIDIA DGX Spark和DGX Station是英伟达打造的个人AI计算机,让开发者能在桌面上对大模型进行原型、微调、推理。

全球最小AI超级计算机
DGX Spark
前身是Project DIGITS,采用GB10 Grace Blackwell超级芯片、128GB统一系统内存、ConnectX-7 SmartNIC,AI算力可达1000 AI TOPS。

DGX Spark可以被用来微调或推理最新的AI推理模型,比如英伟达今天新发布的Cosmos推理世界基础模型和GR00T N1机器人基础模型。该AI超算的预订今日起开放。
DGX Station
是一款基于Blackwell Ultra的新型高性能桌面级超级计算机,为桌面带来了数据中心级别的性能,用于AI开发,今年晚些时候可从英伟达制造合作伙伴处获得。

这是第一个采用英伟达GB300 Grace Blackwell Ultra桌面超级芯片构建的台式机系统,拥有784GB超大统一系统内存,还有支持800Gb/s网络连接的ConnectX-8 SuperNIC,AI性能达到20PFLOPS。
Blackwell卖得超好!DeepSeek-R1
Blackwell系统构建于英伟达强大的开发工具生态系统、CUDA-X库、600多万开发者和4000多个应用的基础上,可在数千块GPU上扩展性能,非常适合运行新的Llama Nemotron推理模型、AI-Q蓝图、AI企业级软件平台。

黄仁勋说CUDA-X是GTC的全部意义所在。他展示了一张自己最喜欢的幻灯片,包含了英伟达构建的关于物理、生物、医学的AI框架,包括加速计算库cuPyNumeric、计算光刻库cuLitho,软件平台cuOPT、医学成像库Monaiearth-2、加速量子计算的cuQuantum、稀疏直接求解器库cuDSS、开发者框架WARP等。

“我们已经达到加速计算的临界点,CUDA让这一切成为可能。”黄仁勋谈道。





