AI PC正在GPGPU芯片之上迸发出新的生命力!
智东西3月14日报道,在一年一度的行业大会世界移动通信大会上,PC、手机、机器人等各路终端设备无不与AI深度绑定。
作为全球AI PC龙头的联想亮出了自家系列AI PC解决方案,其产品背后的AzureBlade M.2加速卡正是支持其AI PC体验的关键动力。AzureBlade M.2加速卡就来自国内清华系GPGPU创企珠海芯动力科技。
芯动力成为联想在笔记本电脑dNPU方案领域的首位合作伙伴。
在大模型时代,边缘设备迎来了新的机遇期,春节爆火的DeepSeek更是加速了这一进程,以AI PC、AI手机为代表的诸多硬件连番炸场。
其背后的原因是,大模型对数据处理的实时性、隐私性要求不断提高,边缘设备能够在靠近数据源的地方进行数据处理;边缘设备可承担部分数据预处理和简单推理任务,拓宽应用场景边界;DeepSeek凭借算法优化进一步加速了大模型在边缘设备上的部署与应用进程,让大模型以更低资源消耗在边缘设备高效运行。
这股边缘AI爆发的热潮宛如一把双刃剑,在为行业带来新契机的同时,也
向AI芯片企业抛出了一连串棘手难题,高性能、低延时、低功耗、兼容多种操作系统
……联想与芯动力的合作正是这道难题的最新解法。
边缘AI时代爆发前夜,M.2加速卡的独特优势是什么?其为何能入局AI PC龙头企业联想的产品布局中?我们试图通过拆解芯动力的产品,找到这些问题的答案。
在当下,端侧设备部署大模型的风潮汹涌。然而,这股热潮背后横亘着一个核心命题:端侧设备以及AI芯片是否足以承载大模型所需的性能。
此前,受限于硬件性能和模型技术,端侧部署的模型诸多无法处理复杂任务,这也导致端侧AI应用场景有限,但更靠近用户的端侧设备在保护用户数据隐私方面、实时反馈方面更有优势。
DeepSeek以开源和低成本的特性极大拉低了大模型部署的门槛,使得端侧设备部署更高性能大模型的可能性增强。同时,基于DeepSeek的算法优化策略,使得支持长文本处理等复杂任务的高性能大模型与端侧设备适配,开发者还可以通过蒸馏优化等生成特定场景性能更强的小模型。对于中小企业或者个人开发者而言,能更快速相关端侧AI应用。
随之而来的是,AI手机、AI PC到AI眼镜等加速涌现,端侧AI爆发已成共识。

▲华为、OPPO、荣耀、vivo、小米在手机端部署大模型
然而另一方面,端侧AI的爆发,于AI芯片厂商既是蓬勃发展的难得机遇,也带来了诸多严峻挑战 。
AI在手机、PC、智能穿戴等诸多端侧设备中应用不断拓展,使得AI芯片需求大幅增加,并且由于其设备形态、应用场景多元化,不同场景对芯片需求各异,为芯片厂商提供了更多差异化竞争的机会。
但更为关键的是,AI芯片的性能要符合当下端侧设备的发展趋势,主要集中在性能、功耗、成本、可扩展性上。
包括端侧设备对功耗要求极高,需要芯片兼顾低功耗、高性能,且当下算法和模型仍在不断更新迭代,芯片厂商需要确保芯片高效适配新的模型和算法。此外,端侧设备的厂商对成本更为敏感,芯片厂商需要降低芯片的制造成本、研发成本等,以提高产品的市场竞争力。
以AI PC为例,用户基于其需要处理的生成任务各不相同,文字、图片、视频生成等应用尽有,因此对于计算资源和处理能力的要求也有区别。
▲联想AI PC个人AI助力小天部分功能(图源:联想官方)
这种情况下,以通用计算为核心的计算架构在处理生成任务时可能面临性能有限、效率低下、能耗高、灵活性不足等瓶颈,因此从以通用计算为核心的计算架构向更加高性能的异构AI计算架构升级,成为当下增强端侧设备生成式AI体验的重要路径。
通过让CPU、GPU、NPU等不同计算单元“各司其职”、协同运作,构建高性能异构AI计算架构,便能依据各类生成任务的特性,实现任务的合理分配 。
此外,对于AI芯片而言,在满足性能与功耗等严苛要求的同时,还需提供更高的性价比,才能吸引PC厂商在设备中选用,同时也让终端用户更乐于接受搭载此类芯片的产品。
在这个关键节点,以AI PC为代表的端侧设备正在呼唤相匹配的AI芯片,加速大模型在端侧的繁荣。
就在2025世界移动通信大会(MWC 2025)上,我们看到了AI PC龙头联想和国产AI芯片厂商芯动力联手的成果。
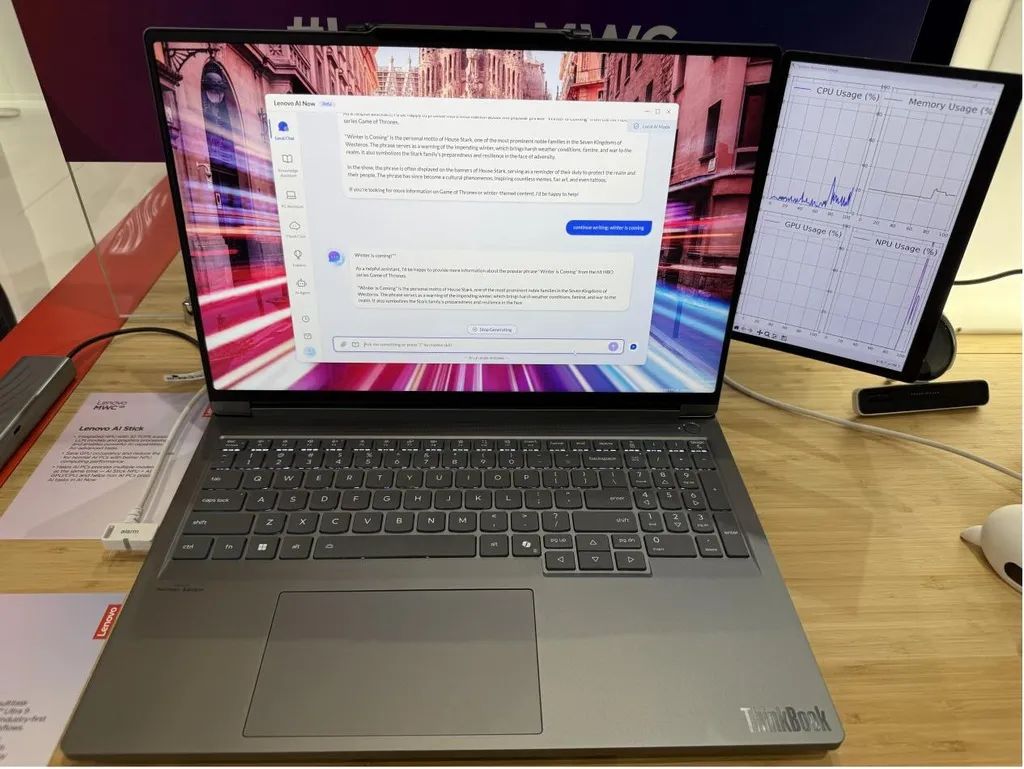
联想全新升级的AI PC系列产品亮相,而支持其AI体验的关键之一,正是芯动力基于可重构并行处理器RPP打造的AzureBlade M.2加速卡。

联想相关负责人在MWC上介绍,联想AI PC实现了将大模型放到本地端推理的突破,尽管传统本地推理大都采用集成(CPU+iNPU)或独立显卡GPU,但经过多重对比发现,在运行大语言模型时,通常依赖GPU进行加速,iNPU只有在特定的场景中才能被调用
。联想AI PC最终采用了芯动力AzureBlade M.2加速卡,并命名为dNPU。M.2加速卡在进行大模型推理时具有高效率、低功耗性能,同时可进一步释放显卡能力,在提高效率的同时更节约能耗。

▲AI NOW不做大模型推理:右侧GPU usage和dNPU占用率均为0%