1. 非常荣幸受邀在北京当代经济学基金会(NEF)所举办的“第二届思想中国论坛”上发表演讲。首先,我要感谢NEF主席夏斌教授及主办方举办了此次引人关注、意义重大的活动,感谢邀请我加入“中国经济学奖”提名委员会,同时很荣幸受邀以计量经济学研究的新领域为主题发表演讲。我还要向“中国经济学奖”获奖者钱颖一教授和许成钢教授表示祝贺。
2.在谈到我所认知的计量经济学新领域之前,大家可以先回想一下世界计量经济学会创建之初及其使命。1933年,拉格纳•弗里希(Ragnar Frisch)教授在刚创办的学会官方刊物《计量经济学》第一期中写道:
“计量经济学会是为推进经济学理论在与统计学和数学的关联中发展而创建的国际性学会。 ( ... ) 其主要宗旨是促进以结合理论定量和实证定量方法为目的的研究来解决经济学问题( ... )任何承诺最终会完善这种结合的研究活动 ( ... )均应纳入与学会相关的范畴。”
以及,
“ [一般经济学理论、经济统计学、数理经济学]三者的结合影响显著。也正是以上三者的结合构成了计量经济学。”
21世纪的计量经济学家们仍将以上一般性原则作为指导准则。计量经济学的宗旨仍是为以下目的提供方案:(1)评估评价经济学理论、 (2)验证各竞争模型、 (3)政策评估以及(4)预测经济政策影响。
在近90年的研究之后,该领域研究取得重大进展。经济学家现在掌握了有力方法,可以从实证和理论的角度对经济进行深入分析。然而,在我看来,目前计量经济学研究仍面临三大挑战。除过去已知的问题,还出现了全新的挑战。
3. 第一大挑战,如何面对海量统计信息的可用性(即所谓的“大数据”)。
吴(Ng) (2016)1 就在计量经济学中使用大数据提出了一些重要见解。目前全球存储的数据量之大令人瞩目。例如,根据吴(2016)的报告,仅脸书(Facebook)存储和处理的用户生成数据就超过了30x220 GB。顶尖的网上商店如沃尔玛(Walmart),每小时要处理上百万份消费者订单。2008年,谷歌(Google)的日均数据处理量达到20x220 GB。这些数据中部分是(通过谷歌搜索或谷歌趋势服务)面向公众的,且如今经济学家已公认,搜索引擎可提供官方统计的补充数据。金融市场上有关单一股票或交易资产的交易数据也以超高的频率可供获取。
显然,“大数据”对计量经济学家们提出了新的问题和挑战。首先,当数据集维度超大时,即使是较为简单的计量经济学技术也需要采取特殊方法才能应用。需要在计算方面更高效的创新计量经济学方法。大数据计算方法的发展不是仅靠计算机科学家就能处理的,考虑到计量经济学模型和方法的特异性,计量经济学家在该领域演变过程中必须占有一席之地。其次,身处大数据时代,即便是标准方法也需再三斟酌。比如,信号提取(如长跑-趋势-成分,循环,季节规律)的新方法必须要有。普通数据集信号提取可以根据一系列成熟方法来进行,而较大数据集则需要新方法。这里简单提及第三领域,经济数据的实时监测也是需要开发新方法的。
计量经济学家(以及统计学家)已经开始探究可处理大型跨行业维度和时间序列维度的模型。例如下列因子模型
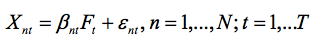
已经在时间序列维度T 较大(形式上T → ∞)、跨行业维度 N 较大(形式上 N → ∞)或 T 和 N 都较大的情况下深入分析过了。但该领域仍需要更新的研究。
第二大挑战是要面对在动荡环境中模拟并预测经济形势的失败尝试和无所作为。
众所周知,无法预料的震荡会给经济带来冲击。普遍认为,这样的震荡一般是无法预测的,其结果也是无法预知的,因而又增添了额外的不确定性。最近一次的全球金融危机(GFC)就是很好的例子:尽管已经明确了触发危机的是房价泡沫(其中,罗伯特•希勒教授(Robert Shiller)提出了大规模失衡发生的事前证据,也就是美国房地产市场的价格泡沫),而绝大多数经济学家并没能预见泡沫破灭造成的结果。除此之外,后危机时代的新经济体制拥有很多新特点,比如利率逼近甚至低于零位。此类特征迫使新的计量经济学方法出现。尤其是对不稳定泡沫环境下的经济进行建模及预测,更需要采用新方法(最近,M. Watson和J. Stock、B. Rossi和R. Giacomini以及A. Timmermann在该方面做出新贡献)。同样,这里也需要以日期记录的实时监测方法(P.C.B. Phillips最近提出可以对经典的时间序列方法进行修改后用来检测金融及商品市场的健康发展或有无泡沫出现)。此外,仅靠纯统计预测方法和经济模型还不够有效,无法就相关问题做出令人满意的预测。因此,有必要找到将经济理论融合进预测过程的新方法(R. Giacomini与A. Carriero最近就这一方法做出过探讨)。
第三大挑战是要提出严谨的计量经济学理论以应对经济模型不断加深的复杂性。
40年来,计量经济学理论呈爆炸式增长。非静态的时间序列分析与协整(由R. Engle、C. Granger以及S. Johansen率先提出)对时间序列数据的计量经济学分析产生很大影响,尤其是在宏观层面。此外,全新领域如金融计量经济学(自回归条件异方差(ARCH)模型和随机波动模型)也已出现。
随着模型越来越复杂,为更合理配比数据,也更需要发展新的计量经济学理论。如此前提到,需要用计量经济学方法来创建大维度模型(如监测通胀情况);需要用计量经济学来处理极端事件相关数据(如金融市场风险评估);需要新的计量经济学方法来处理高频和超高频数据(如理解价格发现背后机制,或在高频阶段发现最优对冲策略)。需要开展所谓预测性回归计量经济学新研究,结合低频变异性和高频变异性来预测财政回报。由于计量经济学模型越来越复杂,我们还需要改善有限样本推理方法——尤其是bootstrap方法。
本讲座接下来的一部分,我会重点就最后一个问题进行解释,尤其是bootstrap方法可为计量经济学家所利用的最新进展。理解该部分需要一些基础的计量经济学知识。
4. 假设有一根据向量参数所建的计量经济学模型,以及一位计量经济学家打算用Tn :=T(X1,...,Xn)推断出θ。假设根据渐近论,Tn →T∞ 在分布(通常为高斯分布或 χ2)中为n → ∞。经济学家或计量经济学家不采用渐近论进行推断,而是选择bootstrap方法。
为什么要用bootstrap进行计量经济学建模呢?有以下几项原因。第一,根据渐近临界值进行的检验并非总在可接受范围内;因此经济学家也许会常常推翻这种利息假说。第二,bootstrap方法可在一阶渐近的基础上获得更精确的渐近数值。也就是说,在样本较小或适度时进行的推论会更加精确。第三,bootstrap方法可在非标准或未知统计量的渐近分布相关问题中检索出渐近正确的临界值。
但究竟什么是bootstrap呢?根据霍洛维茨(Horowitz) (2001)2的说法,bootstrap是通过数据重新采样来预测一项估计量或检验统计量的分布。该方法相当于将数据看作是为评估利息分布的数据总体。此外,在弱正则条件下,bootstrap方法可得到估计量或检验统计量分布的近似值,该近似值精确度至少与用渐进论得出的近似值精确度相当。
假设统计量 Tn :=T(X1,X2,...,Xn) 的分布取决于数据的分布;同时假设该分布是未知的。Bootstrap推断是基于新的“bootstrap”式的统计量,比如T n * := T (X1 *, X2 *,...X n *),这里的{ X1 *, X2 *,...X n *}是从原始样本中抽取的一个样本(即“重新采样”)。
有以下几种重新采样的方式:
o 选项一:通过置换原始数据(i.i.d. 独立同分布bootstrap)重新采样;
o 选项二:冲击原始数据(wild bootstrap方差比检验法);这种bootstrap方法保留了异方差性(也就是改变了原始经济数据的可变异性);
o 选项三:对数据块进行重新采样(数据块bootstrap方法,静态bootstrap方法)而非仅进行单次数据观测;这种bootstrap方法保留了自相关性(也就是原始经济数据的时间序列独立性);
对于一般的计量经济学模型,bootstrap通常应用于所谓残差量(残差bootstrap方法)。此外, 外生变量也可进行重新采样(比如,递归设计bootstrap方法)或保持固定(固定设计bootstrap方法)。
为了介绍bootstrap方法的用处,下面我将探讨该方法在计量经济学领域的三种应用情况:
1) 波动性与不稳定因素下的期限结构建模;
2) 合理预期模型(动态随机一般均衡模型DSGE);
3) 边界检验参数。
5. 让我们先来看一下期限结构模型,假设一组利率p,到期时间不同,记录时间为 t:
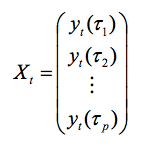
利率举例见图1,p = 5,到期时间为1、3、12、60 以及120个月。
经济学家及计量经济学家有意去理解利率走向的时间序列动态(出于预测目的,政策分析等)。 有关利率的著名模型之一就是零息债券收益的动态尼尔森-辛格尔(Nelson-Siegel)模型,模型如下:
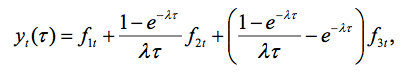
其中 τ表示到期日,fit (I =1,2,3) 为未观察到系数(水平、斜率及曲率),l 代表形状参数。时间序列特征Xt = ( yt (τ1),..., yt (τp ))’ 取决于fit,会出现以下几种不同情况。
首先,如果所有系数为静态(静态变量表示为 I(0)),则其为 Xt 。
其次,如果水平系数f1t 为非静态 (I(1)),但f2t 及f3t 为I(0),则Xt为I(1),且
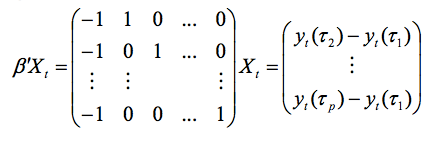
为静态。这就是所谓的“协整”特征:非静态时间序列可以通过线性组合成为静态。独立线性组合个数为“协整秩”,在该情况下相当于r = p-1。该情况对应弱式预期假说。
第三,若水平和斜率为I(1),但曲率为 I(0),则β’Xt 包括r = p-2价差线性组合。理解协整关系的个数r 对于我们掌握利率动态来说至关重要。那究竟是如何操作的呢?
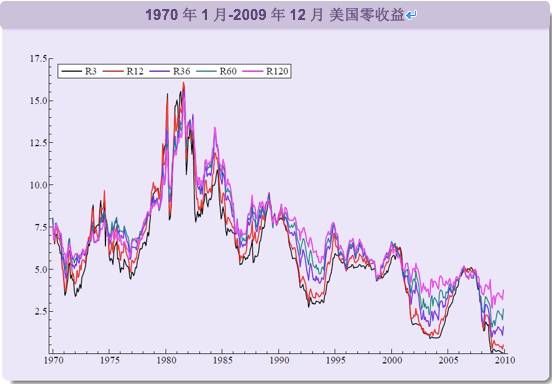
图1:1970-2010年美国利率。
此处,Xt = ( yt (τ1),..., yt (τp ))’,利率的动态特征可在协整VAR模型
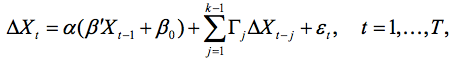
中进行探究,根据假设εt ~ i.i.d. N (0, ∑),利用约翰森(Johansen)的似然率检验。
下一幅图表明VAR(2)模型中的数据与残差符合该数据,且展示出方差总体轮廓(Boswijk3 等人,2016)。以45°线为基准的方差总体轮廓偏差说明波动性有变化,也就是i.i.d.假说的偏差。显然,有证据表明波动性存在持久变化,所以这里使用标准推断流程是无效的。
自二十世纪70年代早期以来,利率波动很大程度上都是随时间波动的,因此i.i.d.假说被错误地套用在该模型上。很遗憾,在波动性存在持久变化时,约翰森的检验和对协整秩的判断均是完全不可信的:
o 协整关系预期数量严重向上偏误;
o 总体趋势预期数量( p - r ) 向下偏误;
o 对 b(协整空间)的检验也出现偏误。
除此之外,波动性动态要想在不同水平层面上联合建模未免过于复杂。
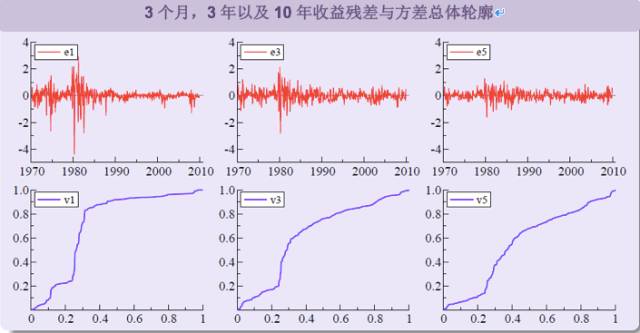
图2:VAR(2)残差及方差总体轮廓
幸运的是,只要简单应用递归设计wild bootstrap方差比检验法,根据
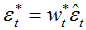 ,其中
,其中 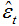 为模型残差,
为模型残差,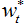 为
为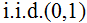 就能完全解决问题。特别的是,它还能就r和b 的形式进行有效推断(在卡瓦列雷、拉贝克和泰勒的若干著作中有所记录),可以完全解决与持久波动性变化有关的推断问题(Boswijk等人,2016)。
就能完全解决问题。特别的是,它还能就r和b 的形式进行有效推断(在卡瓦列雷、拉贝克和泰勒的若干著作中有所记录),可以完全解决与持久波动性变化有关的推断问题(Boswijk等人,2016)。
当图1中的数据运用了bootstrap方法,可得到下列结果:
o 一个拥有残差自相关的VAR(2)模型,采用LM检验结合wild bootstrap方差比检验p值;
o LR 检验结合wild bootstrap方差比检验法得出 r = 2,(而标准LR检验为r = 3),这说明三系数模型中,水平、斜率和曲率这三项系数并非静态;
o 动态尼尔森-辛格尔模型此处不适用;
o 数据并未反驳另一线性斜坡模型。
因此,无需费力,bootstrap方法便可纠正因利率随时间强烈波动变化而可能引起的偏误。
6. 我的第二个有关经济学bootstrap推断方法的探讨是用该方法得出合理预期模型。此类模型通常建立在如下的结构形态基础之上(对数线性化之后),
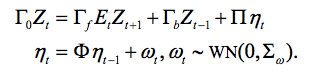
其中 Zt 向量为状态变量,ωt为结构性冲击向量,
为系数矩阵,取决于结构性参数向量θ。通常还需要一些其它技术假设(因而模型不会是待定状态)。最典型的例子就是An和Schorfheide的DSGE货币模型,该模型是通过下列方程组所定义:
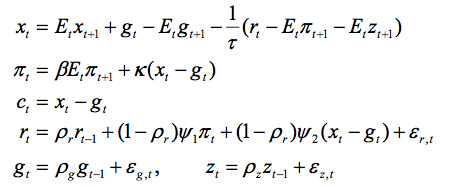
其中假设 
第一个方程式为前瞻预期的产出缺口方程式, Xt 代表产出缺口;第二个方程式为纯前瞻预期的新凯恩斯菲利普斯曲线(NKPC),斜率为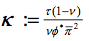 ,且πt 代表通货膨胀率;第三个方程式为消费方程,代表消费;第四个方程式为货币政策规定,代表政策利率;最后的两个方程式保证了总供应量 (gt)和需求 (zt) 冲击,为自回归过程。结构性参数向量由
,且πt 代表通货膨胀率;第三个方程式为消费方程,代表消费;第四个方程式为货币政策规定,代表政策利率;最后的两个方程式保证了总供应量 (gt)和需求 (zt) 冲击,为自回归过程。结构性参数向量由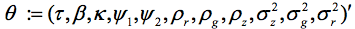 给出。Komunjer和吴(2011)曾就此模型进行过探讨。
给出。Komunjer和吴(2011)曾就此模型进行过探讨。
此类模型的的缺点之一就是无法轻易地用经典的最大似然率方法来进行预测。特别是所谓的似然函数通常如图3所示,该函数在某些方向上是平的,意味着找到最大值会比较困难,且参数估计会非常不准确。这种情况被称作“弱识别”。
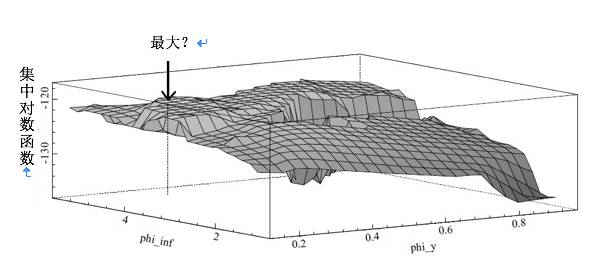
图 3:DSGE模型的似然函数
作为结果,关于θ 的推断——尤其是检验模型带来的交叉方程限制,我们以下称作H0 ——还是很有难度的。尤其是H0的似然率 (LR)检验会非常不可信(因样本过大),证据可能会出现严重偏误,导致推翻H0 并推翻CER。
贝叶斯推断(Bayesian)提供了一种可能的解决方法。但该推断要求操作者对参数强加先验信息。此类先验信息通常为临时设定,无法进行实证检验。另一种解决方案(我在最近与安杰利尼(Angelini)和法内利(Fanelli)5合作的著作中也提出过)就是用bootstrap的方法进行H0的LR检验,即,我们可以利用bootstrap方法粗略算出CER之 LR检验统计量的有限样本分布。
为用bootstrap方法进行DSGE模型的推断,建议注意该模型可能被嵌套在所谓最小识别的ABCD形态中,即
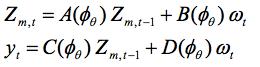
其中,φθ=g(θ) 在 CER之下。这是典型的状态空间模型 ,CER对其参数强加(可检验的)的限制。要构建bootstrap样本,可以参考创新形式表现,即:
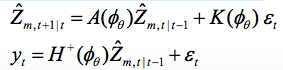
然后得到bootstrap样本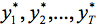 ,递归为
,递归为
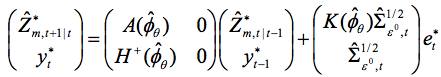
其中et∗ 为预期创新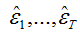 中的i.i.d。最后,LR统计量的分布(根据原始样本计算)近似于LR∗统计量分布(根据bootstrap样本计算)。
中的i.i.d。最后,LR统计量的分布(根据原始样本计算)近似于LR∗统计量分布(根据bootstrap样本计算)。
该情况中bootstrap方法的理论有效性由安吉内利等人(2016)提出,还提出了下列结果。第一,基于渐近论的方法(即基于渐近论的LR检验)常常与DSGE模型(CER)相矛盾。第二,一阶渐近论对于CER有限样本检验推出的近似值很不精确。第三,bootstrap方法降低了渐近LR检验造成的过度排斥。第四,bootstrap在准确识别的DSGE模型中是有效的。这一结果延伸到了更通用的一类状态空间模型。第五,蒙特卡洛(Monte Carlo)和实证结果表明,即使是在非标准环境中,比如此前提到的“弱识别”情况,bootstrap也提供了更好的有限样本推断方法。
再次重申,bootstrap方法对想要精确评估经济模型有效性的实操者来说是非常重要的工具。
7. Bootstrap方法的第三项应用是来解决计量经济学模型中统计推断的一个经典问题:“参数临近参数空间边界”的情况。很多计量经济学模型都暗示过参数空间中临界参数的情况。这是什么意思呢?举例说明,在简单模型
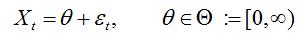
中,当θ = 0时,参数(θ)位于参数空间边界(参数空间为非负实数集)。当参数临界时,参数估计量和检验统计量的渐近分布均并非标准。
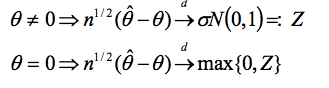
该问题在更高维度模型中会变得更加棘手,但bootstrap方法是消除这种困难的有力工具,为实操者提供了简单有效的推断方法。
详细来说,可以考虑一个著名的波动性模型,所谓的ARCH(2)模型(八十年代初期由R.Engle提出)。
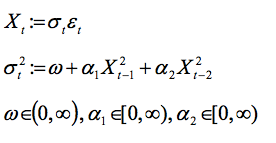
为严格确保方差的正性,α1 和 α2 都是非负的。计量经济学家对有关 α2 的推断感兴趣,例如检验α2 = 0 (该情况下该模型归纳为一个ARCH(1)模型)。
利用最大似然率推断,当α2 = 0时可能发生下列情况:
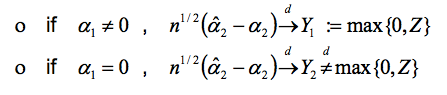
因此,无法在不知道α1的情况下轻易地判断α2 (反向同理)。
幸运的是,经过修改的受限bootstrap可以解决问题。首先假设一个标准的bootstrap生成过程并赋予空值:
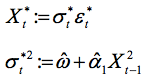
其中,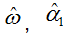 是根据原始数据赋予空值假设而进行预测。但不幸的是,这一bootstrap方法并不奏效(
是根据原始数据赋予空值假设而进行预测。但不幸的是,这一bootstrap方法并不奏效(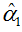 没能以足够快的速度处理真正的α1)。
没能以足够快的速度处理真正的α1)。
然而,卡瓦列雷、尼尔森和拉贝克6 设法构建了修改过的bootstrap方法,因而bootstrap统计量与原始统计量的分布相同,与α1 为零非零无关。
同样的原则也适用于更高维度的模型——这种特征使得bootstrap成为极佳的推断工具,即使在高度非标准的情况下也十分有效。
8. 接下来进入总结部分。大概17年前,诺贝尔奖得主詹姆斯·赫克曼(James Heckman) (2000)曾写道
“计量经济学理论和实证实践之间的差距[在过去20年间]不断增长(…)如果这个趋势继续下去,绝大多数计量经济学家会将理论计量经济学看作是本质上与实证研究毫无关联的学科”
不幸的是,在近二十年之后,我们可以确定地说情况已大不相同。顶尖经济学与金融期刊(越来越多地)要求更加严谨的计量经济学著作。计量经济学与数理统计学相重叠的部分仍占很大比重,但成功的计量经济学理论著作都是与经济学紧密相关的。因此,计量经济学与经济学之间的关联仍然十分强大,且计量经济学家已经准备就绪,应对全新挑战。
9. 在结束本次讲座之前,我想要再就“计量经济学地理”讲几句,也就是简单分析各国家和地区对最新计量经济学发展的贡献。表格1中是1990至1994年间顶尖计量经济学刊物的全球分布(《计量经济学》、《计量经济学杂志》(Journal of Econometrics)及《计量经济学理论》(Econometric Theory)中发表的文章)。2011至2015年间的数据见表格2。数据中的趋势很令人深思。1990至1994年,全球计量经济学出版物中北美占到71.7%,而2011至2015年间,该比例降至50.6%。欧洲比例从20.1%增长至30.6%,而亚洲更是令人瞩目地从4.6%增长至14%。2011年至2015年,中国计量经济学出版文献达120份,超过亚洲机构贡献总数的三分之一。
表格1:1990-1994年顶尖计量经济学出版物
| 出版物数量 | %
|
北美 | 736 | 71.7 |
欧洲 | 206 | 20.1 |
澳大利亚 | 33 | 3.2 |
拉丁美洲 | -- | -- |
非洲 | 4 | 0.4 |
亚洲 | 47 | 4.6 |
全球 | 989 | 100 |
来源:蒂尔堡大学全球经济学研究机构排名
表格2: 2011-2015年顶尖计量经济学出版物
| 出版物数量 | % |
北美 | 1249 | 50.6 |
欧洲 | 755 | 30.6 |
澳大利亚 | 97 | 3.9 |
拉丁美洲 | 22 | 0.9 |
非洲 | -- | -- |
亚洲 | 345 | 14.0 |
全球 | 2469 | 100 |
来源:蒂尔堡大学全球经济学研究机构排名
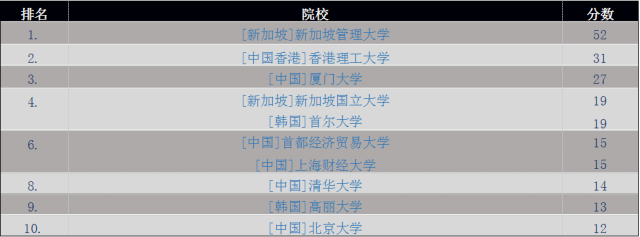
另外值得分析的一点就是亚洲机构近年来在计量经济学领域所获得的成功。表格3中是1990至1994年发表经济学文献排名前10位的大学。除新加坡国立大学外,其余全部为日本或以色列的院校。尤其是在该排名中绝对领先的日本。
表格3. 1990-1994年发表计量经济学文献最多的机构
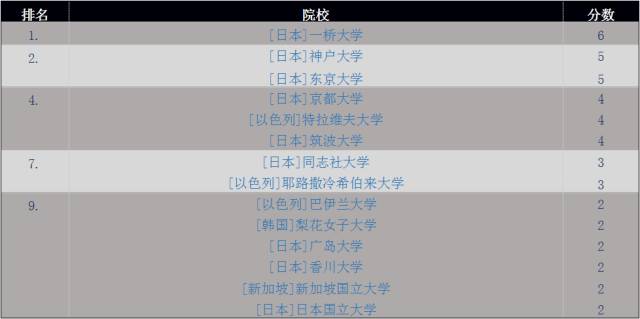
但最近(2011-2015)的情况就大为不同了,见表格4。
排名中日本院校消失了,取而代之的是中国院校(包括中国香港)数量最多。这项结果很了不起,有力说明中国大学为聘请顶尖教授和研究者所投入的努力和资金收到了很好的回报。如我所希望,若这种投入可以继续,很有可能中国的计量经济学研究会在全球范围内占据主导地位。
表格4. 2011-2015年发表计量经济学文献最多的亚洲机构