【导读】
微软开源的DeepSpeed Chat,让开发者实现了人手一个ChatGPT的梦想!
刚刚,微软开源了一个可以在模型训练中加入完整RLHF流程的系统框架——DeepSpeed Chat。
也就是说,各种规模的高质量类ChatGPT模型,现在都唾手可得了!
项目地址:https://github.com/microsoft/DeepSpeed
众所周知,由于OpenAI太不Open,开源社区为了让更多人能用上类ChatGPT模型,相继推出了LLaMa、Alpaca、Vicuna、Databricks-Dolly等模型。
但由于缺乏一个支持端到端的RLHF规模化系统,目前类ChatGPT模型的训练仍然十分困难。
而
DeepSpeed Chat的出现,正好补全了这个「bug」。

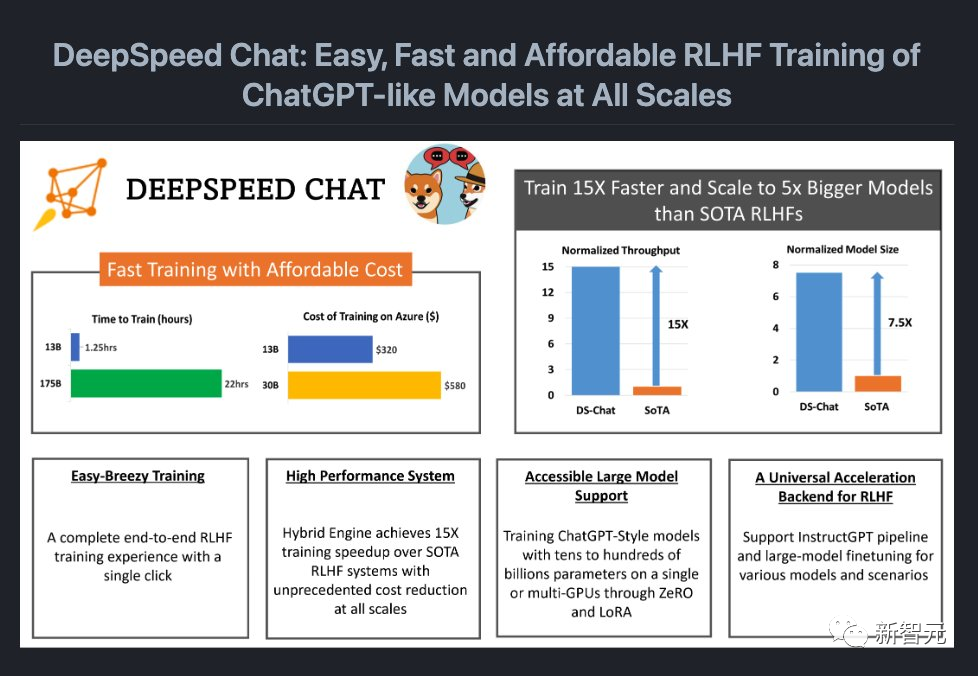
更亮的是,DeepSpeed Chat把成本大大地打了下来。
此前,昂贵的多GPU设置超出了许多研究者的能力范围,并且,即使能访问多GPU集群,现有的方法也无力负担数千亿参数ChatGPT模型的训练。
现在,只要花1620美元,就可以通过混合引擎DeepSpeed-HE,在2.1天内训练一个OPT-66B模型。
而如果使用多节点、多GPU系统,DeepSpeed-HE可以花320美元,在1.25小时内训练一个OPT-13B模型,花5120美元,就能在不到一天的时间内训练一个OPT-175B模型。
前Meta AI专家Elvis激动转发,称这是一件大事,并表示好奇DeepSpeed Chat和ColossalChat相比起来如何。
经过DeepSpeed-Chat的训练,13亿参数版「ChatGPT」在问答环节上的表现非常亮眼。不仅能get到问题的上下文关系,而且给出的答案也有模有样。
在多轮对话中,这个13亿参数版「ChatGPT」所展示出的性能,也完全超越了这个规模的固有印象。
git clone https://github.com/microsoft/DeepSpeed.gitcd DeepSpeedpip install .
git clone https://github.com/microsoft/DeepSpeedExamples.gitcd DeepSpeedExamples/applications/DeepSpeed-Chat/pip install -r requirements.txt
一杯咖啡,训完13亿参数版ChatGPT
如果你只有大约1-2小时的咖啡或午餐休息时间,也可以尝试使用DeepSpeed-Chat训练一个「小玩具」。
团队特地准备了一个针对1.3B模型的训练示例,可在消费级GPU上进行测试。最棒的是,当你从午休回来时,一切都已准备就绪。
python train.py --actor-model facebook/opt-1.3b --reward-model facebook/opt-350m --num-gpus 1
配备48GB显存的消费级NVIDIA A6000 GPU:
一个GPU Node,半天搞定130亿参数
如果你只有半天的时间,以及一台服务器节点,则可以通过预训练的OPT-13B作为actor模型,OPT-350M作为reward模型,来生成一个130亿参数的类ChatGPT模型:
python train.py --actor-model facebook/opt-13b --reward-model facebook/opt-350m --num-gpus 8
单DGX节点,搭载了8个NVIDIA A100-40G GPU:
超省钱云方案,训练660亿参数模型
如果你可以使用多节点集群或云资源,并希望训练一个更大、更高质量的模型。那么只需基于下面这行代码,输入你想要的模型大小(如66B)和GPU数量(如64):
python train.py --actor-model facebook/opt-66b --reward-model facebook/opt-350m --num-gpus 64
8个DGX节点,每个节点配备8个NVIDIA A100-80G GPU:
具体来说,针对不同规模的模型和硬件配置,DeepSpeed-RLHF系统所需的时间和成本如下:
DeepSpeed Chat是一种通用系统框架,能够实现类似ChatGPT模型的端到端RLHF训练,从而帮助我们生成自己的高质量类ChatGPT模型。
DeepSpeed Chat具有以下三大核心功能:
1. 简化ChatGPT类型模型的训练和强化推理体验
开发者只需一个脚本,就能实现多个训练步骤,并且在完成后还可以利用
推理API进行
对话式
交互测试。
2. DeepSpeed-RLHF模块
DeepSpeed-RLHF复刻了InstructGPT论文中的训练模式,并提供了数据抽象和混合功能,支持开发者使用多个不同来源的数据源进行训练。
3. DeepSpeed-RLHF系统
团队将DeepSpeed的训练(training engine)和推理能力(inference engine) 整合成了一个统一的混合引擎(DeepSpeed Hybrid Engine or DeepSpeed-HE)中,用于RLHF训练。
由于,
DeepSpeed-HE
能够
无缝地在推
理和
训练模式之间
切换,因此
可以
利用来自
DeepSpeed-Inference
的各种优化
。
DeepSpeed-RLHF系统在大规模训练中具有无与伦比的效率,使复杂的RLHF训练变得快速、经济并且易于大规模推广:
DeepSpeed-HE比现有系统快15倍以上,使RLHF训练快速且经济实惠。
例如,DeepSpeed-HE在Azure云上只需9小时即可训练一个OPT-13B模型,只需18小时即可训练一个OPT-30B模型。这两种训练分别花费不到300美元和600美元。
DeepSpeed-HE能够支持训练拥有数千亿参数的模型,并在多节点多GPU系统上展现出卓越的扩展性。
因此,即使是一个拥有130亿参数的模型,也只需1.25小时就能完成训练。而对于拥有1750 亿参数的模型,使用DeepSpeed-HE进行训练也只需不到一天的时间。
仅凭单个GPU,DeepSpeed-HE就能支持训练超过130亿参数的模型。这使得那些无法使用多GPU系统的数据科学家和研究者不仅能够轻松创建轻量级的RLHF模型,还能创建大型且功能强大的模型,以应对不同的使用场景。
为了提供无缝的训练体验,研究者遵循InstructGPT,并在DeepSpeed-Chat中包含了一个完整的端到端训练流程。
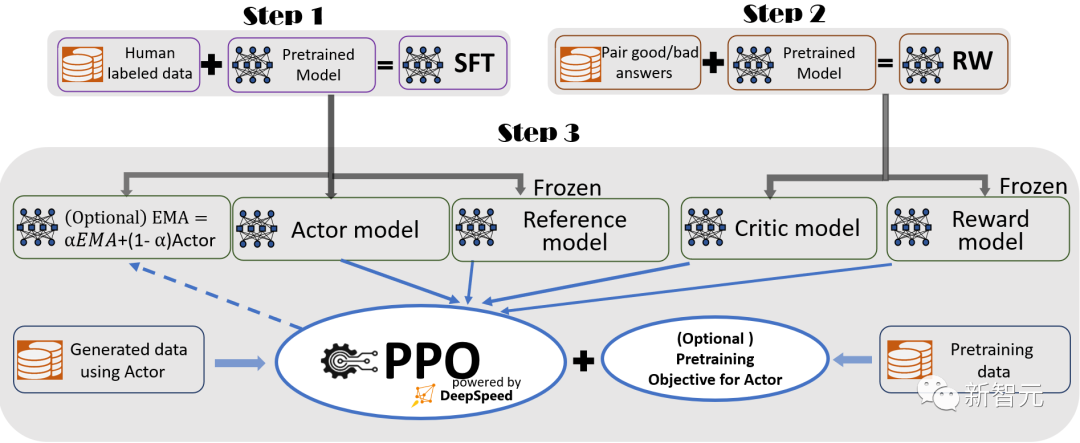
DeepSpeed-Chat的RLHF训练流程图示,包含了一些可选择的功能
监督微调 (SFT),使用精选的人类回答来微调预训练的语言模型,以应对各种查询。
奖励模型微调,用一个包含人类对同一查询的多个答案打分的数据集,来训练一个独立的(通常比SFT小)奖励模型(RW)。
RLHF训练,在这一步,SFT模型通过使用近似策略优化(PPO)算法,从RW模型的奖励反馈进一步微调。
在步骤3中,研究者还提供了两个附加功能,来帮助提高模型质量:
- 指数移动平均线(EMA)的收集,可以选择一个基于EMA的检查点,进行最终评估。
- 混合训练,将预训练目标(即下一个词预测)与 PPO 目标混合,以防止在公共基准(如SQuAD2.0)上的性能回归。
EMA和混合训练这两个训练特征,常常被其他的开源框架所忽略,因为它们并不会妨碍训练的进行。
然而,根据InstructGPT,EMA检查点往往比传统的最终训练模型提供更好的响应质量,而混合训练可以帮助模型保持训练前的基准解决能力。
因此,研究者为用户提供了这些功能,让他们可以充分获得InstructGPT中描述的训练经验。
而除了与InstructGPT论文高度一致外,研究者还提供了功能,让开发者使用多种数据资源,训练自己的RLHF模型:
DeepSpeed-Chat配备了(1)抽象数据集层,以统一不同数据集的格式;以及(2)数据拆分/混合功能,从而使多个数据集被适当地混合,然后在3个训练阶段进行分割。








