
来源:机器之心 译
尽管识别检测等任务在实际中应用广泛,但
判别模型
真的搞不定未见过的数据。因此很多研究者认为
生成模型
对输入建立了完整的概率分布,说不定它就可以检测到不在分布内的「新奇」样本,例如在猫狗数据集上训练的
生成模型
能知道手写数字与训练集不太一样。但近日 DeepMind 发表论文否定了这一观点,他们表示深度
生成模型
真的不知道它们到底不知道什么。
深度学习
在应用层面获得了巨大成功,这些实际应用一般都希望利用
判别模型
构建条件分布 p(y|x),其中 y 是标签、x 是特征。但这些
判别模型
无法处理从其他分布中提取的 x,也就是说模型在没见过的数据上表现很差。例如,Louizos 等人表示仅仅旋转 MNIST 数字,模型就会预测错误。
表面上看,避免此类错误预测的方法是训练概率密度模型 p(x; θ)(θ 指
参数
)来逼近输入的真实分布 p ∗ (x),并拒绝为任何概率密度显著低于 p(x; θ) 的 x 进行预测。但是从直观上来说,
判别模型
并没有观察到足够的样本以作出可靠的决策,因此它们对异常样本的判断通常都是不准确的。
异常检测
是另外一个刺激我们寻求精准概率密度的契机,这一应用导致研究者对深度
生成模型
的广泛兴趣。深度
生成模型
有很多种形式,比如
变分自编码器
、
生成对抗网络
、自回归模型(PixelCNN)和可逆隐变量模型(Glow)。后两类模型尤其吸引研究者的注意力,因为它们提供了对边际似然度(marginal likelihood)的精确计算,且无需近似推断技术。
这篇论文调查了现代深度
生成模型
是否能够用于
异常检测
,并期望经过良好训练的模型对训练数据分配的概率密度高于其他数据集。但是,结果并非如此:在 CIFAR-10 数据集上训练模型时,VAE、自回归模型和基于流的
生成模型
在 SVHN 数据集上分配的概率密度高于训练数据。研究者发现这一观察结果非常令人困惑且并不直观,因为 SVHN 数据集中的数字图像与 CIFAR-10 数据集中的狗、马、卡车等图像视觉差异太大。
研究者继续在基于流的模型上研究这一现象,因为基于流的模型允许计算精确的边际似然度。初始实验表明雅可比行列式的对数项可能是导致 SVHN 高密度的原因,但是研究者发现该现象也适用于常量体积(constant-volume)流的情况。之后研究者介绍了一系列分析,展示了该现象可以从输入分布的方差和模型曲率的角度来解释。此外在实验中,基于流的模型剔除了一些关键实验变量,如常量体积 vs 非常量体积的变换效果。最后,分析结果提供了一些简单却通用的公式,用于量化两个数据集之间的模型概率密度之间的差异。研究者期望能有更多的工作研究深度
生成模型
在训练分布之外的属性,因为理解模型行为对它们在现实世界中的应用很关键。
论文:DO DEEP GENERATIVE MODELS KNOW WHAT THEY DON'T KNOW?

论文地址:
https://arxiv.org/pdf/1810.09136.pdf
摘要:现实世界中部署的
神经网络
可能需要根据来自不同分布(而不是训练数据)的输入进行预测。许多研究表明,找到或合成
神经网络
非常自信但错误的输入非常容易。人们普遍认为,
生成模型
对于这种错误的置信度是鲁棒的,因为建模输入特征的密度可以用来检测新的、不符合分布的输入。在本文中,我们向这一假设发起了挑战。我们发现,来自基于流的模型、VAE 和 PixelCNN 的模型密度无法将普通物体(如狗、卡车和马)的图像(即 CIFAR-10)与门牌号码的图像(即 SVHN)区分开来,当模型在前者上进行训练时,后者的似然度更高。
我们的分析主要集中在基于流的
生成模型
上,因为它们是通过精确的边际似然性来训练和评估的。我们发现,即使我们将流模型限制为恒定体积转换,这种行为仍然存在。可以对这些转换进行一些理论分析,而且我们表明,这些似然度的差异可以通过数据的位置和差异以及模型曲率来解释,这表明这种行为非常普遍,而不仅仅局限于我们实验中使用的数据集对。我们的结果表明,在足够了解深度
生成模型
在分布外输入上的行为之前,尽量不要使用模型中的密度估计来识别类似于训练分布的输入。
3 启发性的观察结果
鉴于深度
生成模型
取得了令人印象深刻的进步,我们尝试测试他们的量化能力,即当输入来自不同的分布而不只是训练集时的分辨能力。这种对分布外数据的校准在安全领域等应用上非常重要,例如我们可以将
生成模型
当做
判别模型
来过滤输入。
对于本论文的实验,我们训练了与 Kingma & Dhariwal (2018) 的描述相同的 Glow 架构,只不过模型要小很多,因此我们能使用 1 块 GPU 在 NotMNIST 和 CIFAR-10 上训练模型。我们随后会计算对数
似然函数
(越高越好)和 BPD(bits-per-dimension,越低越好),这两个度量标准分别在相同维度的不同数据集 MNIST (28 × 28) 和 SVHN (32 × 32 × 3) 上计算得出(测试集)。我们期望模型能给出较低的概率,因为它不是在这两个数据集上训练的。
从 NotMNIST 和 MNIST 数据集开始,下图 1 的左表展示了每一个测试分割的平均 BPD,而模型只在 NotMNIST-Train 上进行训练。而对于 CIFAR-10 和 SVHN,下图 1 的右表展示了在训练数据集上的 BPD(CIFAR10-Train)、分布内的测试数据(CIFAR10-Test)和分布外的测试数据(SVHN-Test)。
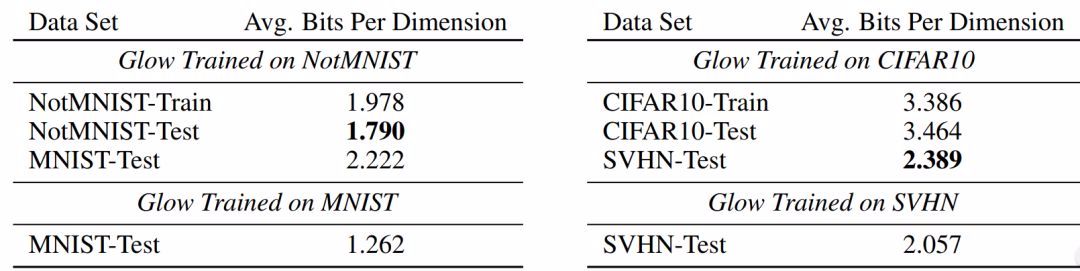
图 1:测试分布外属性。对数似然(单位:bits per dimension)是 Glow (Kingma & Dhariwal, 2018) 在 MNIST、NotMNIST、SVHN 和 CIFAR-10 上的结果。
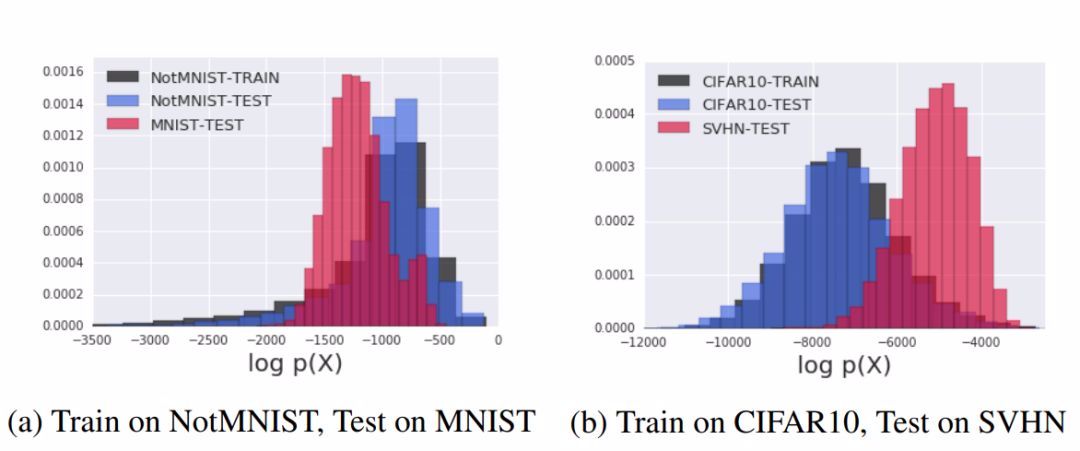
图 2:NotMNIST vs MNIST 和 CIFAR10 vs SVHN 的 Glow 对数似然图示。
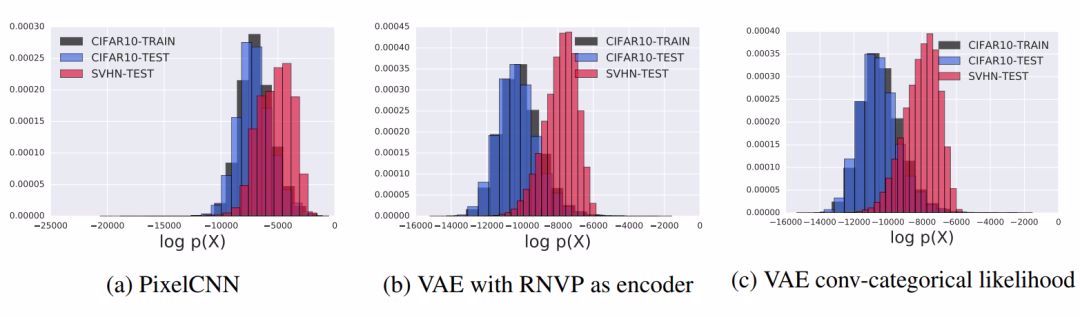
图 3:在 CIFAR-10 上训练模型,在 SVHN 上测试模型:PixelCNN 和 VAE 的对数似然结果。所用 VAE 模型见 Rosca et al. (2018)。
4 深入理解基于流的模型
以上我们观察到了 PixelCNN、VAE 和 Glow 在 CIFAR-10 vs SVHN 数据集上的现象,我们现在缩小探索范围,聚焦于可逆
生成模型
。
1.分解变量代换目标
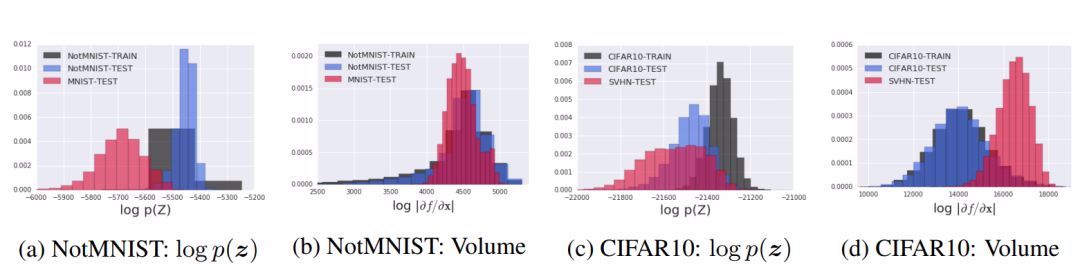
图 4:分解 NVP-Glow 的似然度。该直方图展示了将 Glow 的对数似然分解为 z-分布和体积元的贡献。(a)和(b)展示了 NotMNIST-MNIST 的结果;(c)和(d)展示了 CIFAR-10-SVHN 的结果。
2.体积是罪魁祸首吗?
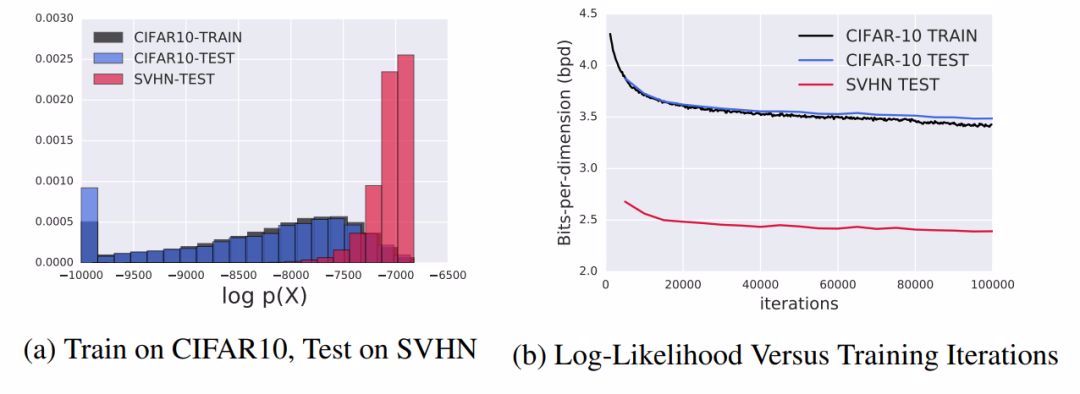
图 5:CV-Glow 的似然度。我们在 Glow 的常数体积变体上重复了 CIFAR-10 vs SVHN 的实验(仅使用了平移操作)。子图(a)展示了 CIFAR10-训练(黑色)、CIFAR10-测试(蓝色)和 SVHN(红色)的对数似然估计。我们观察到 SVHN 仍然能达到更高的似然度/更低的 BPD。子图(b)报告了训练过程中的 BPD 变化,表明该现象遍及整个训练过程,并且不能通过早停方法消除。
1.限时下载 | 800G人工智能全套学习资料,超级干货!
Hot~
2.限时下载 | Python+Matlab+机器学习+深度神经网络,仅限500人!
Hot~
3.限时下载 | 100G Python从入门到精通全套资料!(全网最全)










