作为全球半导体行业多年的老大,英特尔(
Intel
)在制造工艺技术层面无疑是具有统治力的。但市场变化风起云涌,即使是行业老大,也有跟不上趟的时候。面对越来越激烈的竞争,压力在不断增加,再不能像十几年前那样稳坐钓鱼台了。
半个世纪以来,
Intel
的半导体制造工艺技术只为自家服务,然而,这位一直高高在上的老大(技术确实牛,不服不行),在最近
5
年态度发生了变化,特别是在收购
Altera
前后那段时间,
Intel
也开始做晶圆代工业务了,这完全是由市场发展变化以及竞争造成的,谁也躲不过这个宿命,
Intel
也不例外。

因此,就在昨天,这位行业老大破天荒地、第一次在中国举行了一次规格和规模都较高的半导体制造工艺技术和晶圆代工高峰论坛。这样的活动,即使是在全球范围内,也是
Intel
第二次搞,可见其对晶圆代工,以及中国市场的重视。
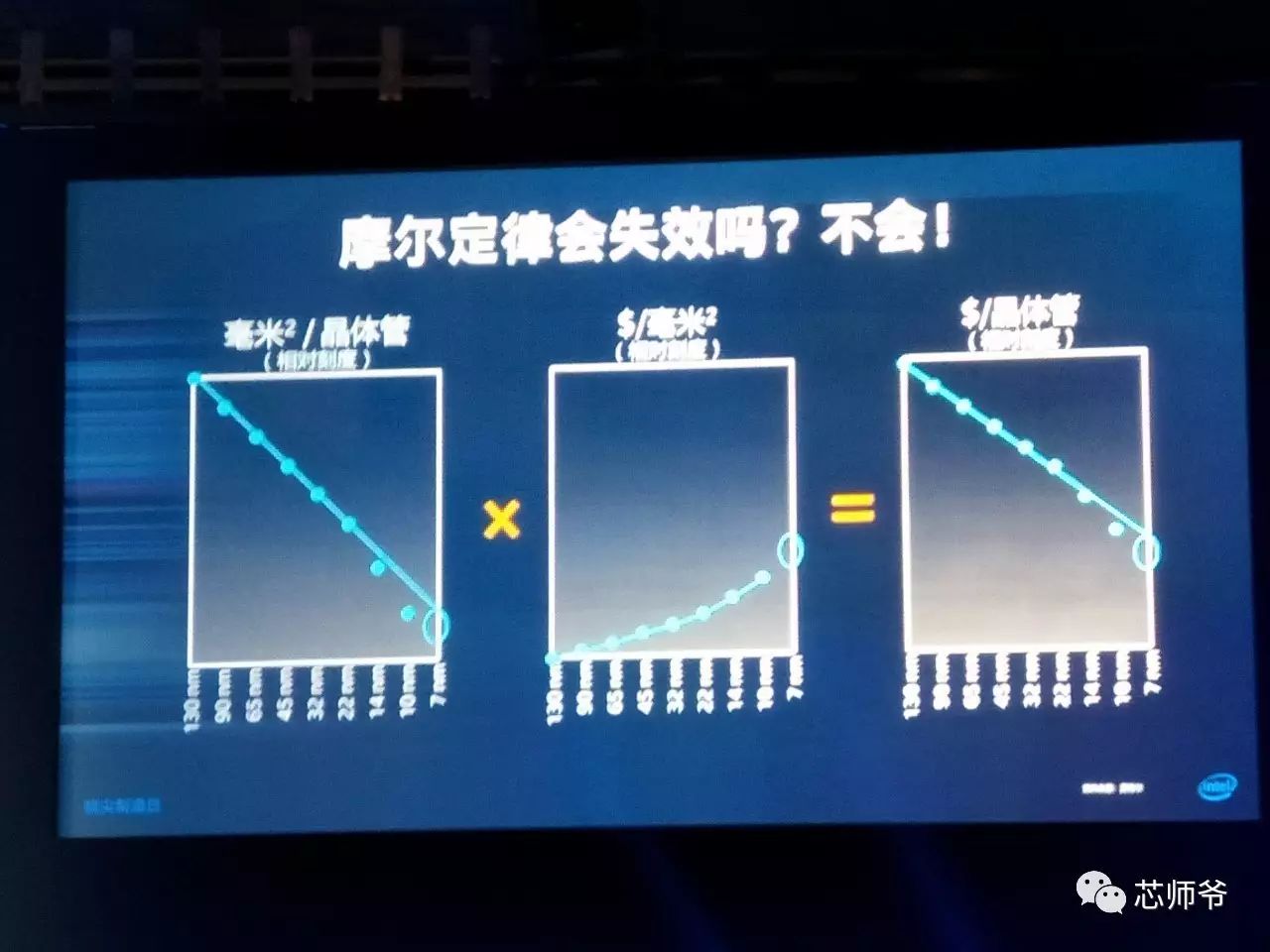
摩尔定律的宿命
Intel
是摩尔定律的发源地,也是该公司最为引以为豪之处。发展了这么多年,遇到了各种各样的挑战,前进的难度也越来越大,因此,各种对该定律的质疑声此起彼伏。
Intel
自然要坚定地捍卫摩尔定律,就像该公司执行副总裁兼制造、运营与销售集团总裁
Stacy Smith
表述的那样,摩尔定律不会失效,它还在前进,而
Intel
则正在
14nm
和
10nm
工艺上用超微缩技术(
hyper scaling
),晶体管密度提升了
2.7
倍,进一步延续摩尔定律继续前进。
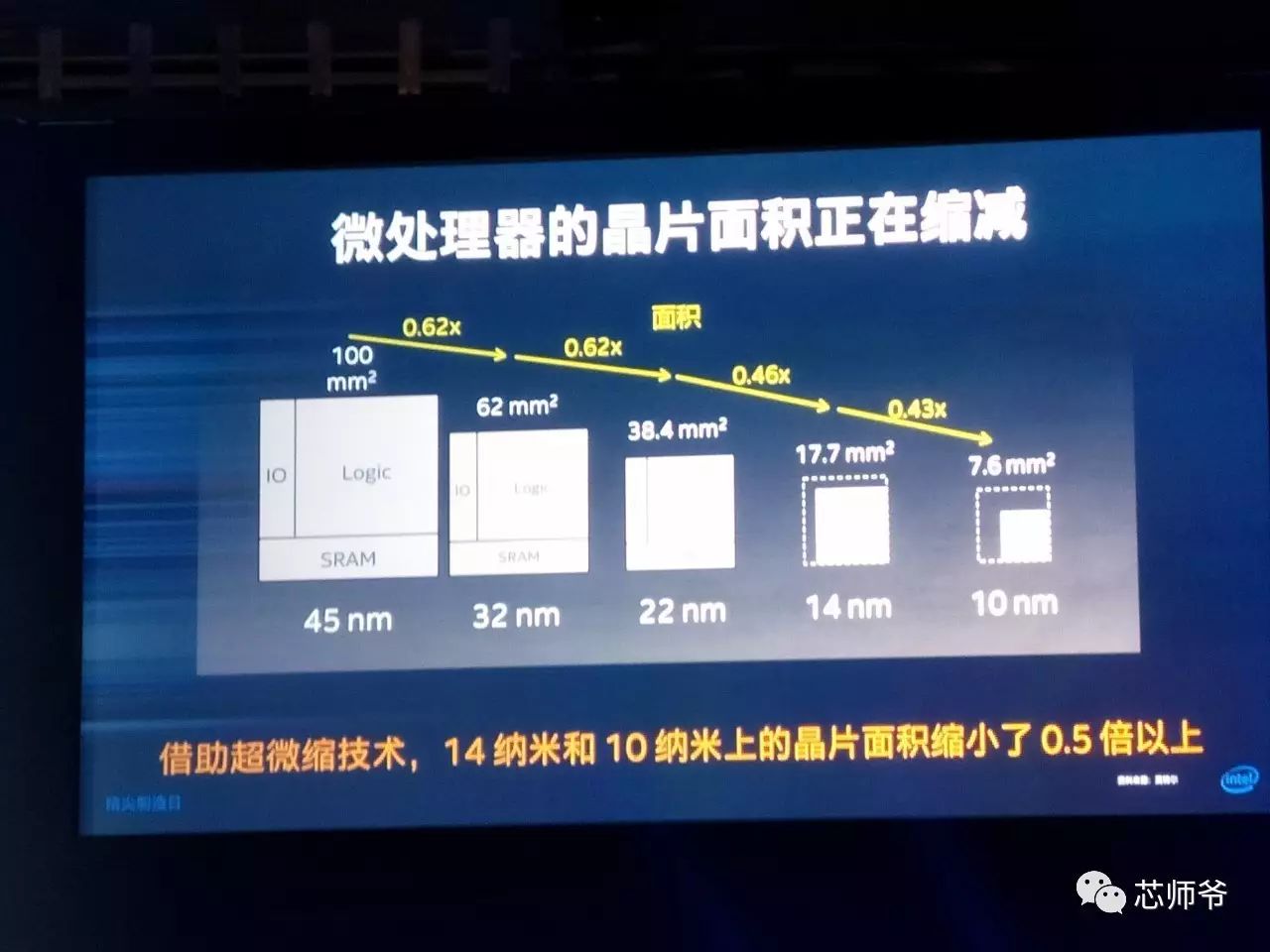
借助超微缩技术,
14nm
和
10nm
晶圆面积缩小了至少
50%
。
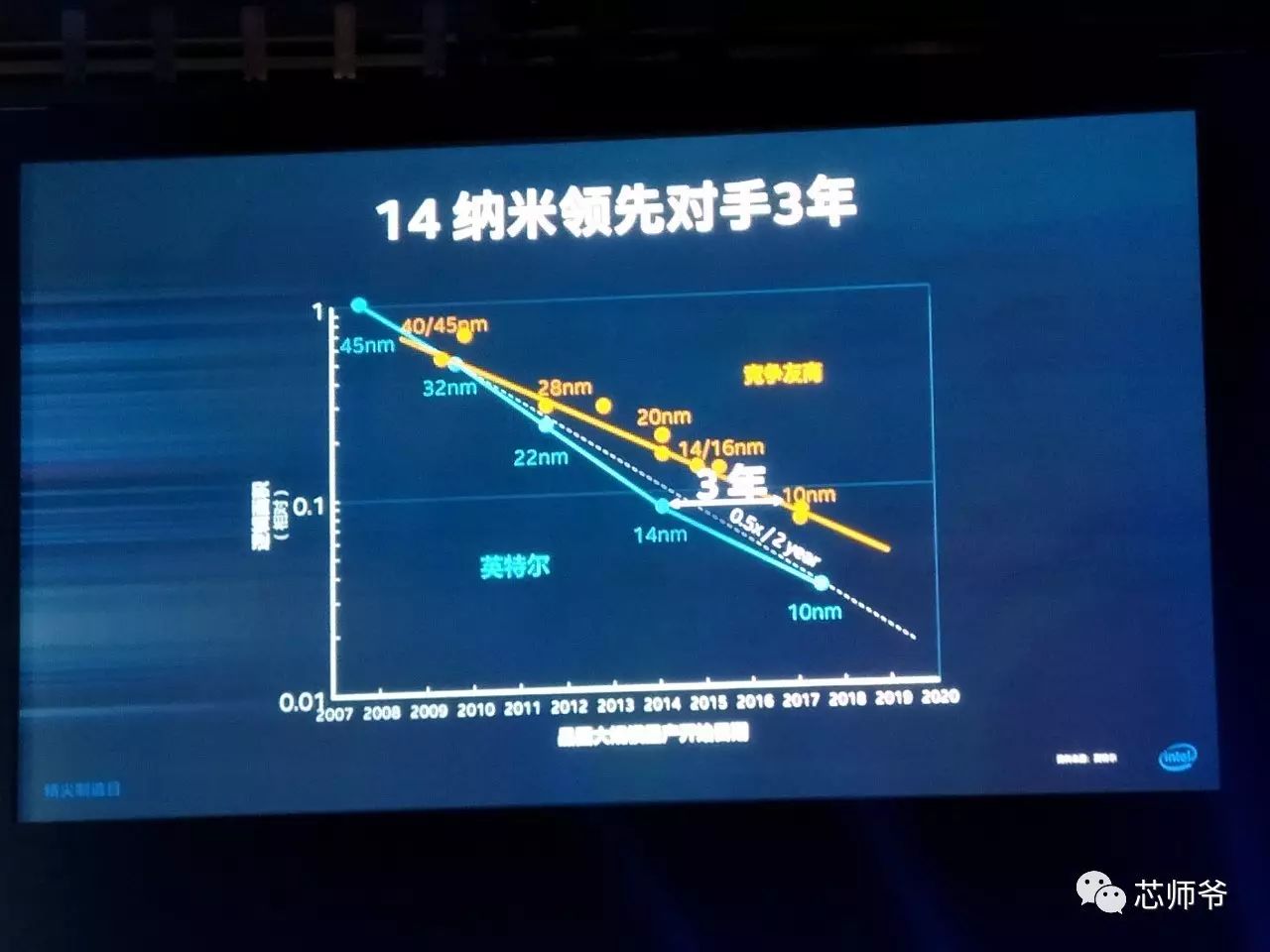
14nm
领先对手
3
年
。
Stacy Smith
表示,一些竞争友商公司的制程节点名称并不准确,无法正确体现这个制程位于摩尔定律曲线的哪个位置。摩尔定律是指每一代制程工艺的晶体管密度加倍,纵观发展史,业界在命名新制程节点时会比上一代缩小
30%
,这种线性缩放意味着晶体管密度提高一倍,是符合摩尔定律的。近来,也许是因为进一步的制程升级越来越难,一些竞争友商公司背离了摩尔定律的法则,即使晶体管密度增加很少,或者根本没有增加,但他们仍继续推进采用新一代制程节点命名。
Stacy Smith
认为,相比于业界其他竞争友商的
16/14
纳米制程,英特尔
14
纳米制程的晶体管密度是他们的约
1.3
倍。业界其他竞争友商“
10
纳米”制程的晶体管密度与英特尔
14
纳米制程相当,却晚于英特尔
14
纳米制程三年。
因此,在
Stacy Smith
看来,
英特尔
10
纳米晶体管密度是其他竞争友商“
10
纳米”的
2
倍。
英特尔
10
纳米制程采用第三代
FinFET
技术,晶体管密度达到每平方毫米
1.008
亿个晶体管,是之前英特尔
14
纳米制程的
2.7
倍,是业界其他竞争友商“
10
纳米”制程的约
2
倍。据悉,台积电
10
纳米制程每平方毫米为
4,800
万个晶体管,三星为
5,160
万个。
首次发布
10nm
工艺产品
昨天,英特尔
“
Cannon Lake
”
10
纳米晶圆全球首次公开亮相,并展示了
5
款晶圆,分别是:
10
纳米
Cannonlake
,
10
纳米
ARM
测试芯片,英特尔
22FFL
,
14
纳米展讯
SC9861G-IA
,以及
14
纳米展讯
SC9853
。
据悉,
Cannonlake 10
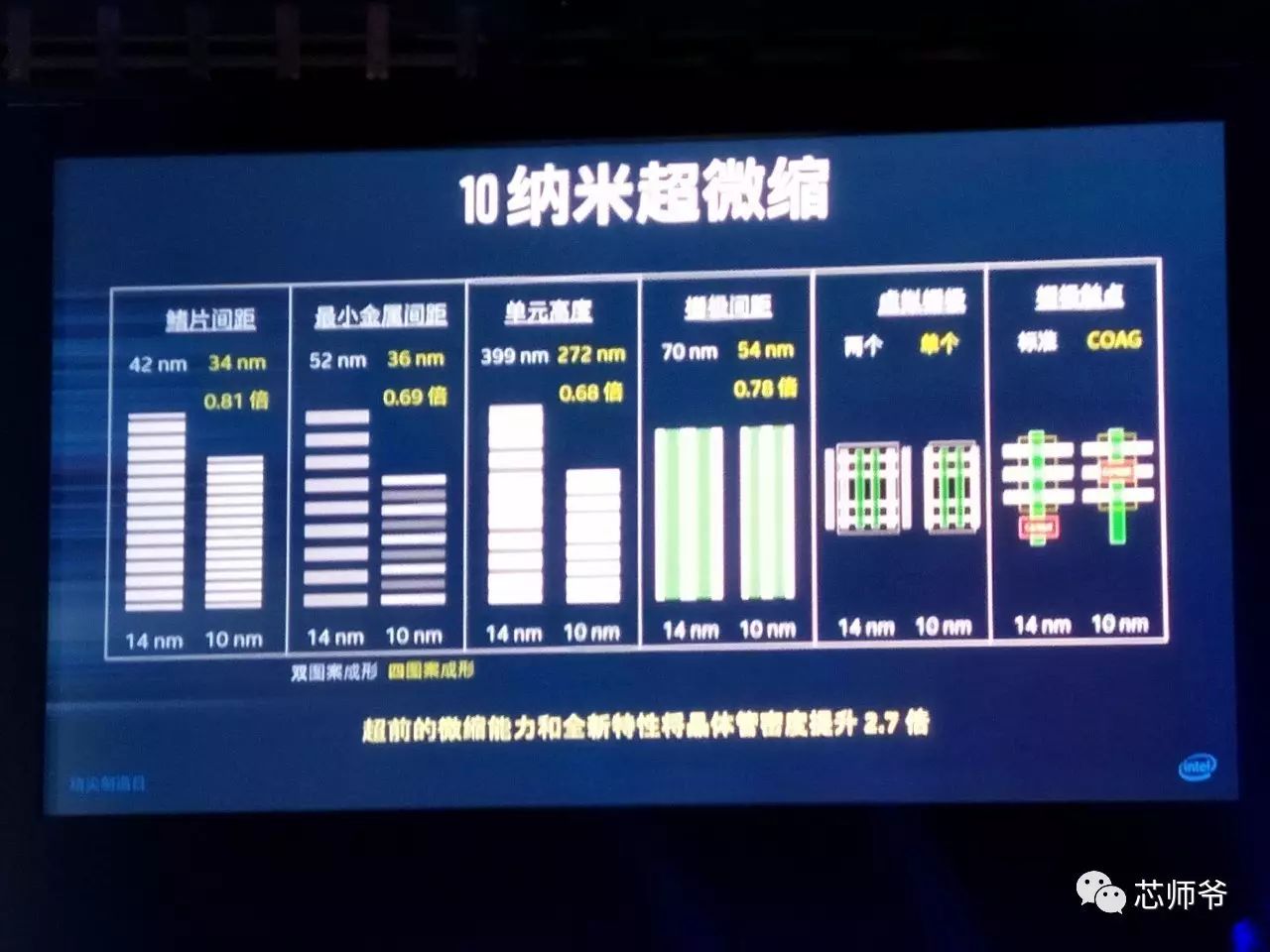
纳米产品,拥有全球最密集的晶体管和金属间距,采用了超微缩特性,保证了密度的领先性。

该产品采用了第三代
FinFET
(鳍式场效应晶体管)技术,其使用的超微缩技术,充分运用了多图案成形设计
(multi-patterning schemes)
,从而推出体积更小、成本更低的晶体管。英特尔
10
纳米制程将用于制造其全系列产品,以满足客户端、服务器以及其它各类市场的需求。

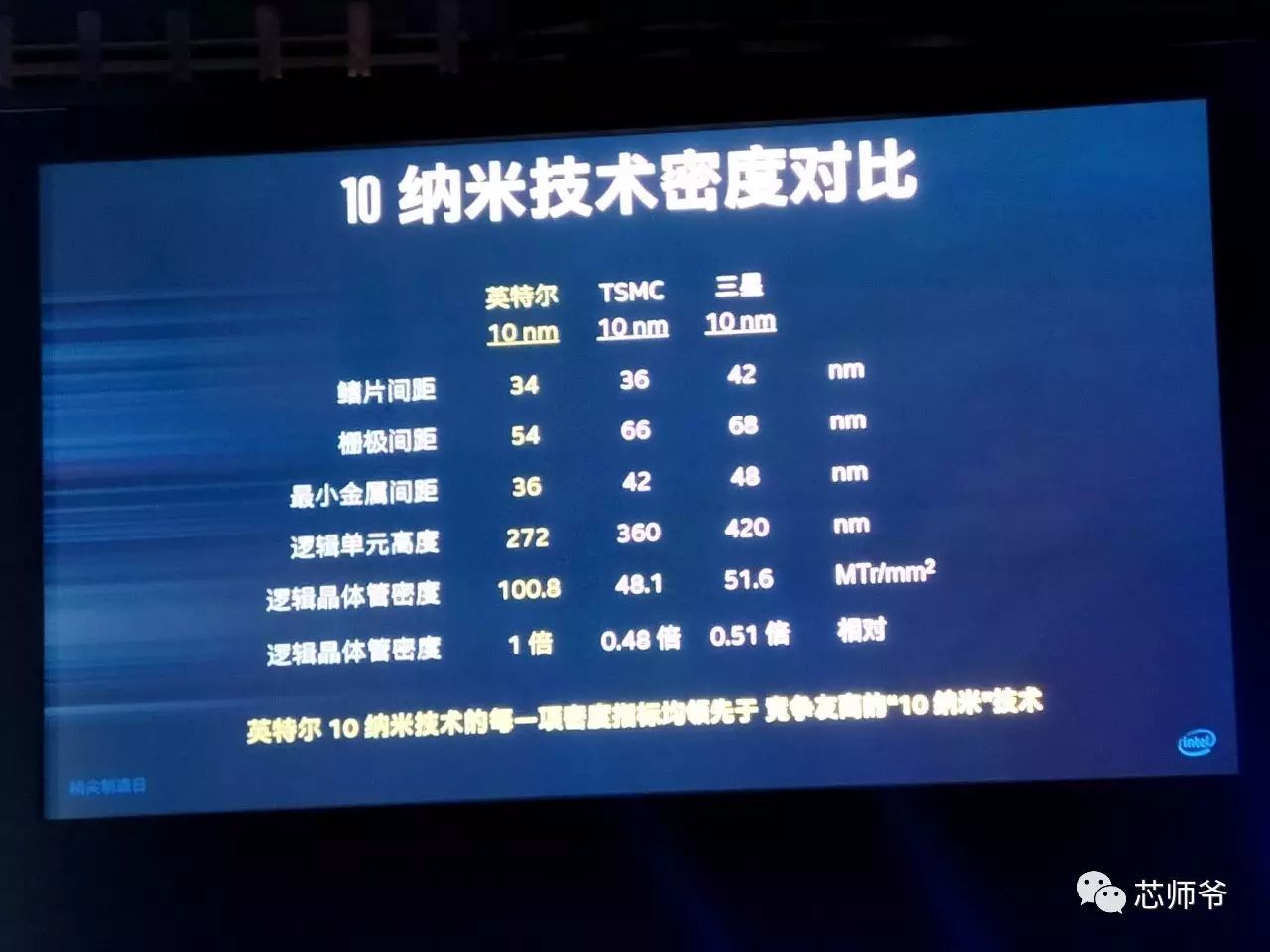
英特尔
10
纳米制程的最小栅极间距从
70
纳米缩小至
54
纳米,且最小金属间距从
52
纳米缩小至
36
纳米。尺寸的缩小使得逻辑晶体管密度可达到每平方毫米
1.008
亿个晶体管,是之前英特尔
14
纳米制程的
2.7
倍,大约是业界其他“
10
纳米”制程的
2
倍。
以下是英特尔10nm技术密度,与台积电和三星10nm的对比情况:
下边是英特尔10nm与台积电和三星10nm的性能和功耗对比情况:
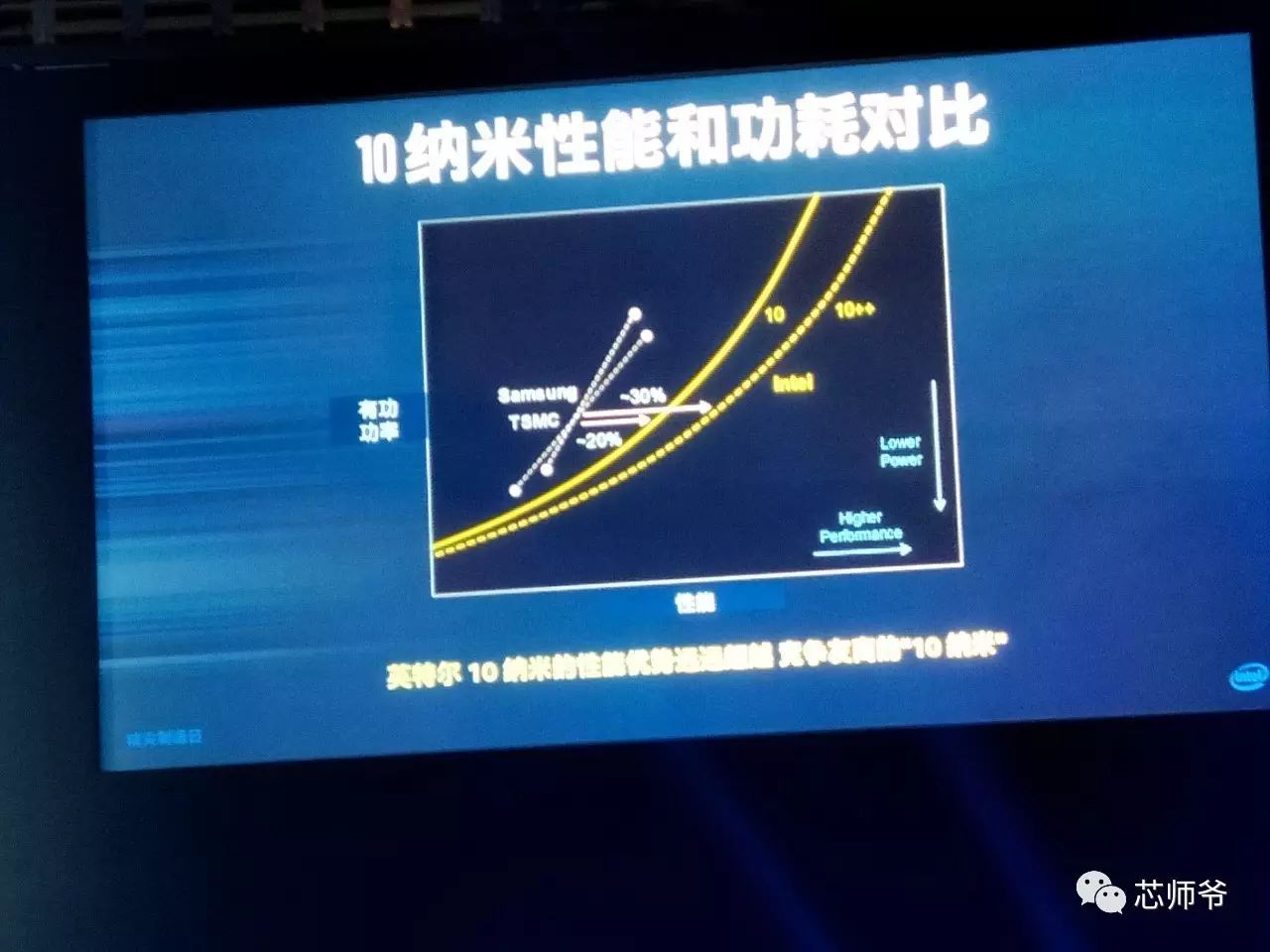
该公司表示,其
10
纳米制程计划于
2017
年底投产,
2018
年上半年实现量产。
此次,英特尔还发布了首款面向数据中心的
64
层
TLC 3D NAND
固态硬盘产品,该产品从
8
月初开始向部分顶级云服务提供商发货。

英特尔的
14nm
和
10nm
工艺到底强在哪里
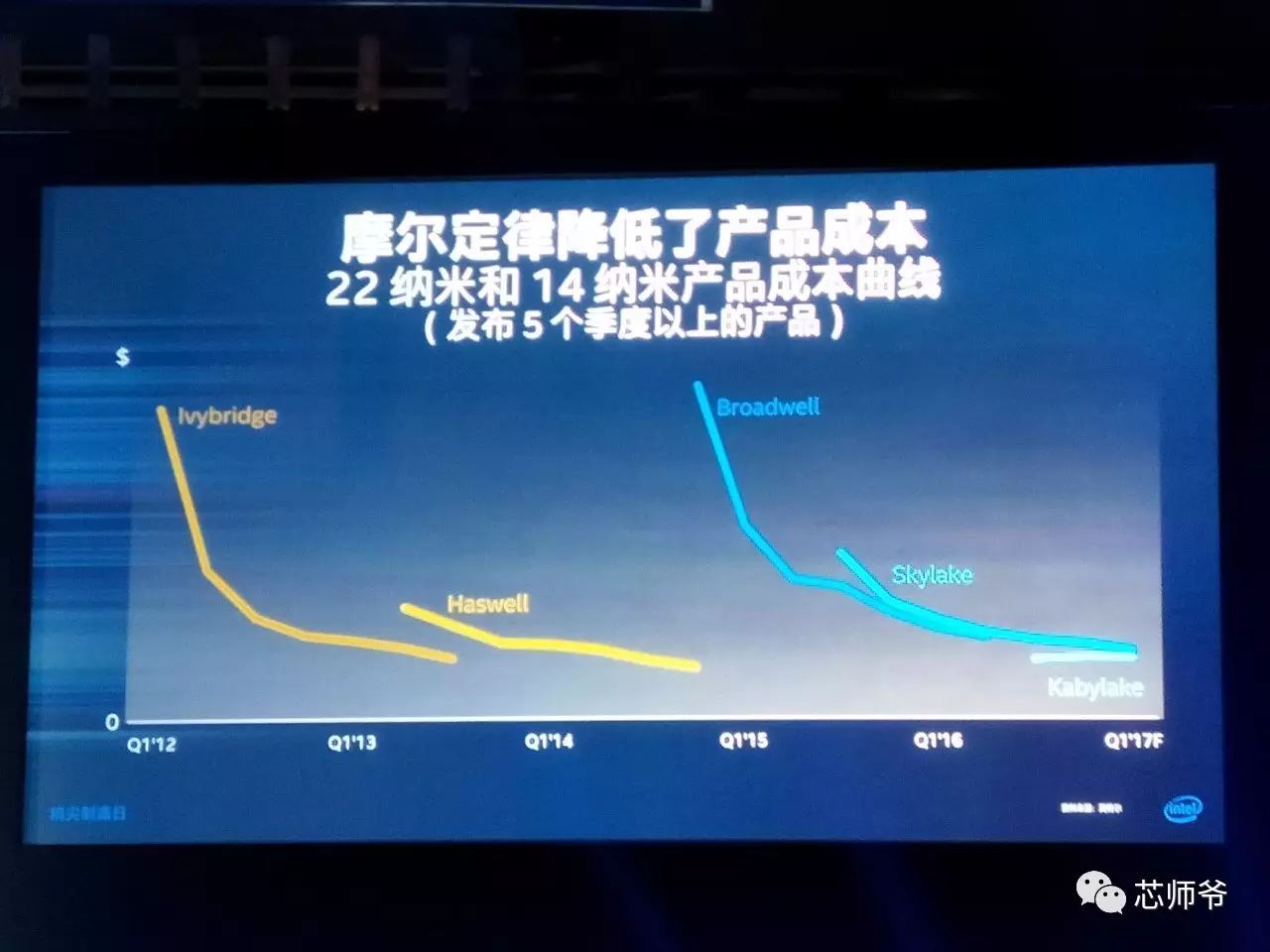
单从技术角度看,英特尔的制造工艺水平确实是最强的,这一点也是多数业界同仁的普遍看法。但由于台积电和三星已经做了很多年的晶圆代工业务,形成了相应的生态系统,而这方面则是英特尔的弱项,毕竟其代工业务起步不久,要想拓展,与对手竞争,还有很长的路要走。
放下生态系统先不谈,我们来看一下英特尔的
10nm
和
14nm
制造工艺到底是什么样的。
关于制程工艺的命名,英特尔认为业界对手并不规范,没有体现出摩尔定律。对此,该公司的高级院士、技术与制造事业部制程架构与集成总监
Mark Bohr
表示,晶体管密度是衡量制程工艺领先性的首要准则。英特尔提出的指标是基于标准单元的晶体管密度,包含决定典型设计的权重因素,从而得出一个之前被广泛接受的晶体管密度公式:

这个公式可用于任何制造商的任何
晶圆
,且已被业界广泛使用,它能够明确、一致地测量晶体管密度,并为芯片设计者和客户提供关键信息,准确比较不同制造商的制程。通过采用这个指标,业界可以改变制程节点命名的乱象。
英特尔
14
纳米制程采用第二代
FinFET
技术,
其晶体管鳍片更高、更薄且更加密集,从而提升了密度和性能。这些改进的晶体管需要的鳍片数量更少,进一步提升了制程的总体密度。
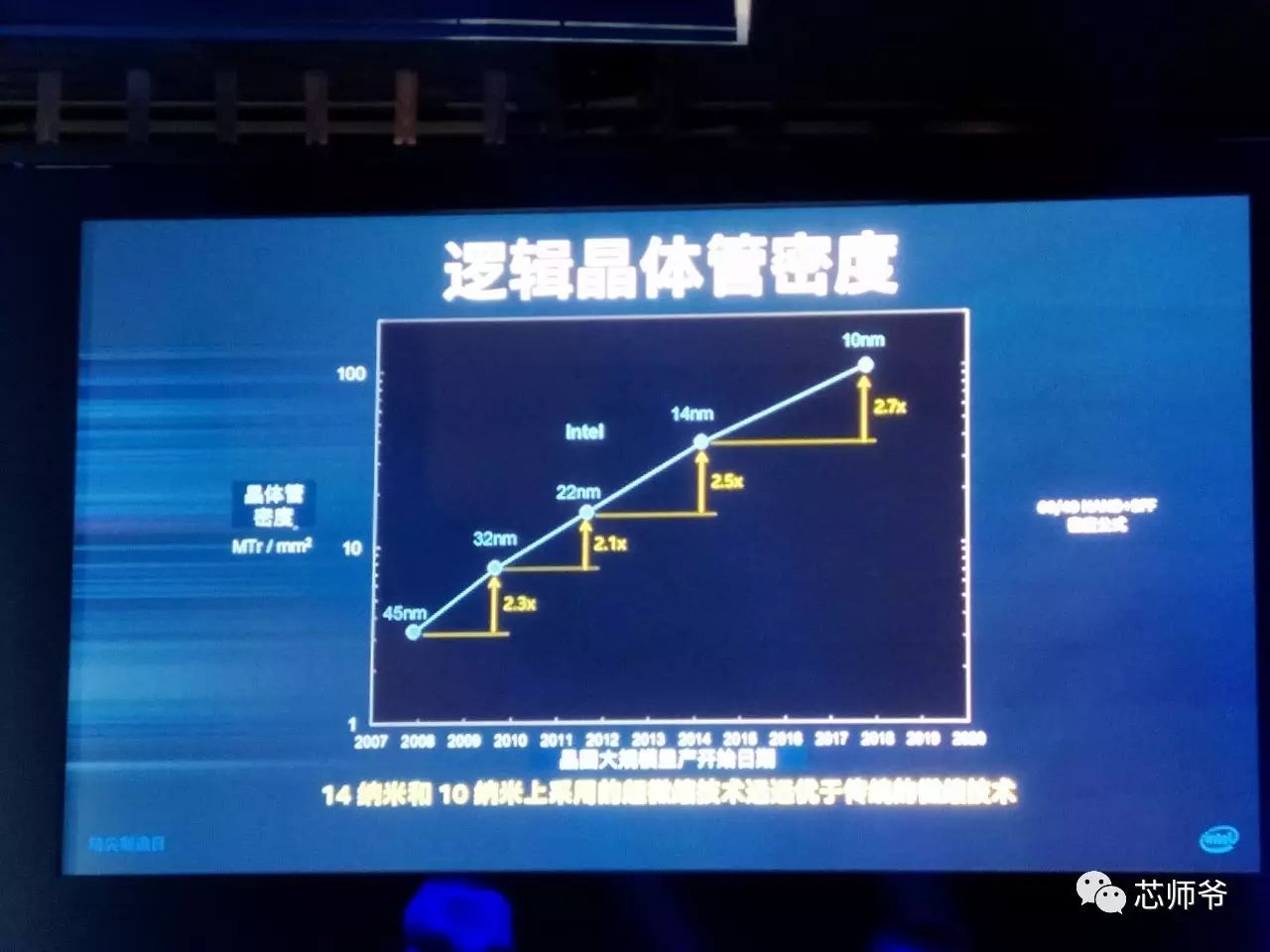
晶体管栅极间距从
90
纳米缩小至
70
纳米,最小互连间距从
80
纳米缩小至
52
纳米,从而让晶体管密度到达每平方毫米
3,750
万个晶体管的标准。通过采用超微缩技术,
14
纳米制程相比之前的
22
纳米,实现了显著的微缩,其中逻辑单元面积微缩为此前的
37%
,晶片尺寸微缩超过此前的一半。
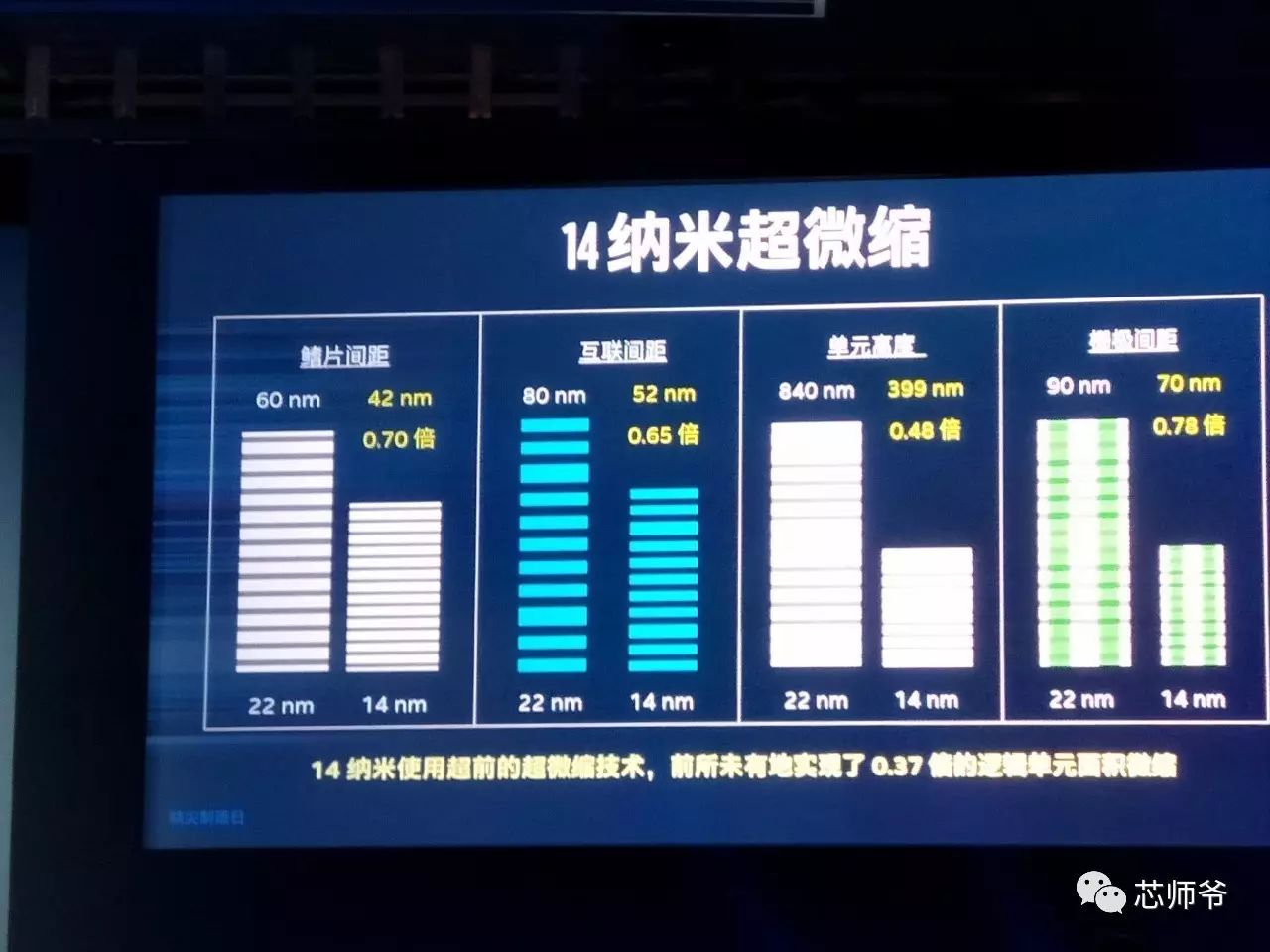
Mark Bohr
表示,相比于业界其他的
14/16/20
纳米制程,英特尔
14
纳米制程的密度是它们的约
1.3
倍,这极大降低了单个晶体管成本(
CPT
)。业界友商的“
10
纳米”制程预计于
2017
年的某个时段出货,而其晶体管密度仅与
2014
年便已开始出货的英特尔
14
纳米制程相当。
14
纳米制程超微缩的一个关键因素是引入自校准双图案成形
(SADP)
,相比业界的曝光
-
蚀刻
-
曝光
-
蚀刻
(LELE)
方法,它在晶体管密度和良品率上更有优势。
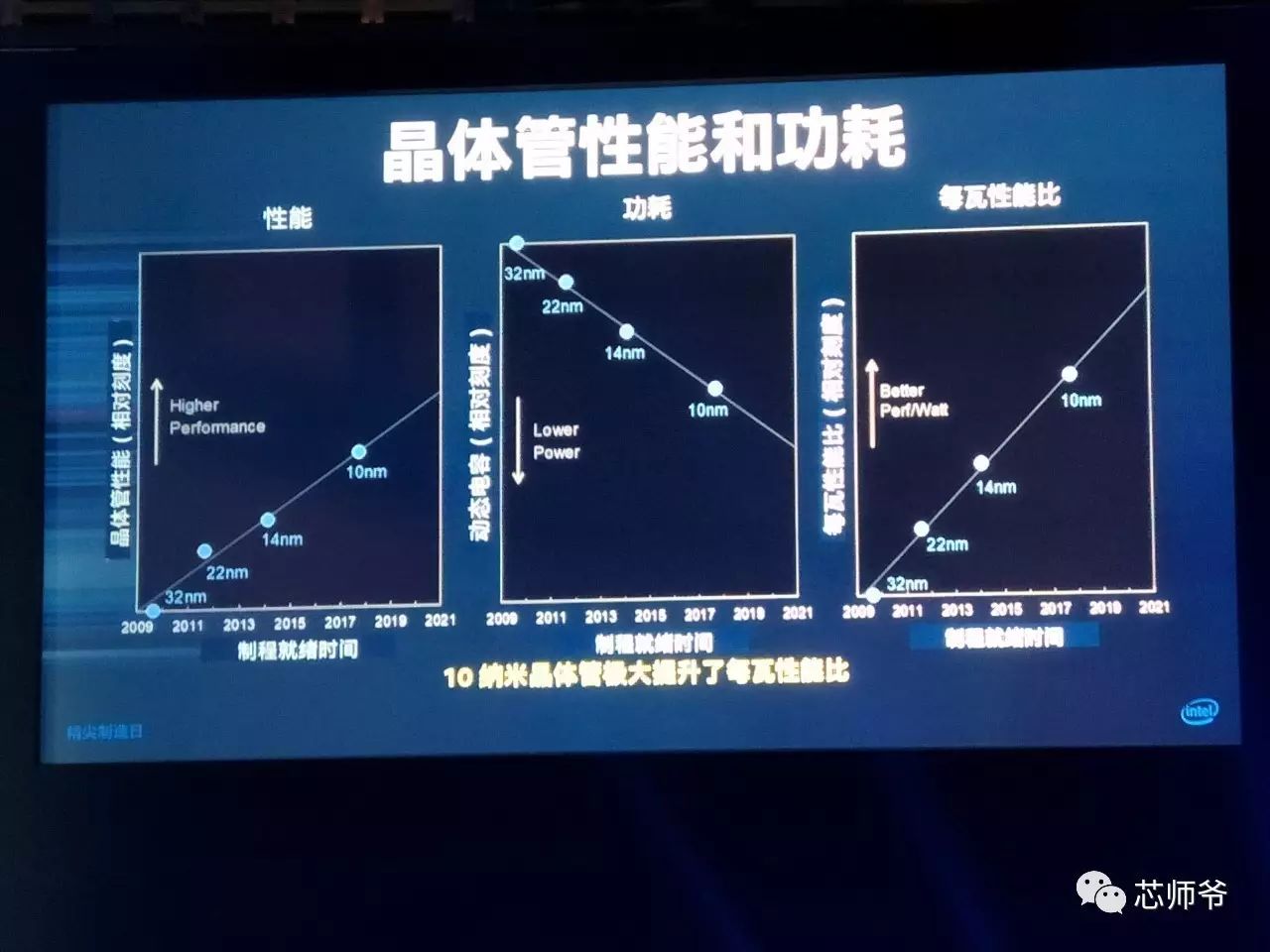
14
纳米制程的持续优化使其性能比最初的
14
纳米制程可以提升多达
26%
,也可以在相同性能下降低
50%
以上的有效功耗。英特尔
14+
制程的性能比最初的
14
纳米制程提升了
12%
,而英特尔
14++
制程在此基础上又将性能提升了
24%
。
COAG
(
Contact Over active gate
)技术,可进一步缩小面积。

虚拟栅极技术。

以下是该公司10nm晶体管的性能和功耗情况:
为低功耗物联网定制的22FFL
此次,除了推出
10nm
晶圆外,另一大看点,就是
22FFL
(低功耗
FinFET
)平台。
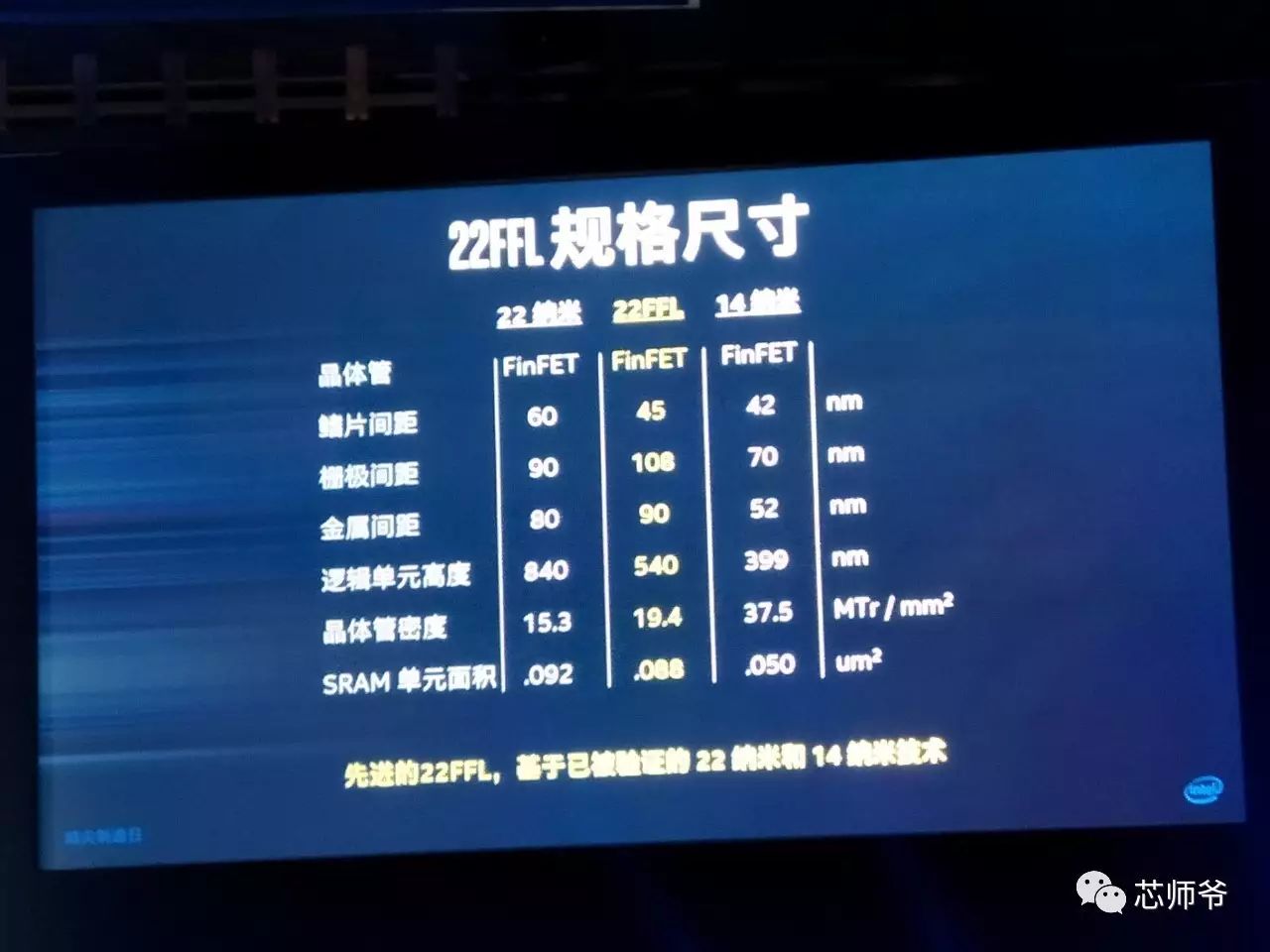
22FFL
是英特尔专门面向低功耗物联网和移动产品的
FinFET
技术,如入门级
/
经济型智能手机、车载电子产品和可穿戴设备。它基于该公司的
22
纳米
/14
纳米制程,提供性能、功耗、密度和易于设计等优势。
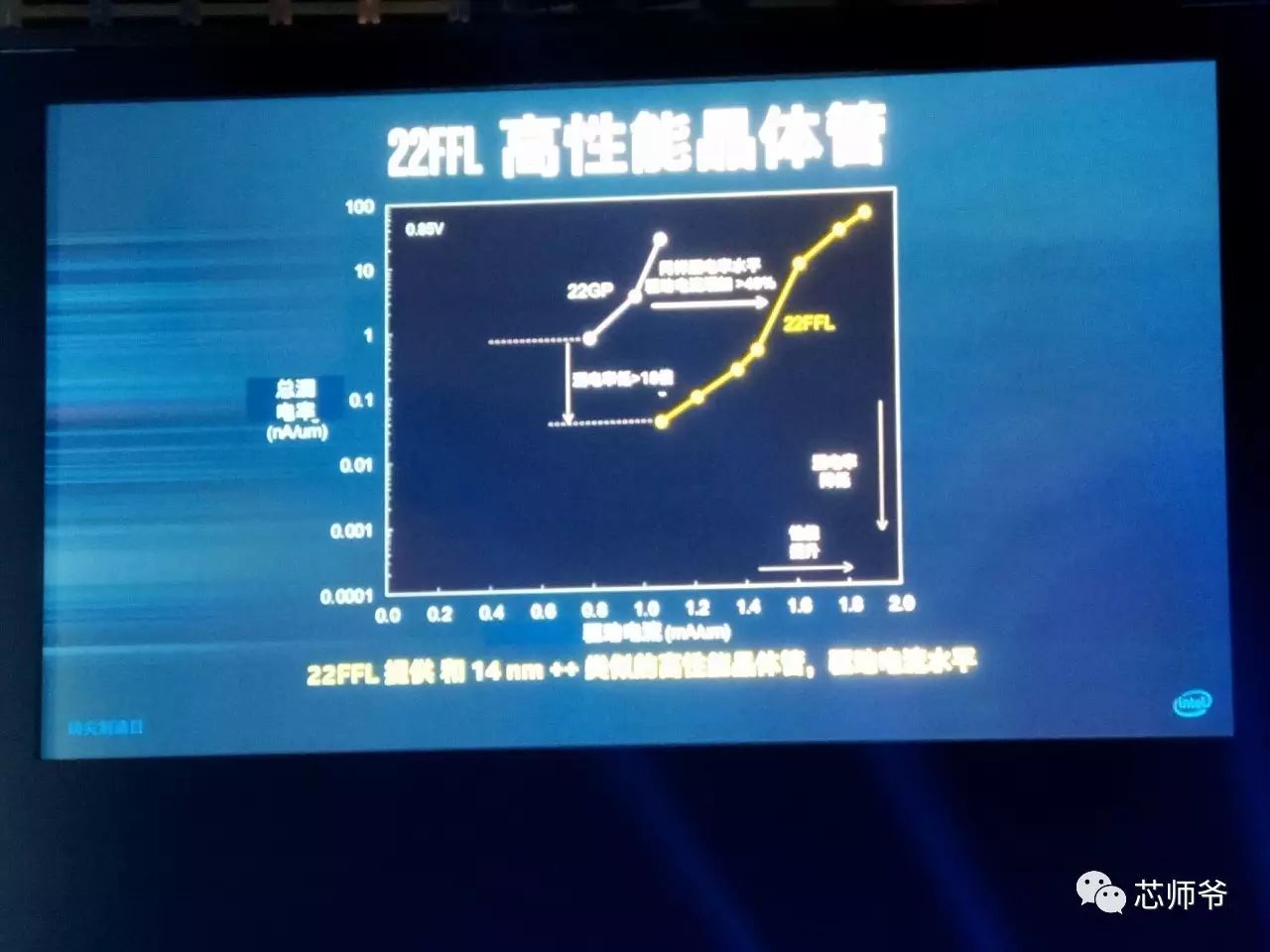
Mark Bohr
表示,与先前的
22GP
(通用)制程相比,
22FFL
的漏电量最多可减少
100
倍。
22FFL
可提供与
14
纳米制程晶体管相媲美的驱动电流,同时实现比业界
28
纳米制程更高的面积微缩。

22FFL
工艺包含一个完整的射频(
RF
)套件,并结合多种先进的模拟和射频器件来支持高度集成的产品。通过采用单一图案成形及简化的设计法则,使
22FFL
成为价格合理、易于使用可面向多种产品的设计平台,与业界的
28
纳米的平面工艺
(Planar)
相比在成本上极具竞争力。
能将
FinFET
技术做成低成本方案,英特尔确实有一套!不过,还是那句老广告词,不看广告,看疗效!不知道
22FFL
是否真的如英特尔所描述的那样,有如此好的性能和成本优势,一切还得经过市场检验才能知道。
ICF
能否广为流传?
英特尔代工业务的缩写是
ICF
(
Intel Custom Foundry
),不知道在不久的将来,
ICF
是否会成为该公司又一个标志性的代号,一切还要看其业务拓展情况。
对于该部分业务,该公司技术与制造事业部副总裁
英特尔晶圆代工业务联席总经理
Zane Ball
表示,其晶圆代工业务通过两个设计平台——
10GP
(通用平台)和
10HPM
(高性能移动平台),向客户提供
10
纳米制程。这两个平台包括已验证的广泛硅
IP
组合、
ARM
库和
POP
套件,以及全面整合的一站式晶圆代工服务和支持。

本次活动上,英特尔公布了采用其
10
纳米制程工艺和晶圆代工平台的下一代
FPGA
计划——研发代号为“
Falcon Mesa
”的
FPGA
产品,以支持数据中心、企业级和网络环境中日益增长的带宽需求。

此外,英特尔加强了与
ARM
的合作,并做了重点介绍。这两家公司宣称在
10
纳米制程合作方面取得了重大进展。
在
2016
年
8
月于旧金山举行的英特尔信息技术峰会(
IDF
)上,其晶圆代工宣布与
ARM
达成协议,双方将加速基于英特尔
10
纳米制程的
ARM
系统芯片开发和应用。作为这一合作的结晶,此次,这两家公司全球首次展示了
ARM Cortex-A75 CPU
内核的
10
纳米测试芯片晶圆。这款芯片采用行业标准设计流程,可实现超过
3GHz
的性能。

对此,
Zane Ball
表示,英特尔
10nm CPU
测试芯片具有先进的
ARM
核,使用行业标准的设计实现
,
。
与此同时,
ARM
也在开发高性能存储器、逻辑单元和
CPU POP
套件,以进一步扩展下一代
ARM CPU
在英特尔
10nm
技术上的性能水平。
在本次峰会上,展讯
CEO
李力游博士也到场助阵了。因为英特尔与展讯在最近这今年走得越来越近,合作甚为紧密。

英特尔用其
14nm
技术平台,为展讯重点代工了两款芯片,分别是
SC9861G-IA
和
SC9853I
移动
AP
。这两款移动
AP
分别于
2017
年
3
月和
8
月推出,使用了英特尔
Airmont CPU
架构。

李力游还提到了苹果刚刚发布的
10
周年纪念版手机
iPhone X
,他表示,
iPhone X
的人脸识别功能的关键技术就是
3D
建模,而展讯与英特尔合作,在
iPhone X
发布之前就已经攻克这项技术,并调侃道已经剧透了
iPhone 11
的关键功能和技术。
据悉,采用
14nm
工艺的
SC9861G-IA
和
SC9853I
会在今年年底推出。
英特尔的封装测试技术一瞥
下面简单浏览一下英特尔的封装测试技术吧。
嵌入式多芯片互连桥接(
EMIB
)技术,主要面向异构芯片集成解决方案:
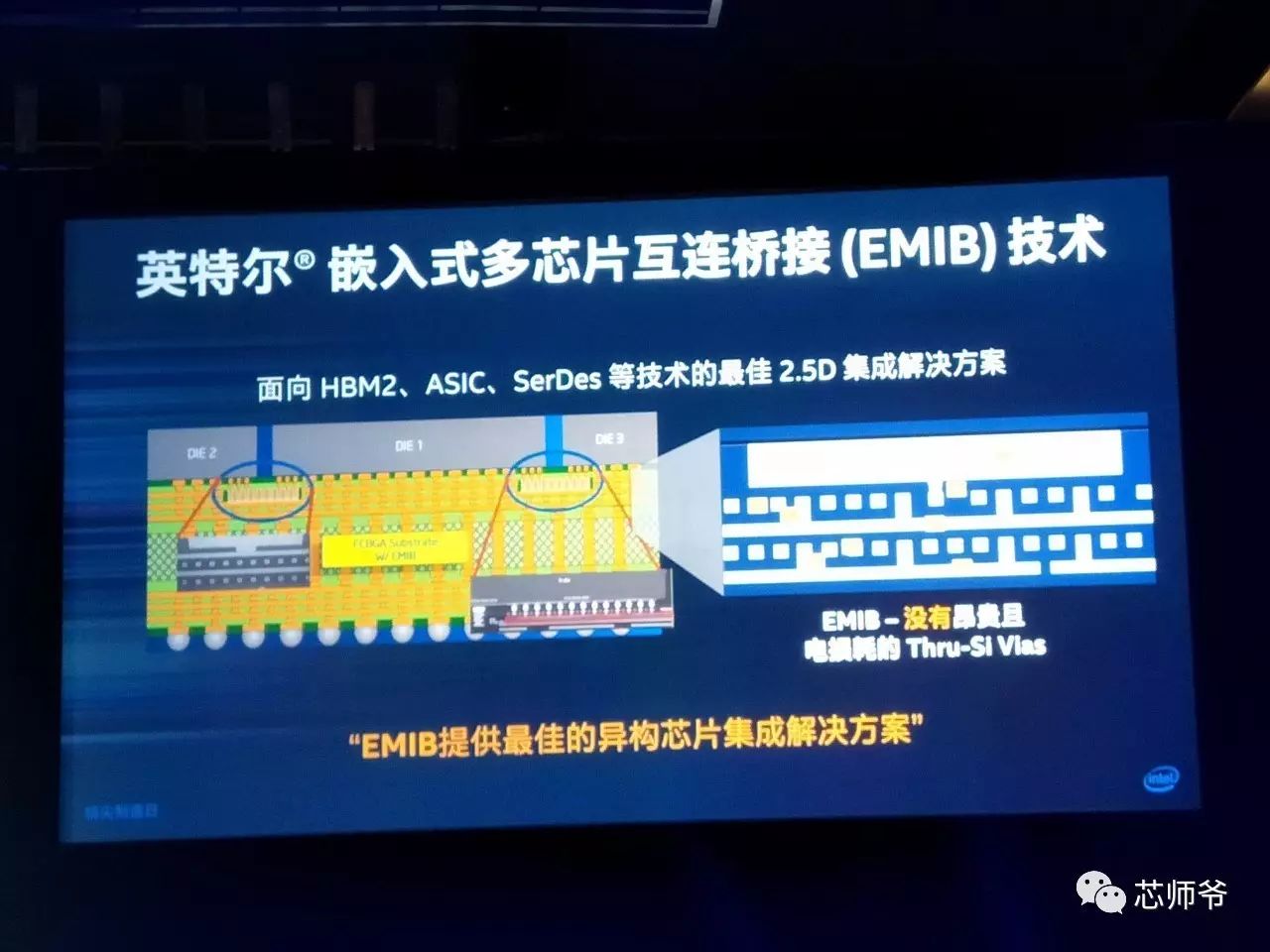

EMIB
的优势:
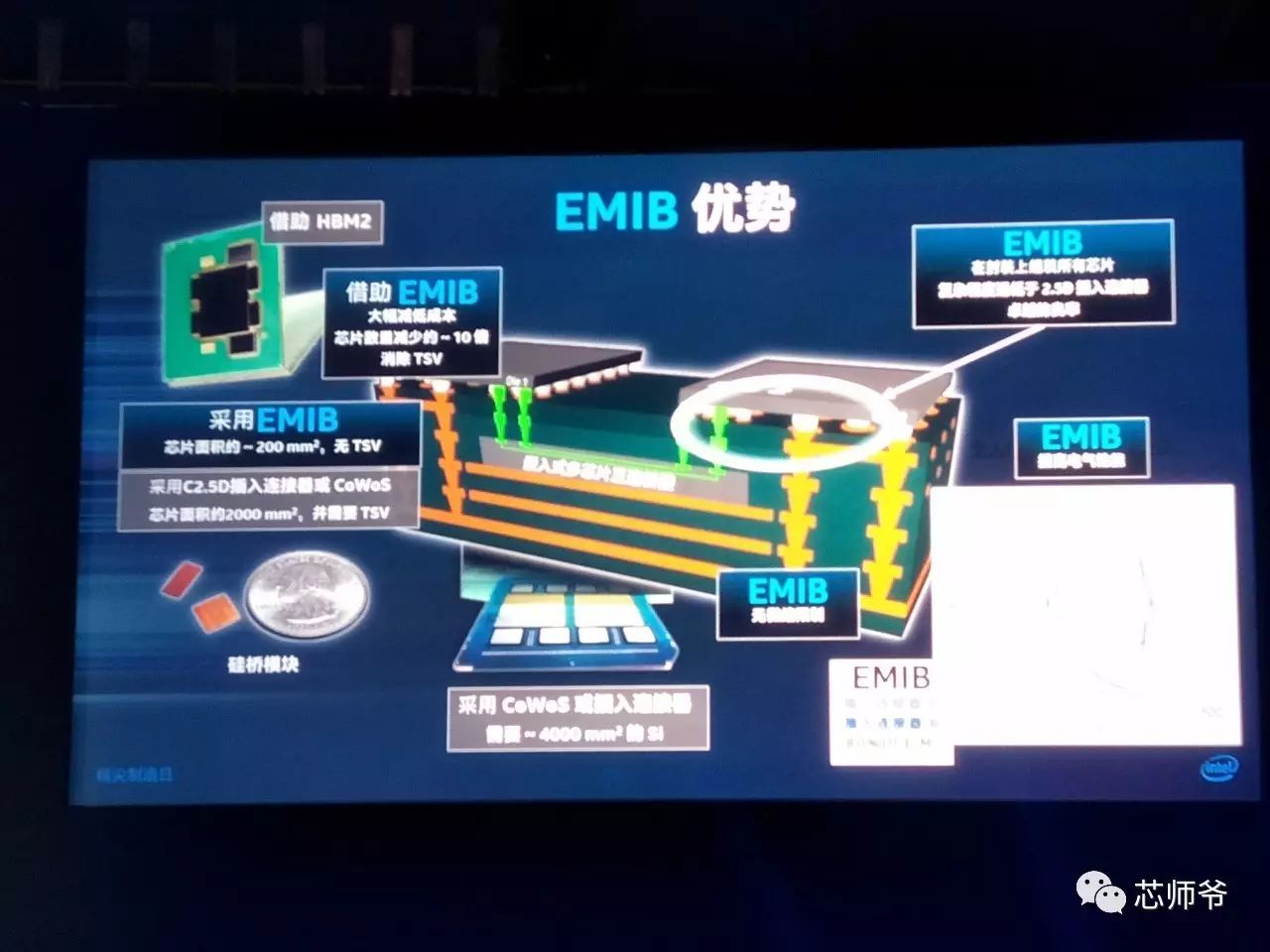
超小连接
Soft-IP
:

面向移动设备的封装功能:
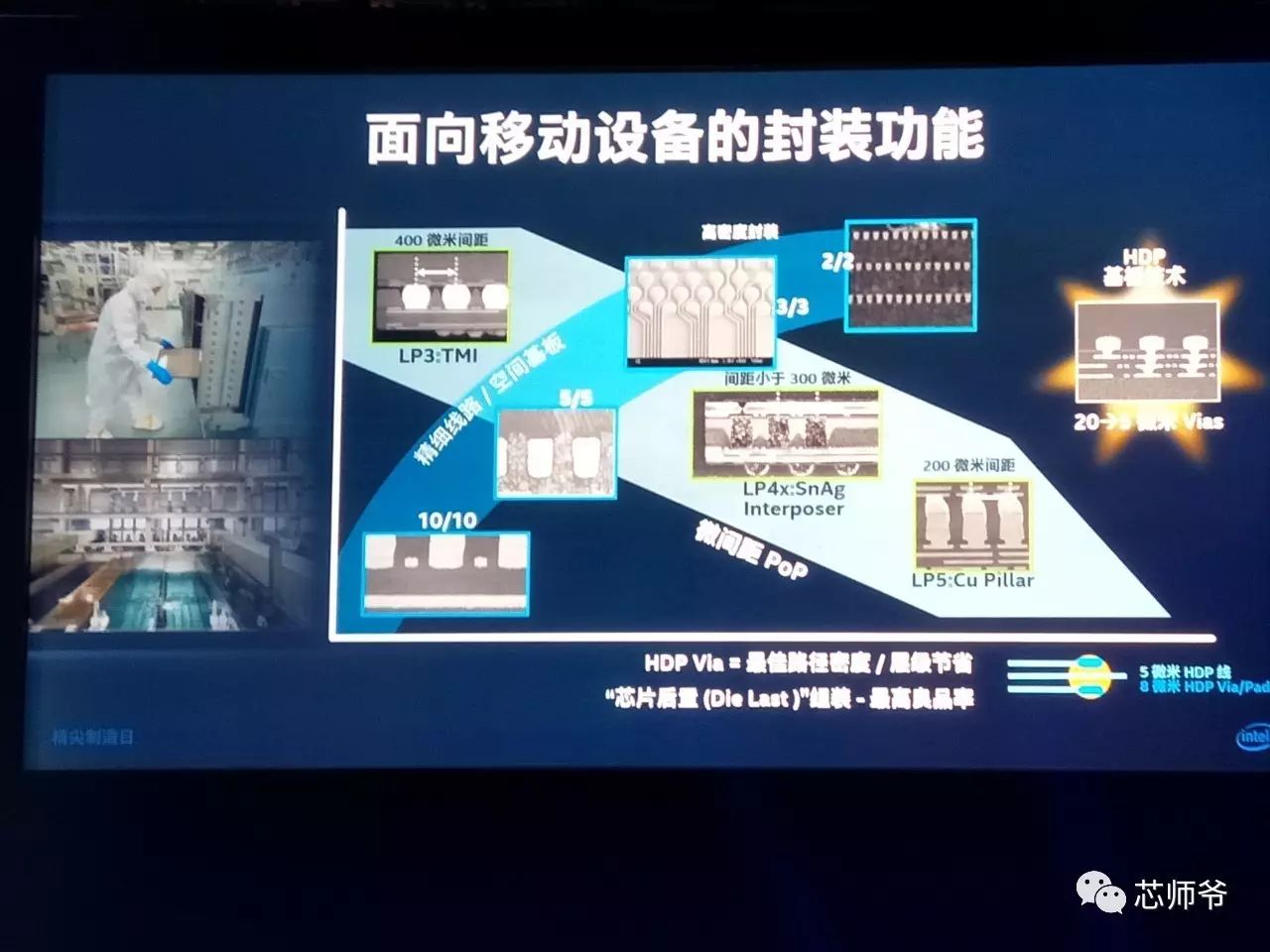
大型封装技术:

英特尔的独家测试平台:高密度模块测试(
HDMT
):
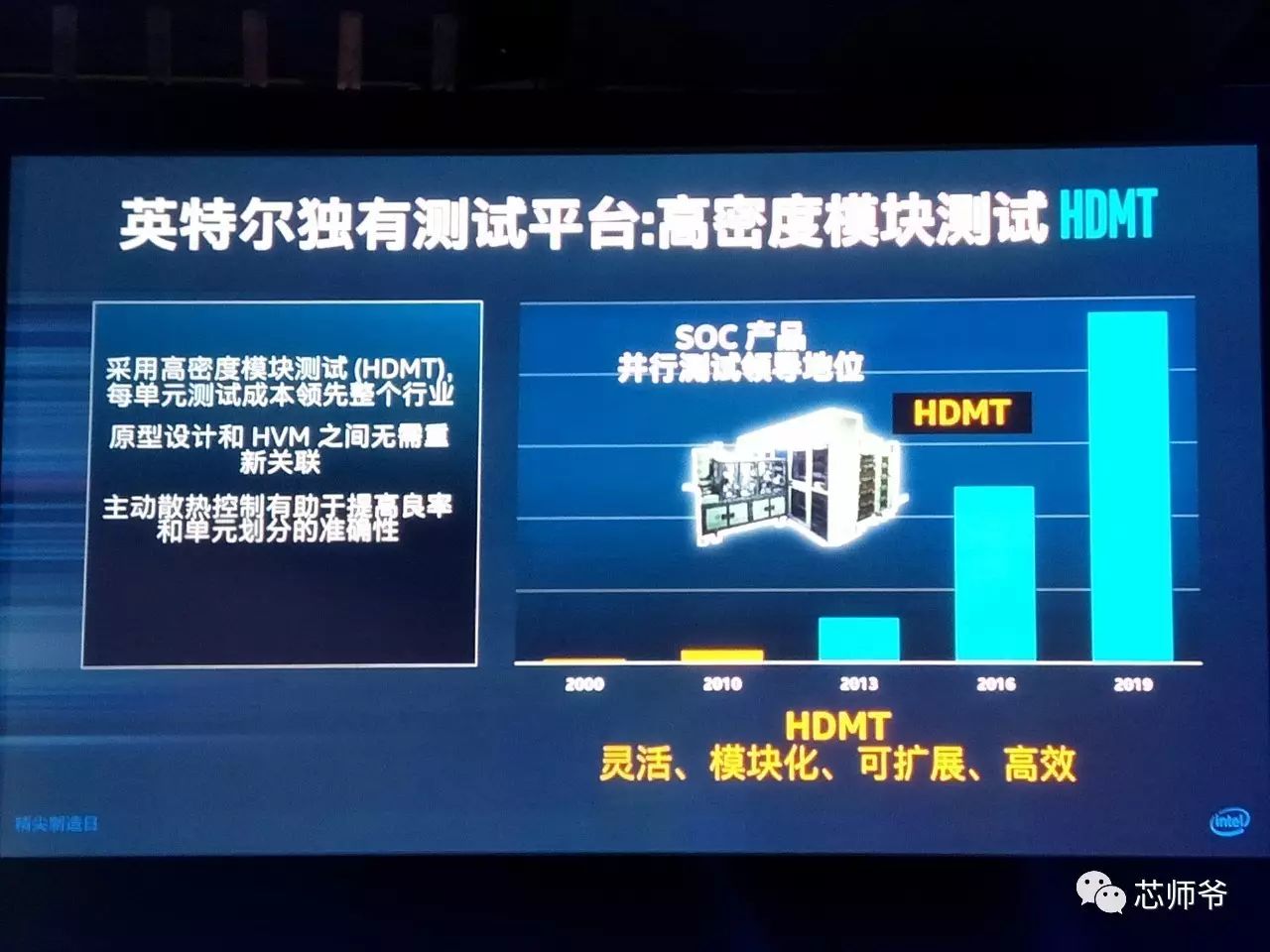
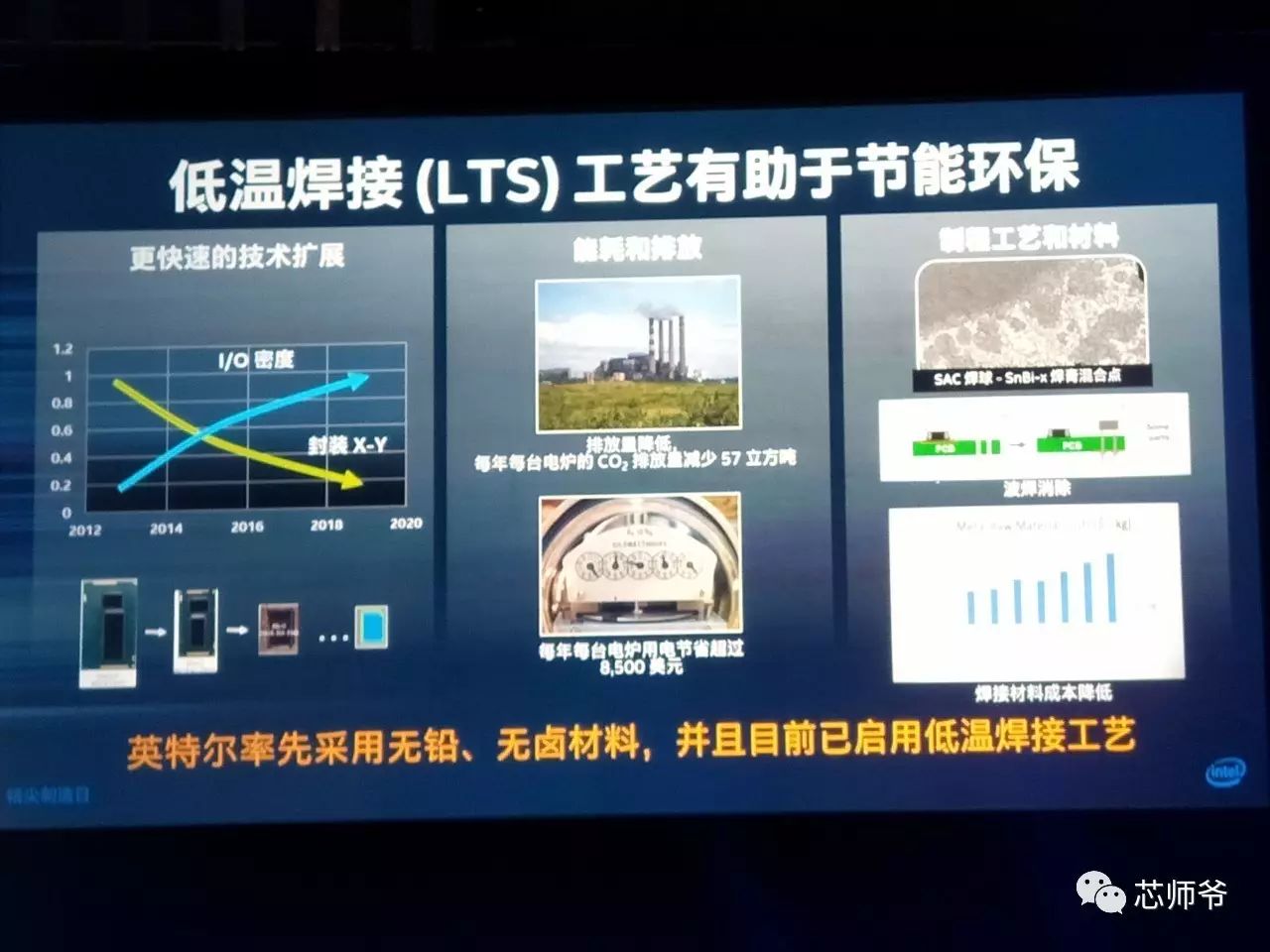
低温焊接(
LTS
)工艺有助于节能环保:
结语
可见,在市场和竞争的压力下,英特尔正从原来的以自我为中心,逐步转向以客户为中心的轨道上来。不过这也只是开个头儿而已,后续会怎样,拭目以待吧。






