神经网络在图像处理中应用广泛,但经常面临难以调整参数的问题。最近,来自 Merantix 的 Ryan Henderson(博士毕业于康奈尔大学)等人发布了一个免费开源的卷积神经网络可视化工具,让我们可以方便地观察神经网络在图像中的焦点,为模型优化提供了帮助。
今天,尽管定义与训练深度神经网络(DNNs)比以往任何时候都更加容易,但我们对学习过程的理解仍不甚透明。对训练过程中的丢失或分类错误进行监控并不总能使你的模型避免学习错误信息或是形成预期的分类任务方法。请参考这则故事(很可能是虚构的)来理解这句话的涵义 [1]:
很久以前,美国陆军想利用神经网络来自动检测伪装的敌军坦克。研究人员用 50 张躲在树林中的伪装坦克照片和 50 张没有伪装坦克的树林照片训练了一个神经网络。
研究人员很有先见之明地拍摄了 200 张照片,这两种各自拍摄了 100 张,而每种只有 50 张用于训练集。研究人员用剩下的 100 张照片对神经网络进行了测试,而它将它们全部进行了正确分类。成功了!他们将成果递交至五角大楼,但不久后却被退回,并被抱怨道,在他们进行测试时,神经网络并未在区分照片中展现任何优势。
事实证明,在研究人员的数据集中,伪装坦克的照片是在阴天拍摄的,而树林是在晴天拍摄的,所以神经网络学会的是区分阴天与晴天,而不是区分树林与树林中的伪装坦克。

这绝对是「现代」坦克在训练集中的真实形象。来源:维基百科
抛开故事的真实性不谈,机器学习的研究人员都熟知这一点:训练指标并不总能涵盖全部目的,而此时的风险却比以往都要高:在深度学习越来越多地用于应用程序的今天,这种训练错误可能会是致命的 [2]。
幸运的是,类似局部遮挡 [3] 与显著图 [4] 这样的标准可视化提供了对学习过程的理性检验。用于标准神经网络可视化的工具包 [5] 的确存在,它们与监视训练过程的工具连在一起。如果没有被模型特定化,它们通常会与深度学习框架密切相关。那么,是否存在一个通用且易于设置的工具能够用于生成标准可视化,来将这些研究人员从神经网络区分晴天而非坦克的困境中拯救出来呢?
Picasso
Picasso 是一款免费的开源 DNN 可视化工具(遵循 Eclipse 公共许可证),它能够让你很轻松地获得局部遮挡与显著图。我们在 Merantix 中使用了多种神经网络架构,也开发了 Picasso,以便在各种垂直领域的模型中更易于查看标准可视化,包括在汽车中的应用(如了解道路分割或物体识别时的失败)、在广告中的应用(如了解某些广告能够获得更高点击率的原因)以及在医学成像中的应用(如分析 CT 或 X 射线图像中哪些区域具有不规则性)。
Picasso 是一个 Flask 应用程序,它能够将深度学习框架与一组存在默认值且可被用户定义的可视化内容结合在一起。你可以使用其内置的可视化功能,也可以轻松进行自定义添加。Picasso 被开发用于 Keras 和 Tensorflow 神经网络的检查点。若你想进行验证却苦于没有经过训练的模型,我们为你提供了 Tensorflow 和 Keras 的 MNIST 检查点以及 Keras 的 VGG16 检查点。
使用默认设置对应用程序流程进行概述。用户已经加载了在 MNIST 数据集中经过训练的 Keras 模型,并在几张手写数字的图像上生成了局部遮挡可视化。有关遮挡图的深入解释参见下文。
在 Merantix 中,我们尤其感兴趣于卷积神经网络(CNN),它们将图像作为输入并进行分类。我们根据这些参数开发了 Picasso,但这个框架十分灵活,足以用于所有其他模型中。尽管所包含的可视化应当在不同的神经网络之间都足够稳固,但如果你愿意,仍然可以实现模型特定的可视化。
我们提供了几个开箱即用的标准可视化:
1. 局部遮挡:对图像的一部分进行了遮挡,以查看分类如何变化。
2. 显著图:计算输入图像的类型预测的导数。
3. 类型预测本身并非可视化,但它可以简便地对学习过程进行检查。
并且我们还有其他的成果!
应用于实践中的 Picasso
我们来用 Picasso 的两个内置可视化能力来处理本文开头的坦克问题:局部遮挡与显著图。在这些例子中,我们将使用预训练的 VGG16 模型进行分类。已知该模型很擅长进行坦克分类,所以能否使用这些可视化来查看模型是不是真正根据是否存在坦克,而非天空进行分类?
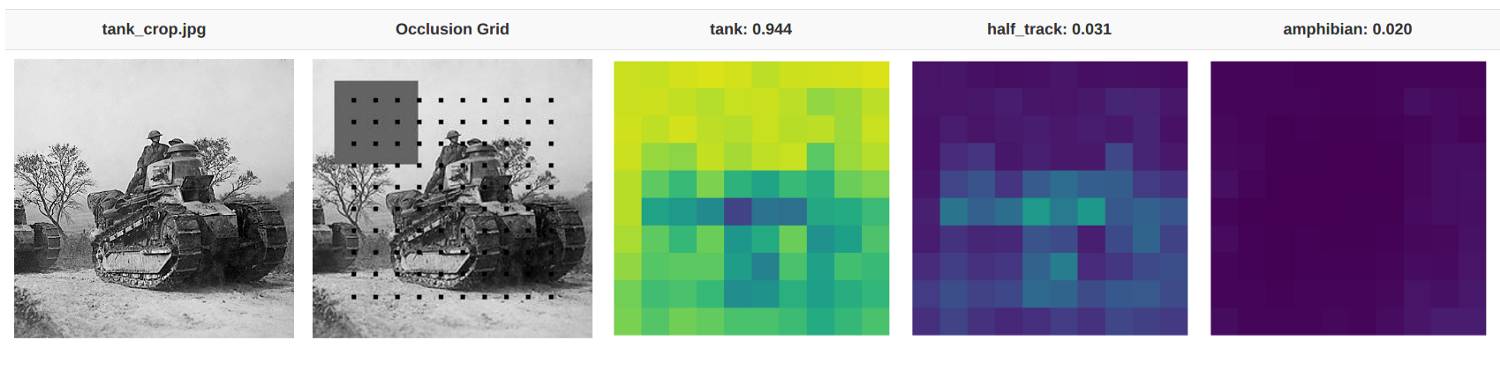
通过依次遮挡图像的各个部分,我们可以判断哪些区域在分类中更为重要。该图像由 VGG16 模型进行分类,具有 94%的正确分类概率。图像中较亮部分的分类概率更高。例如,天空那部分区域很亮,因为遮挡天空并不影响其被分类为存在坦克的概率。相反,坦克的胎面区域更暗,因为若这些区域不存在,模型将难以明确所看到的是否为坦克。
我们能看出这种可视化可能如何帮助军队:当「坦克性」的部分(如坦克的胎面)丢失时,模型将无法成功分类。而有趣的是,当一部分胎面被遮挡时,图像更可能被分类为半履带车。直观而言,这么分类存在一定的道理,因为半履带车的前半部分是车轮。

除非你标出全部车轮,否则这个模型很肯定这就是半履带车;除非你将车轮遮挡,否则它也会很肯定这不是坦克。图像来源:维基百科
除了局部遮挡,我们还提供开箱即用的显著图。显著图可以通过反向传播查看分类中输入图像的导数。在给定像素处的高导数值则意味着更改该像素能更大程度上影响分类结果。

坦克的显著图。更亮的像素表明该「坦克」图像的输入像素具有更高的导数值。而好的预兆是,最亮的像素似乎处于图像的坦克区域。请注意,绝大多数非坦克区域都是暗的,仅有少数例外,这意味着改变这些像素不应改变图像的「坦克性」。
添加可视化
我们希望新的可视化能够很容易被整合。而你只需要将可视化代码放在可视化文件夹中,再绘制一个 HTML 模板来显示即可。
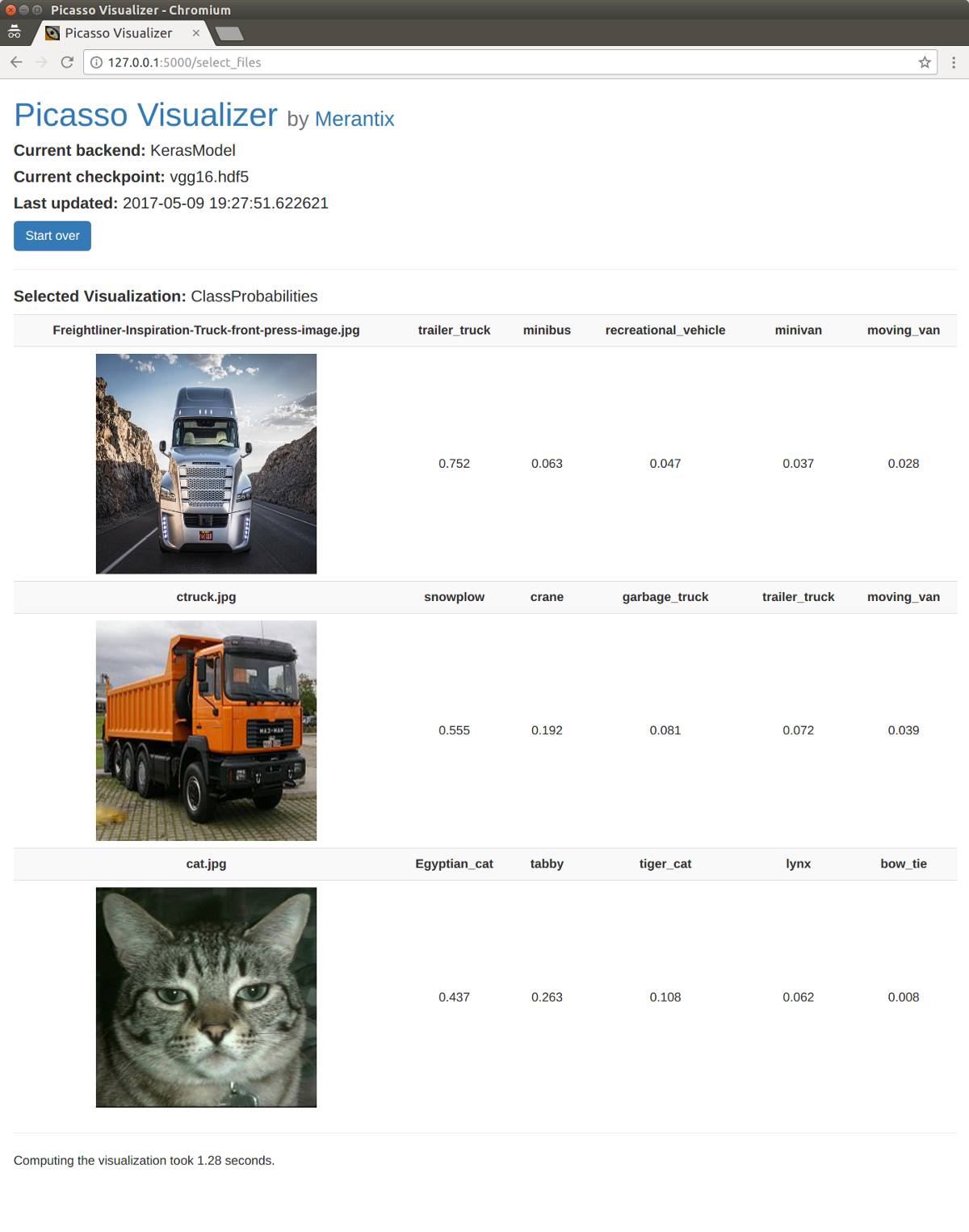
若想查看如何构建简单的可视化示例,请参阅 ClassProbabilites 可视化教程。
系统给出的相对分类概率与你可做出的最简单的可视化有关。
使用你自己的模型
当然,你将会使用已包含的可视化与经过训练的神经网络。我们已将其尽量简化,但你至少应定义三种方法:
1. 预处理:告知可视化如何将上传的图像转变为神经网络输入
2. 后处理:告知可视化如何将扁平的中间层变为图像尺寸(这是在中间层操作的可视化所需的,例如显著图)
3. decode_prob:通过用类型名称进行注释,来告知可视化如何解释原始输出(通常为概率数组)
本教程详细介绍了如何构建这些功能,而它们可以独立于应用程序的源代码之外进行指定。
显著图可视化的结果。这个应用程序正在使用具有 VGG16 模型的 Keras 框架。这个示例预包装了代码。由于显著图取决于输入层中关于中间层的导数,因此必须告知可视化如何使用`decode_prob`重塑输出张量并生成图像。
贡献
我们欢迎任何与改善构建此应用程序有关的建议。若你想要贡献可视化功能或其他资料,那再好不过了!请查阅我们的 Github 存储库了解更多信息。我们遵循 EPL 来发布 Picasso,因为我们打算让它归入 Eclipse 基金会旗下。

参考文献
1. Yudkowsky, Eliezer.「Artificial Intelligence as a Positive and Negative Factor in Global Risk.」Global Catastrophic Risks, edited by Nick Bostrom and Milan M. Ćirković, 308–345. New York: Oxford University Press. 2008.
2.「Tesla Driver Killed In Crash With Autopilot Active, NHTSA Investigating」. The Verge. N.p., 2017. Web. 11 May 2017.
3. Zeiler, Matthew D., and Rob Fergus.「Visualizing and understanding convolutional networks.」European conference on computer vision*. Springer International Publishing, 2014.
4. Simonyan, Karen, Andrea Vedaldi, and Andrew Zisserman.「Deep inside convolutional networks: Visualising image classification models and saliency maps.」ICLR Workshop, 2014.
5. Yosinski, Jason, et al.「Understanding neural networks through deep visualization.」 Deep Learning Workshop, International Conference on Machine Learning (ICML), 2015.
点击阅读原文,查看全部嘉宾阵容并报名参与机器之心 GMIS 2017
↓↓↓






