来自:静觅
链接:http://cuiqingcai.com/3179.html
转载请注明:静觅 » 小白爬虫第一弹之抓取妹子图
这是一篇完全给新手写的爬虫教程
 由于经常在群里装逼加上群主懒啊(你看有多久没更新文章就知道了),让我来一篇爬虫的教程。
由于经常在群里装逼加上群主懒啊(你看有多久没更新文章就知道了),让我来一篇爬虫的教程。

如此装逼机会怎么能错过,今天我来给大家来一篇基础爬虫教程。
你要问目标是啥? 要知道XX才是学习最大的动力啊!所以目标就是 mzitu.com
 (废话真多还不开始) , 下面请各位跟我的教程一步一步走,喂!!说的就是你啊!别看着了,照着教程做啊!
(废话真多还不开始) , 下面请各位跟我的教程一步一步走,喂!!说的就是你啊!别看着了,照着教程做啊!

1、基础环境部分:
工欲其事必先利器,要想把心爱的妹子搬进你的给她准备的房子,总得有几把斧子才行啊!下面这就是几把斧子!
1.1:Python基础运行环境:
本篇教程采用Python3 来写,所以你需要给你的电脑装上Python3才行,我就说说Windows的环境(会玩Linux的各位应该不需要我多此一举了)。
anaconda (点我下载)(这是一个Python的科学计算发行版本,作者打包好多好多的包,

不知道干啥的没关系,你只需要知道拥有它之后,那些Windows下pip安装包报错的问题将不复存在)
下载不顺利的同学我已经传到百度云了:http://pan.baidu.com/s/1boAYaTL
1.2:Requests
rllib的升级版本打包了全部功能并简化了使用方法(点我查看官方文档)
1.3: beautifulsoup
是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.(点我查看官方文档)(

作为一个菜鸟就别去装逼用 正则表达式了,匹配不到想要的内容,容易打击积极性。老老实实的用beautifulsoup 吧!虽然性能差了点、但是你会爱上它的。)
1.4:LXML
一个HTML解析包 用于辅助beautifulsoup解析网页(如果你不用anaconda,你会发现这个包在Windows下pip安装报错,
用了就不会啦。)。
上面的模块需要 单独安装,下面几个就不用啦。
1.5:OS 系统内置模块
下面是IDE 你喜欢用什么就用什么啦!
1.6:PyCharm
一个草鸡好用的PythonIDE工具 、真滴!草鸡好用··(我是下载地址)试用三十天 足够完成这个小爬虫啦。(如果你电脑已经存在Python环境 又需要使用anaconda的话,请按照下面的图设置一下哦!)

好啦、下面开始安装需要的模块。
因为我安装的是anaconda这个科学计算的发行版,安装方式是酱紫滴:conda install 包名(当然 pip install 包名也是可以的哦!)
conda install beautifulsoup4 conda install lxml 或者 pip install requests pip install beautifulsoup4 pip install lxml
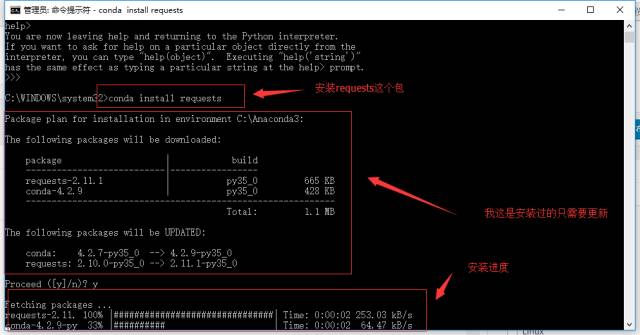
大概界面就是上面的样子了。其余类似安装即可,好啦 下面开始正题了
首先我们打开PyCharm 新建一个Python文件,写入以下代码(喂喂!不要复制哦 自己敲一遍 印象更佳啦。)
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import os
好啦!准备工作完了、 我们来开始让妹子到碗里来吧ヽ(●-`Д´-)ノ 一个简单爬虫的诞生大慨需要下面几个步骤。(我知道图很简陋、请务必不要吐槽)

-
爬虫入口:
顾名思义我需要程序从什么地方开始获取网页
-
存储数据:
如果获取的网页有你需要的内容则取出数据保存
-
找到资料所在的地址:
如果你你获取到的网页没有你需要的数据、但是有前往该数据页面的地址URL、则获取这个地址URL,再获取该URL的页面内容(也就等于当作爬虫入口了)
好啦!图很简陋、将就着看看,现在来开始看看网页找一个爬虫入口(开始爬取的页面)

良心站长啊!居然有一个页面有整站所有的数据地址是http://www.mzitu.com/all 我们就以这个页面开始爬取(PS:真良心站长)
下面是我们的第一段代码:用作获取http://www.mzitu.com/all这个页面。
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import os headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://www.mzitu.com/all' ##开始的URL地址
start_html = requests.get(all_url, headers=headers) ##使用requests中的get方法来获取all_url(就是:http://www.mzitu.com/all这个地址)的内容 headers为上面设置的请求头、请务必参考requests官方文档解释
print(start_html.text) ##打印出start_html (请注意,concent是二进制的数据,一般用于下载图片、视频、音频、等多媒体内容是才使用concent, 对于打印网页内容请使用text)
PS: 如果对requests.get(all_url, headers=headers)感到不解的各位,请务必去再看一遍官方文档哦(解释得很清楚呢)
你在你的IDE中运行的时候会打印出下面的内容:
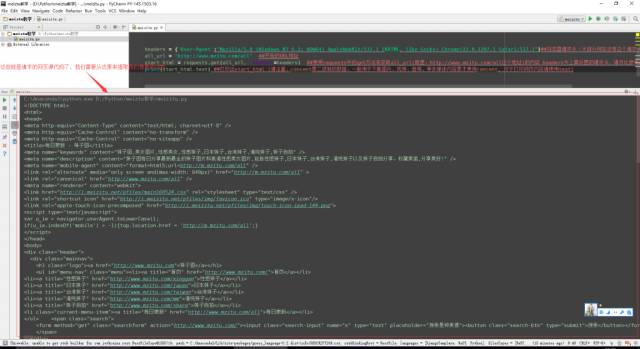
第一段部分完成啦!!是不感觉超简单!!!!看懂没?没看懂继续瞅瞅、对于看懂的各位小哥儿(妹儿)我只想说··· 小哥儿(妹儿)!你老牛逼了!!
没看懂?报错?没关系!看见屏幕右边那个群号没?加它!热心的群友会为你耐心解答滴············
好啦!第一部分获取网页的部分完成啦!我们来开始第二部分提取我们想要的内容吧!!
在Chrome中打开我们第一部分请求的网址:http://www.mzitu.com/all 、 按下F12 调出Chrome的开发者调试工具(不熟练的同学一定要去了解一下哦!爬虫中绝大部分工作要靠这个来完成呢!是必备技能哦!)
是这样:
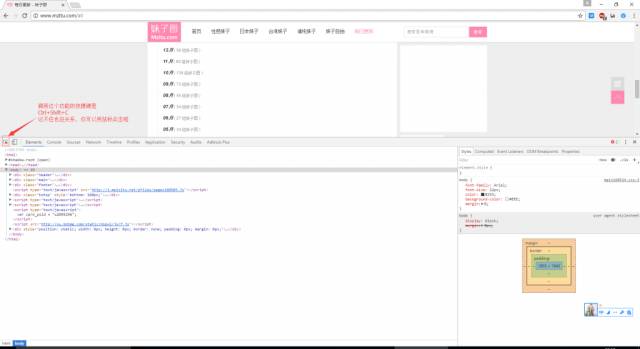
看见图中那句话没?没看见?仔细看看那可是我们必须要使用的工具哦!!好啦下面我们看看使用方法
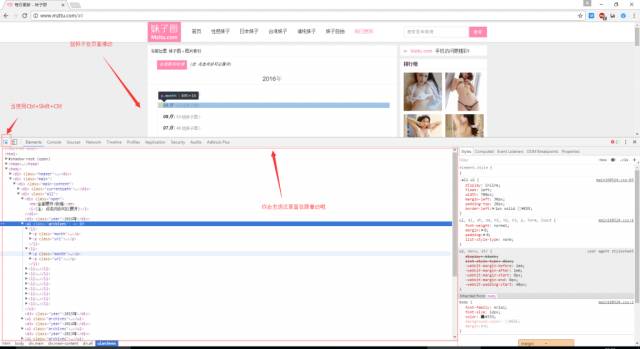
好啦、我们就是通过这种方法来找到我们需要的数据在那一个标签里面的、方便后面提取出来啦!(实例很简陋 看不懂的童鞋百度一下啦!教程很多的)
你会发现这个页面并没有我们需要的图片地址啊!没有那么怎么办呢?上面那张超级简陋的流程图看了嘛?没看?赶快去瞅瞅·· 你就知道我们该干啥啦!
嗯,我们需要找到图片地址所在的页面!
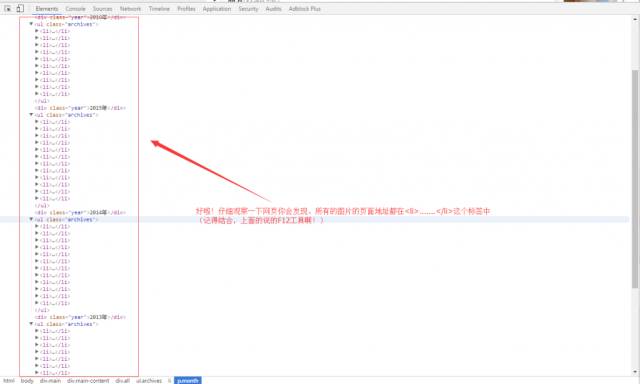
观察一下网页你会发现图片页面的地址全部都在
…
标签中、(讲真!这么良心,还这么有规律的网页不多了啊!)不信啊?你展开
标签瞅瞅就知道啦
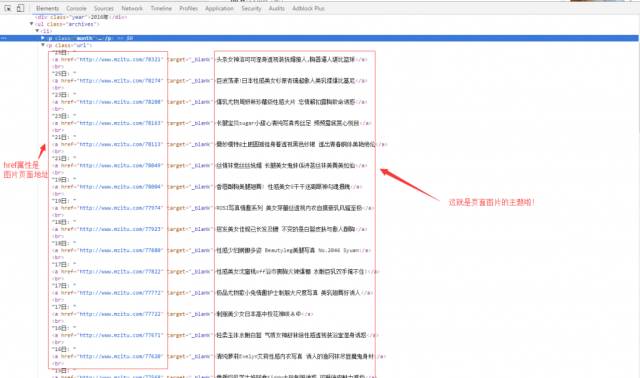
点开
标签你会发现图片页面的地址在
标签的href属性中、主题在
标签中(搞不清楚的这两个的区别的同学、去了解一下html的基础啦!)
实现逻辑就是:先找到页面中的全部
标签、然后提取出中间
标签的href属性值与
标签的类容,前者我们用来继续请求html看看会不会有我们需要的图片下载地址,后者我们存储的时候给文件夹命名使用。
可能有小哥儿(妹儿)会问,为什么不直接查找
标签?
你观察一下网页就知道呐!还有其他地方使用了
标签,如果直接查找
标签就会多出很多我们不需要的东西,也不方便我们提取想要的东西,先查找
标签就是限制一下
标签的范围啦!
通过上面的方法、知道了需要的数据的位置!该我们的beautifulsoup来大展身手啦!!!加上上面的一段代码现在应该是这样的啦!看不懂?没关系 看注释 看注释。
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import os headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://www.mzitu.com/all' ##开始的URL地址
start_html = requests.get(all_url, headers=headers) ##使用requests中的get方法来获取all_url(就是:http://www.mzitu.com/all这个地址)的内容 headers为上面设置的请求头、请务必参考requests官方文档解释 #print(start_html.text) ##打印出start_html (请注意,concent是二进制的数据,一般用于下载图片、视频、音频、等多媒体内容是才使用concent, 对于打印网页内容请使用text)
Soup = BeautifulSoup(start_html.text, 'lxml') ##使用BeautifulSoup来解析我们获取到的网页(‘lxml’是指定的解析器 具体请参考官方文档哦)
li_list = Soup.find_all('li') ##使用BeautifulSoup解析网页过后就可以用找标签呐!(find_all是查找指定网页内的所有标签的意思,find_all返回的是一个列表。)
for li in li_list: ##这个不解释了。看不懂的小哥儿回去瞅瞅基础教程 print(li) ##同上
运行一下试试!

诶!!!不对啊!!抓到了我们不需要的东西啊!!!这可怎么办啊!!
别急 别急!我们再去看看网页的 F12瞅瞅。
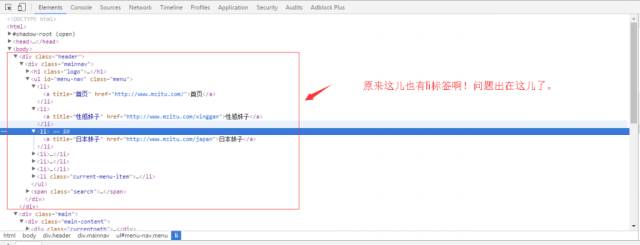
找到啦!原来有其他地方有
标签、观察不仔细啦!现在我们怎么办?
我们再去F12瞅瞅!
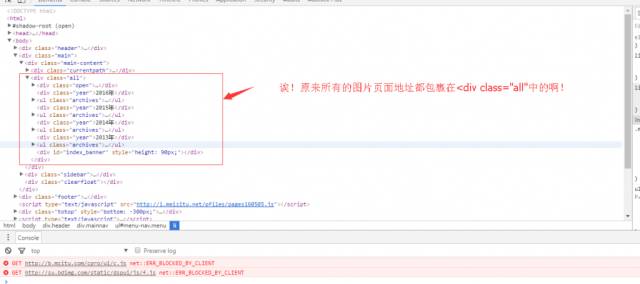
哈哈!这就简单了,我们推翻上面的思路 现在我们先找到
标签呢!!
你仔细瞅瞅网页!在
这个模块里面的
标签的全是我们需要的东西,就不需要
标签来限制提取范围啦!所以就直接扔掉了不用了。也方便写代码啊。
现在我们改改上面的代码!
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import os headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://www.mzitu.com/all' ##开始的URL地址
start_html = requests.get(all_url, headers=headers) ##使用requests中的get方法来获取all_url(就是:http://www.mzitu.com/all这个地址)的内容 headers为上面设置的请求头、请务必参考requests官方文档解释 #print(start_html.text) ##打印出start_html (请注意,concent是二进制的数据,一般用于下载图片、视频、音频、等多媒体内容是才使用concent, 对于打印网页内容请使用text)
Soup = BeautifulSoup(start_html.text, 'lxml') ##使用BeautifulSoup来解析我们获取到的网页(‘lxml’是指定的解析器 具体请参考官方文档哦) #li_list = Soup.find_all('li') ##使用BeautifulSoup解析网页过后就可以用找标签呐!(find_all是查找指定网页内的所有标签的意思,find_all返回的是一个列表。) #for li in li_list: ##这个不解释了。看不懂的效小哥儿回去瞅瞅基础教程 #print(li) ##同上
all_a = Soup.find('div', class_='all').find_all('a') ##意思是先查找 class为 all 的div标签,然后查找所有的标签。
for a in all_a: print(a)
PS: ‘find’ 只查找给定的标签一次,就算后面还有一样的标签也不会提取出来哦! 而 ‘find_all’ 是在页面中找出所有给定的标签!有十个给定的标签就返回十个(返回的是个list哦!!),想要了解得更详细,就是看看官方文档吧!
来看看运行结果!
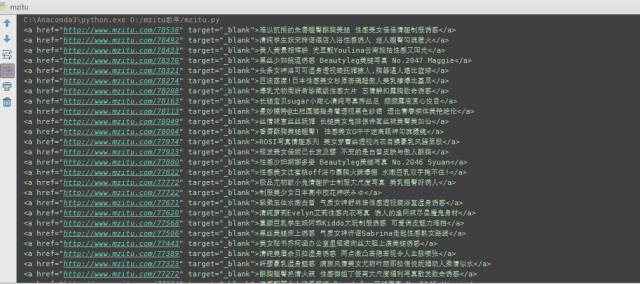
哇哦!!全是我们需要的类容诶!什么?你的和这个不一样?或者报错了?回头看看 你做的和我有什么不一样······ 实在不行,群里求助吧!
好啦!现在我们该来提取我们想要的内容了!又该我们BeautifulSoup大展身手了。
我们需要提取出
标签的href属性和文本。怎么做呢?看代码!
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import os headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://www.mzitu.com/all' ##开始的URL地址
start_html = requests.get(all_url, headers=headers) ##使用requests中的get方法来获取all_url(就是:http://www.mzitu.com/all这个地址)的内容 headers为上面设置的请求头、请务必参考requests官方文档解释 #print(start_html.text) ##打印出start_html (请注意,concent是二进制的数据,一般用于下载图片、视频、音频、等多媒体内容是才使用concent, 对于打印网页内容请使用text)
Soup = BeautifulSoup(start_html.text, 'lxml') ##使用BeautifulSoup来解析我们获取到的网页(‘lxml’是指定的解析器 具体请参考官方文档哦) #li_list = Soup.find_all('li') ##使用BeautifulSoup解析网页过后就可以用找标签呐!(find_all是查找指定网页内的所有标签的意思,find_all返回的是一个列表。) #for li in li_list: ##这个不解释了。看不懂的效小哥儿回去瞅瞅基础教程 #print(li) ##同上
all_a = Soup.find('div', class_='all').find_all('a') ##意思是先查找 class为 all 的div标签,然后查找所有的标签。
for a in all_a: title = a.get_text() #取出a标签的文本 href = a['href'] #取出a标签的href 属性 print(title, href)
就多了两行!很方便吧!!为什么这么写?自己去看官方文档啦!(我要全解释了,估计有些小哥儿官方文档都不会去看。这样很不好诶。)
来来!看看结果怎么样 我们来打印一下看看!

哈哈 果然是我们想要的内容!我们已经找向目标前进了一半了!好啦前面已经把怎么实现的方法讲清楚了哦(如果你觉得什么地方有问题或者不清楚,在群里说说 我好改改)下面就要开始加快节奏了!!(篇幅长了 会被人骂的!)
上面我们找到了 图片的标题(暂时不管,这是后面用来创建文件夹的)和 图片页面的地址(这是我们这一步需要做的),需要做什么请参考最上面那个超简陋的流程图。
先查看一下图片页面有什么东西
你会发现一个页面只有一张图片啊!想要下载一套啊!










