5 月 27-28 日,机器之心在北京顺利主办了第一届全球机器智能峰会(GMIS 2017),来自美国、加拿大、欧洲,香港及国内的众多顶级专家分享了精彩的主题演讲。在这篇文章中,机器之心整理了第四范式首席科学家、香港科大计算机科学与工程系主任杨强在大会第二天发表的主题为《迁移学习研究的最新进展》的演讲。

杨强,第四范式联合创始人、首席科学家。杨强教授在人工智能研究领域深耕三十年,是国际公认的人工智能全球顶级学者,ACM 杰出科学家,两届「KDD Cup」冠军。现任香港科技大学计算机与工程系主任,是首位美国人工智能协会(AAAI)华人院士,AAAI 执行委员会唯一的华人委员,国际顶级学术会议 KDD、IJCAI 等大会主席,IEEE 大数据期刊等国际顶级学术期刊主编。杨强教授在数据挖掘、人工智能、终身机器学习和智能规划等研究领域都有卓越的贡献,是迁移学习领域的奠基人和开拓者,他发表论文 400 余篇,论文被引用超过三万次。
以下是该演讲视频的主要内容:
大家好,我叫杨强,我今天想跟大家分享一下大家可能都关心的问题,机器学习、人工智能有哪些最新的进展。
我先从最近比较热的一个话题开始。我们知道本周人工智能界最热的一个话题是人机大战,在乌镇,AlphaGo 和柯洁进行了三场比赛。这个比赛看上去让人心潮澎湃,而我们在里面到底学到了什么东西呢?
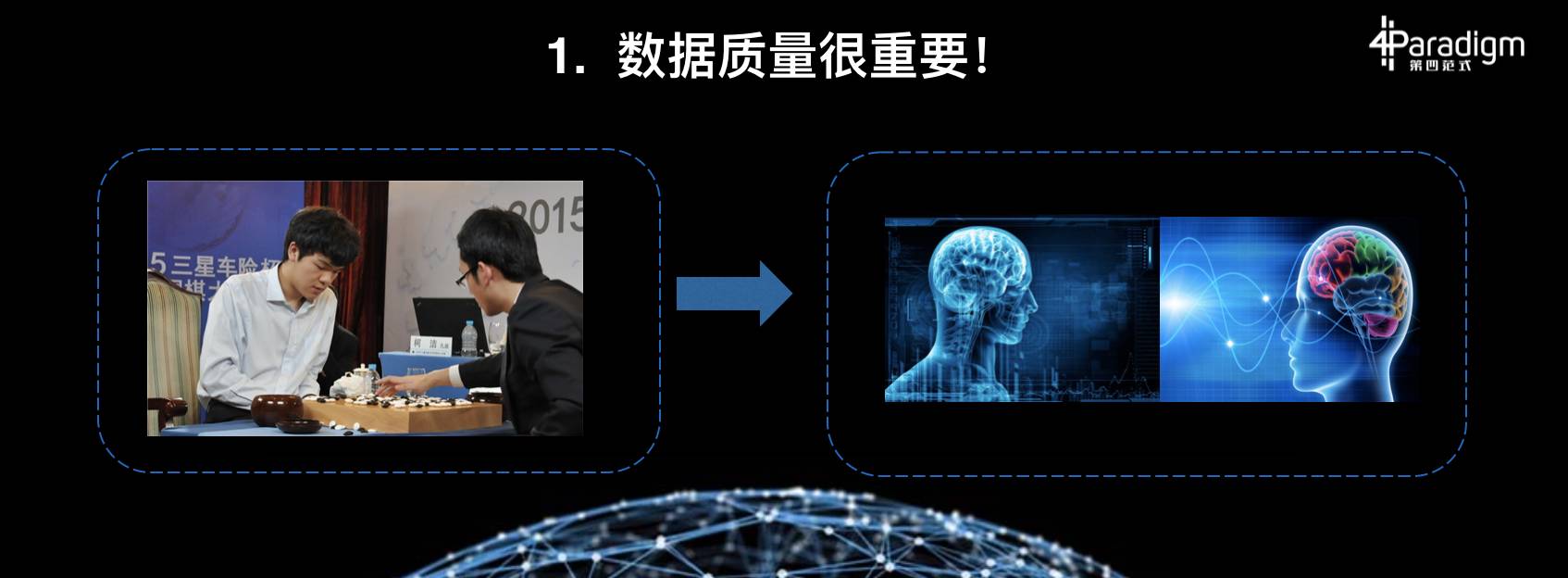
首先,今年的数据和去年与李世乭下棋时候的数据大有不同,去年还用了很多人类大师们下棋的数据,但是今年更多地用了 AlphaGo 自我对弈的数据,这使得数据的质量大幅提高、也就是让机器学习的效果大为提高。所以说,数据的质量是非常重要的。
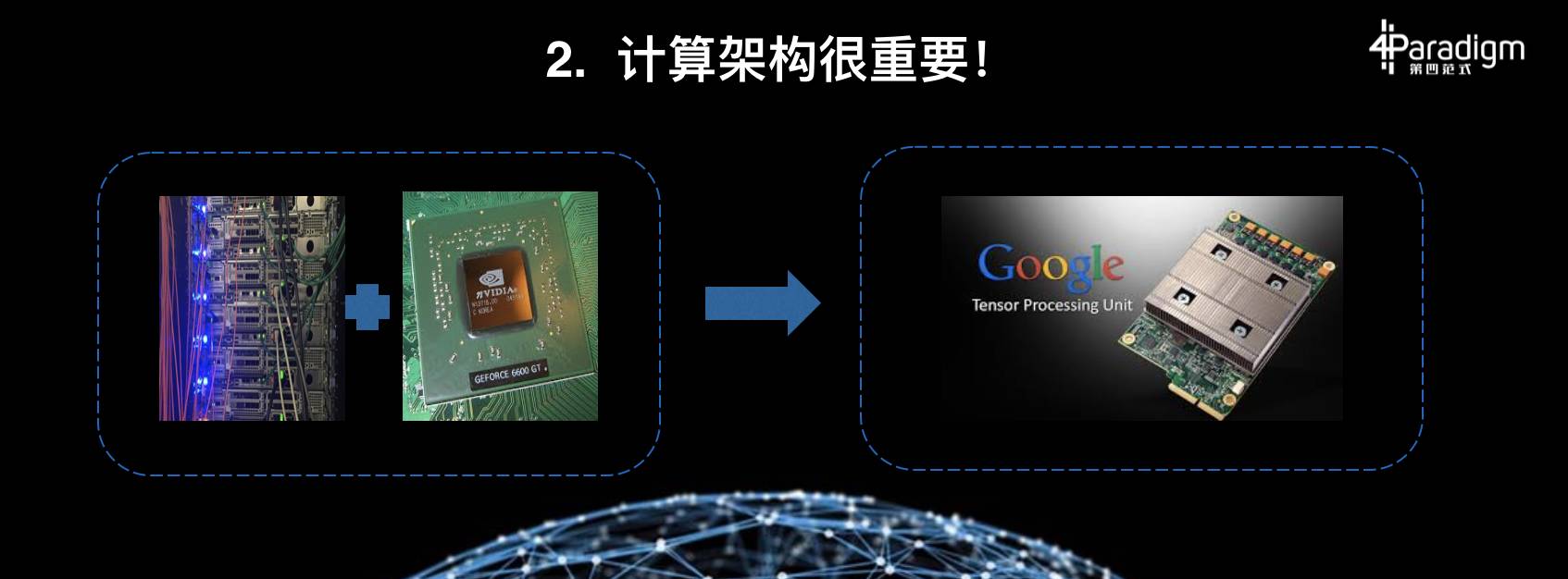
第二条,计算架构也很重要。我们知道去年用了上千的 CPU,用了成百的 GPU,但是今年只用了小小的 TPU。今年用的计算架构与去年的计算架构相比,有了一种飞跃性的变化。
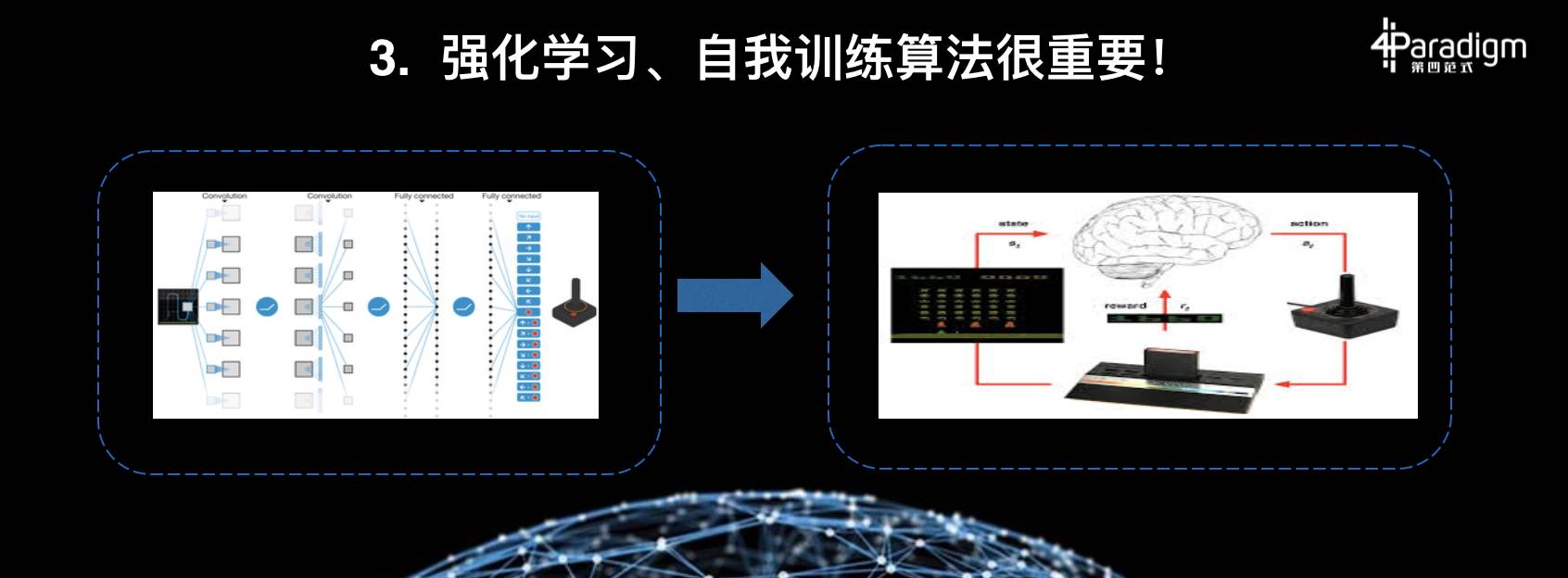
再则,智能算法也是非常重要的。AlphaGo 能够让计算机自我训练,自我学习,靠的是强化学习算法。有了这样的算法,虽然人是没有办法打败机器的,但是机器是可以打败机器。机器的特点是自动运算,如果我们赋予机器一种能力,让它能够自我学习,那么其某些方面能够超越人的能力。所以这种自我学习的算法极其重要。
以上这三点对于商业活动、对于我们把人工智能落地,其实是非常重要。我们想一想工作当中、生活当中遇见的人工智能应用:是不是都有高质量的数据、很好的计算架构和自我学习、不断提高的闭环能力。这三个条件是我今天要说的第一件事。
我们下面进入到主题。在人机大战中,柯洁给我们留下一句话,柯洁说,AlphaGo 看上去像「神」一样的存在,好像它是无懈可击的。我们从机器学习的角度来说 AlphaGo 到底有没有弱点呢?我个人的观点是,它是有弱点的,而且这个弱点还挺严重:这个弱点就是它没有「迁移学习」的能力,而迁移学习是我们人类智慧的一种特质。

迁移学习这个特质体现在智慧的什么方面呢?
机器的一个能力是能够在大量的数据里面学习,所以数据的质量是非常重要的,这是我们学到的一点。但是,你能不能在 19×19 的棋盘学到一个知识,再把它推广到 21×21 的棋盘?你在学会下围棋之后,你能不能去下象棋?你学会了下围棋,能不能把它运用在生活当中?运用到生活的方方面面、商业活动、日常活动、指挥机器人的行动当中呢?
机器在今天是没有这个推广能力的,这就是我今天要说的题目。
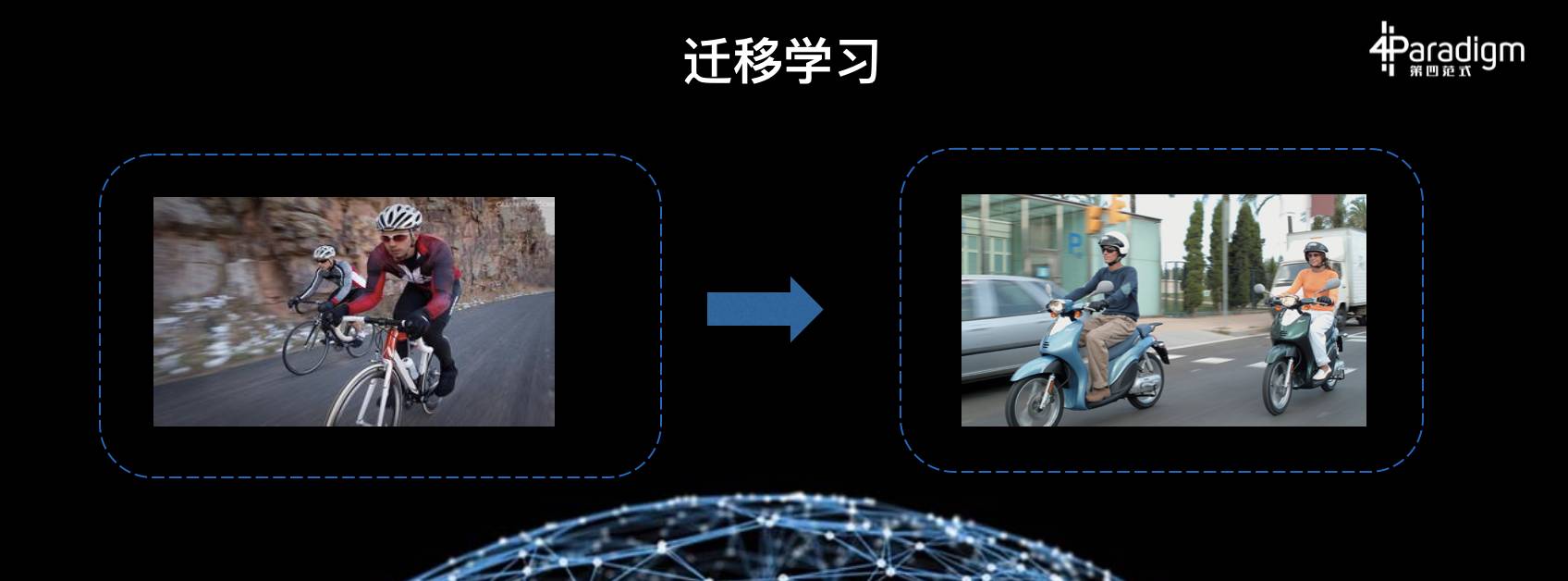
在人类的进化演进当中,迁移学习这种能力是非常重要的。比如说,我们人类在学会骑自行车以后,再骑摩托车就非常容易了,这对于人来说是非常容易的;我们看一两张图片,就可以把它扩展到许多其他不同的景象,这种能力也是非常强的;我们有了知识,把这个知识再推广到其他的知识当中,这个能力说明我们人这个计算系统有什么能力呢?叫可靠性,我们能把我们过去的经验带到不同的场景,这样就有了一种能够适应的能力。
那么,我们怎样才能让机器也具有这种能力呢?我再给大家一个例子,让大家去想一想。
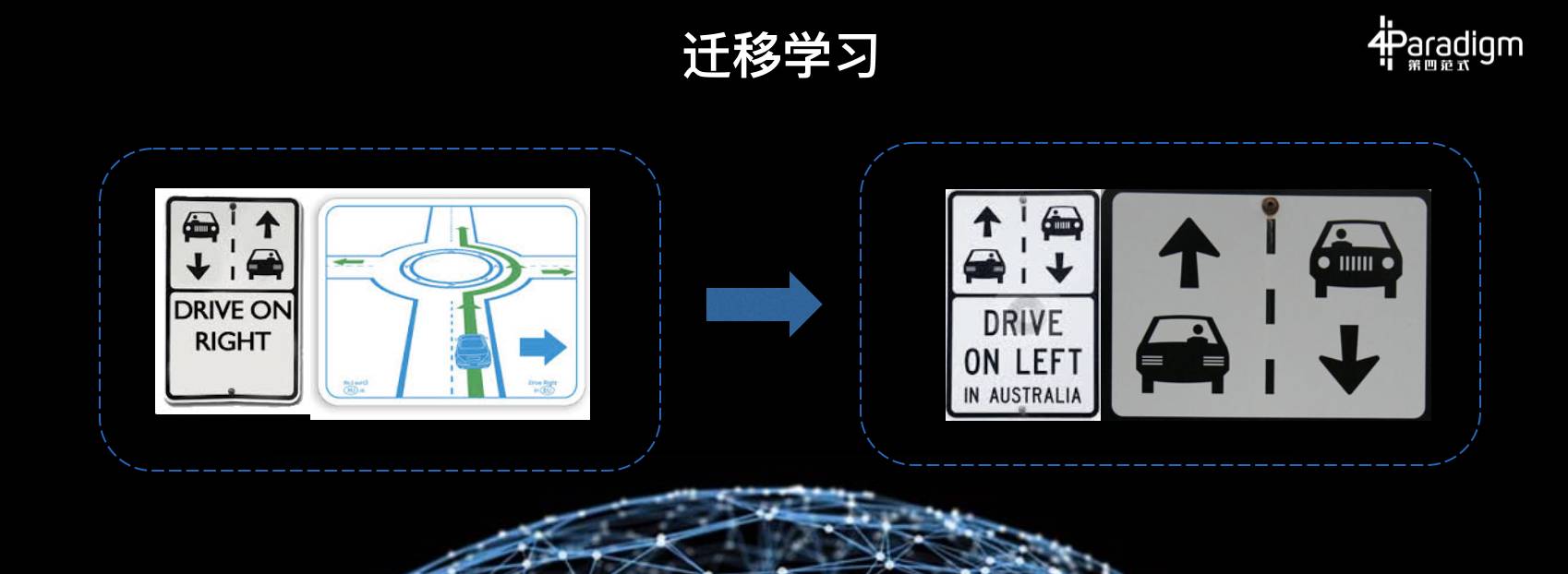
我是从香港科技大学过来,现在我们在北京。我们知道在北京开车,司机是坐在车的左边,在香港开车,司机是坐在车的右边。我们在北京学会开车以后,如果去香港租车,怎么能够很快地学会在香港开车而不出事呢?这个就是一个诀窍,我把这个诀窍叫作「迁移学习的诀窍。」
大家可能都有过类似的经验,我告诉你们答案,就是司机的座位总是最靠近路中间的,不管你是在北京开车,还是在香港开车,大家不妨去试一试。这就说明什么呢?这就说明迁移学习的要素就是发现共性,发现两个领域之间的共性。如果一旦发现了这种关键的共性,迁移就非常容易。我们在机器学习里叫做特征,发现这种共同的特征。
迁移学习的三大好处
下面我要说一下,为什么我们要研究迁移学习?
首先,我们在生活当中遇到更多的是小数据。家里的小朋友看一张猫的图片,那么当他再看到一只真猫,就会说这是猫。我们不用给他一千万个正例、一千万个负例,他就能具有这种能力,人是自然就有这种能力的。因此,小数据上的学习如何能够实现?这才是真正的智能。
第二个好处,可靠性。我们造一个系统,希望它不仅在那个领域能够发挥作用,在周边的领域也能发挥作用。当我们把周边的环境稍微改一改的时候,这个系统还是可以一样的好,这个就是可靠性。我们可以举一反三、融会贯通,这也是我们赋予人的智慧的一种定义。
第三个好处,我们现在越来越多地强调个性化。我们在手机上看新闻、看视频,手机为我们做提醒,以后家里面会有机器人,这些都是要为我们个人提供服务的,而这个服务越个性化越好。
但大家有没有想过,个性的数据往往都是小数据。也就是说,我们可以把几千、几万、几百万人的数据综合在云端,但那样做出的一个系统只是一个通用型的系统。我们更重要的是如何能够把通用的系统加上个人的小数据,就把它迁移到个人的场景当中去。不管是视觉,还是语音识别、推荐等等,其实我们都需要向个性化方向发展,那么迁移学习就是一个必不可少的工具。

说了这些好处之后,来看一下为什么今天迁移学习还没有大规模地推广?这是因为迁移学习本身是非常非常难的。如上图所示,这里问的是教育学里面的问题,问的是 Learning Transfer,也就是「学习迁移。」
在教育学里面,对于如何把知识迁移到不同的场景,也是非常关心的。在教育学,这个理念已经有上百年的历史。就是说如果我们想来衡量一个老师的好坏,我们往往可以不通过学生的期末考试,因为那种只是考特定的知识,学生有的时候死记硬背也可以通过考试。一个更好的方法,是观察这个学生在上完这门课之后的表现,他有多大的能力能够把这门课的知识迁移到其他的课里去。那个时候我们再回来说,这个老师的教学是好是坏,这个叫学习迁移。所以,在教育学里大家就在问,为什么学习迁移是如此的难?这个难点就是在如何发现共同点。
再回到我刚才开车的例子,在座有多少人经历过从左边开车到右边开车这种非常苦恼的事实?对于我们人来说,发现这种共性也是很难的。好在,现在迁移学习这个领域已经有了十年到二十年努力的结果。
六个进展
迁移学习如此重要,所以有大批的研究者投身到迁移学习的研究中去。下面,我们来看看迁移学习的研究有哪些最新进展。
迁移学习进展一:结构与内容分离

如果我们面临一个机器学习问题,并想要发现不同问题之间的共性,那么我们可以把问题的结构和问题的内容剥离开。虽然这样的分离并不容易,但是一旦能够完成,那么系统举一反三的能力就非常强了。举个例子,大家可能认为写电影剧本是一个非常需要艺术,非常需要天才的工作。但是大家可能不知道,写电影剧本也可以变得像工厂一样。剧作家的诀窍就是把内容和结构剥离开,他们知道电影头 10 分钟该演什么,后 5 分钟又该演什么,在什么时候应该催人泪下,在什么时候让大家捧腹大笑,这些都是有结构的。
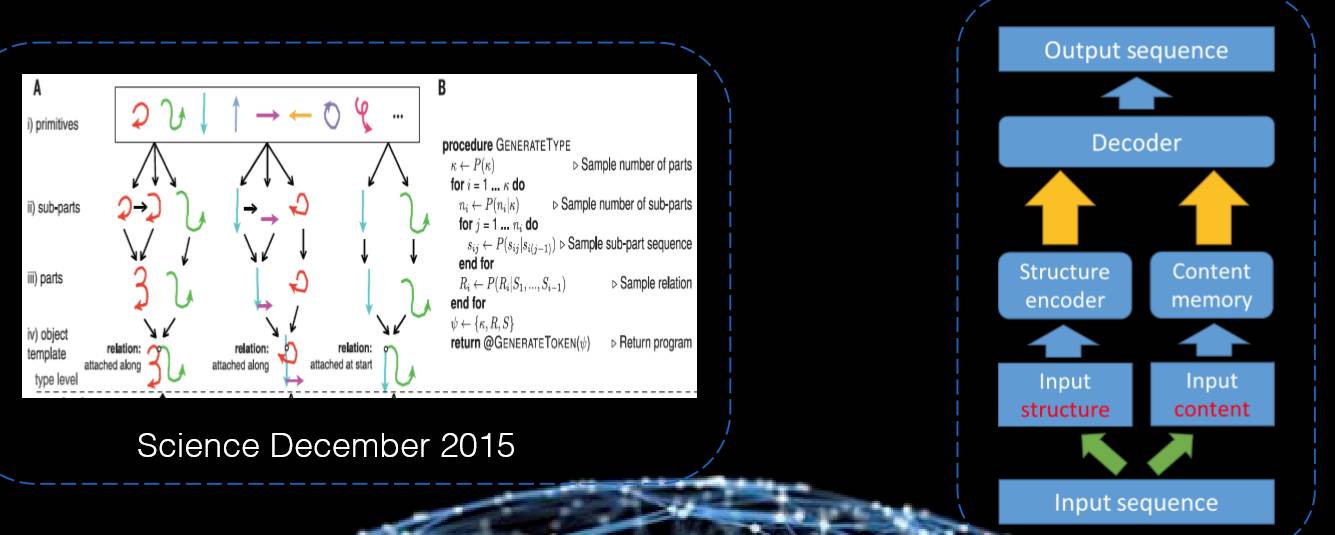
怎样让机器学习也具有这个能力呢?上图的左边是 2005 年《Science》的一篇文章,该论文在手写识别上把结构和手写的方式区分开,并发现了在学习结构的这一方面用一个例子就可以了,所以这也就是单个例学习。
右边是博士生吴宇翔同学最近在进行的一项研究,在大规模的文本上,如果我们能够把文本的结构和具体的内容用一个深度学习网络给区分开的话,那么学到结构这一部分的系统就很容易迁移到自然语言系统并处理不同的任务。比如说主题识别、自动文本摘要、自动写稿机器人等,这一部分真的比较有前景。
第二个进展:多层次的特征学习
过去我们在学习方面太注重发现共性本身,但是却没有注意在不同的层次之间发现这些共性。但现在发现,如果我们把问题分到不同层次,有些层次就更容易帮助我们进行机器学习的迁移。
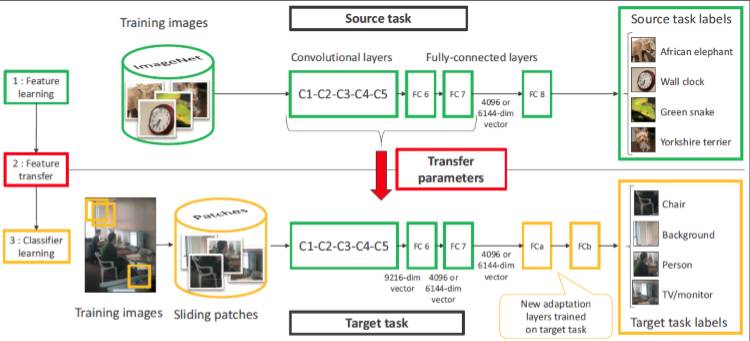
如上图图像识别任务中,如果我们在一个领域已经用了上千万的数据训练好了一个八层的深度学习模型,但现在如果我们改变了该分类任务的类别,那么传统的机器学习就必须重新进行训练。但是现在用了这种层次型的迁移学习,我们会发现,不同的层次具有不同的迁移能力,这样对于不同的层次的迁移能力就有了一个定量的估计。所以,当我们需要处理新任务时,就可以把某些区域或某些层次给固定住,把其他的区域用小数据来做训练,这样就能够达到迁移学习的效果。
在语音任务当中,假设我们已经训练出一个播音员的语音模型,那么我们如果把它迁移到一种带口音的语音中呢?我们其实也可以用这种层次化的迁移,因为如果我们发现一些共性的、内在的层次是语音共同的模式,那么我们就可以把它迁移过来,再使用小数据就能训练方言了。
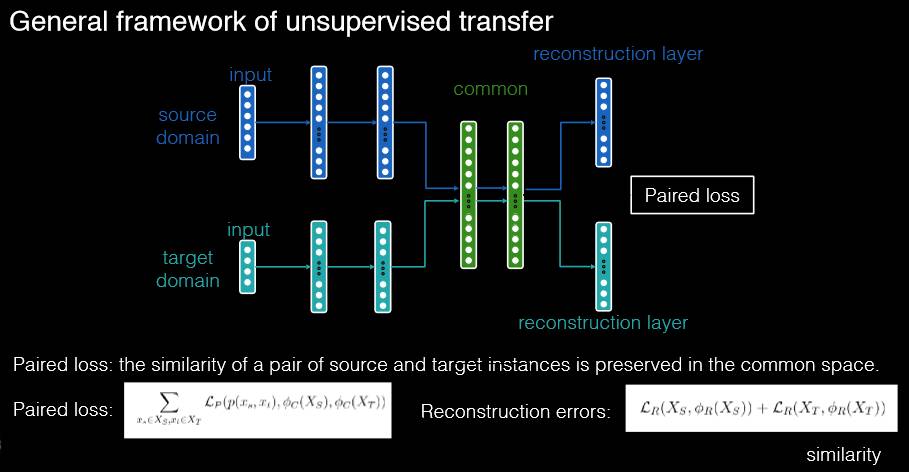
同时如上图所示,我们对于结构也可以像工程师一样,进行各种各样的变换,比如说我们可以在图像、文字之间发现他们语义的共性。同时如果我们可以用一个多模态的深度学习网络把内部语义学出来,这样就可以在文字和图像之间自由的迁移。所以这种多层的迁移,确实带来很多的便利。
第三个进展:从一步到位的迁移学习,到多步、传递式的迁移学习
过去的迁移学习,往往是我也有一个领域已经做好了模型,而目标是把它迁移到一个新的领域。这种从旧领域迁移到新领域,从一个多数据的领域迁移到少数据的领域,这种称之为单步迁移。但是我们现在发现,很多场景是需要我们分阶段进行的,这就像过河,需要踩一些石头一步步过去。
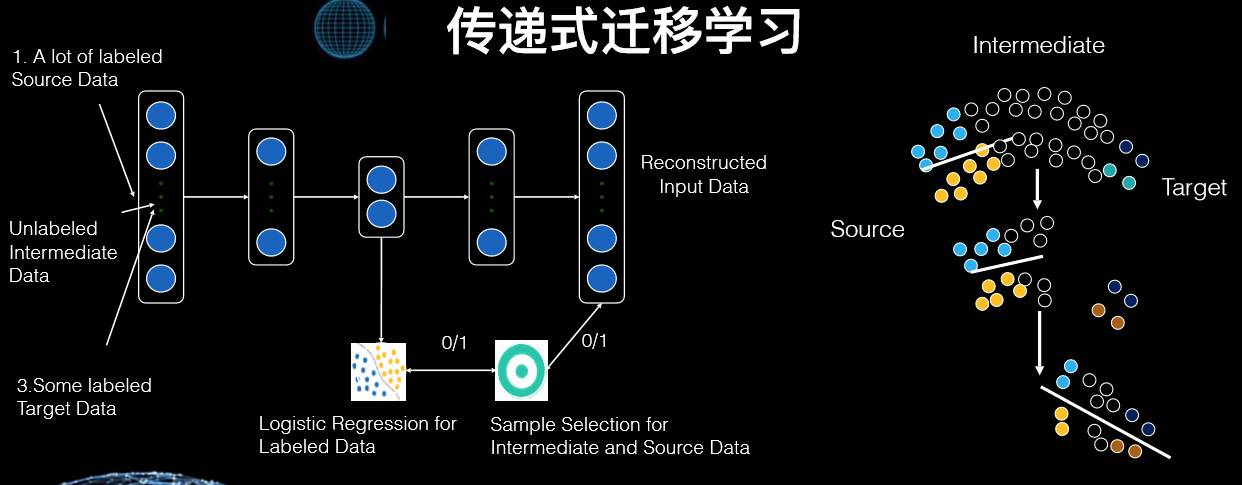
采用这个思想,我们也可以进行多步传导式的迁移。比如说我们可以构建一个深度网络,而这个网络的中间层就既能照顾目标这个问题领域,又能照顾原来的领域。同时如果我们有一些中间领域,那么其可以把原领域和目标领域一步步的衔接起来,A 和 B、B 和 C、C 和 D。这样我们就可以定义两个目标函数,左下角目标函数的任务就是分类,并且分类分得越准越好,右下角第二个目标函数需要区分在中间领域到底抽取哪些样本和特征,使得其对最后的优化函数是有用的。当这两个目标函数一同工作时,一个优化了最后的目标,而另一个则选择了样本。如此迭代,逐渐就如同右边那个图一样,原领域的数据就从多步迁移到目标领域去了。
最近斯坦福大学有一个实际的例子,他们利用这种多步迁移方法,并通过卫星图像来分析非洲大陆的贫穷状况。从白天到晚上的卫星图像是第一步迁移,从晚上的图像、灯光到这个地方发达程度是第二步迁移。因此我们通过这两步的迁移成功地建立了一个模型,即通过卫星图像分析地方的贫困状况。
第四个进展:学习如何迁移
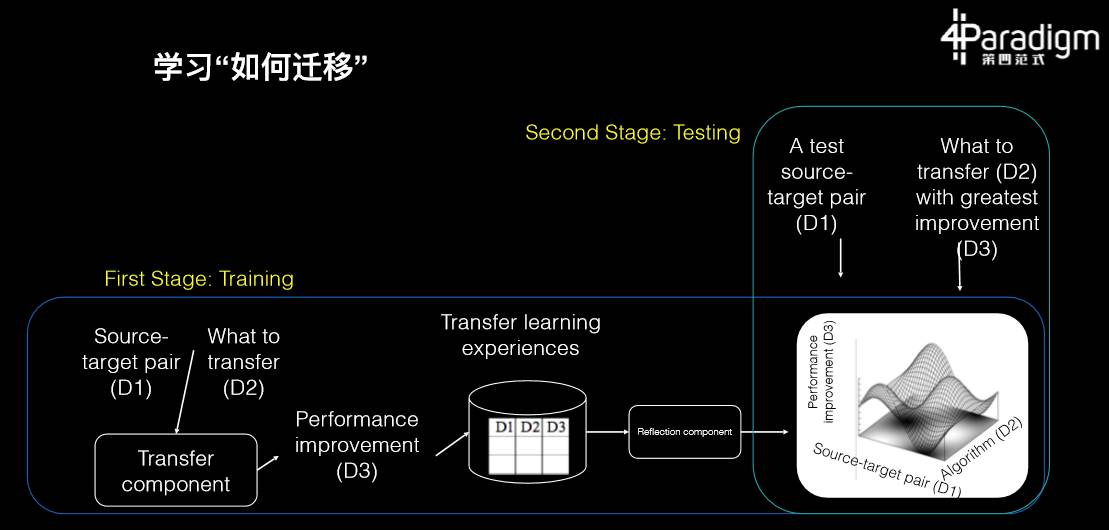
这 20 年当中我们积累了大量的知识,并且有很多种迁移学习的算法,但现在我们常常遇到一个新的机器学习问题却不知道到底该用哪个算法。其实,既然有了这么多的算法和文章,那么我们可以把这些经验总结起来训练一个新的算法。而这个算法的老师就是所有这些机器学习算法、文章、经历和数据。所以,这种学习如何迁移,就好像我们常说的学习如何学习,这个才是学习的最高境界,也就是学习方法的获取。
博士生魏颍就在做这样的研究,他最后学出的效果就是在给定任何一个迁移学习问题,系统可以自动在过去所有我们尝试过的算法里面,利用经验找到最合适的算法,其可以是基于特征的、基于多层网络的、基于样本的或者是基于某种混合。
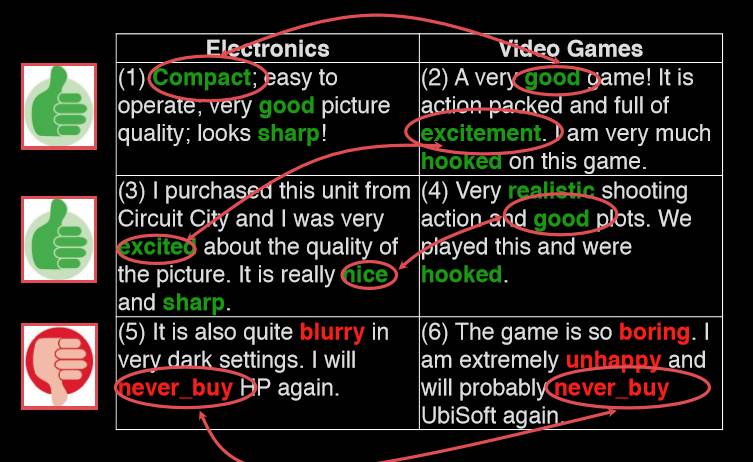
如上图所示有一个具体应用在舆情分析上的案例。我们知道舆情分析就是给定一些文本、标注,然后学一个模型,这样再给一些新用户的反馈,我们就知道它是正面还是负面。但是这种迁移是很难的,因为我们往往面临的是两个领域,左边这个是带有标注的,右边这个是没有标注的。而关键是如何把左边和右边连起来,我们如何能够建立词语和词语之间的联系,才能把具有标注的数据模型成功地迁移到没有标注的模型上,这些绿色的词和绿色的词应该是对应的,红色的词和红色的词应该是对应的,但是机器并不知道这一点。
该问题过去是由人类标注,但现在我们发现,原来舆情分析的迁移,其中文本当中的每一个字都具有一个连接的能力,而不是说有些词是连接词,其他词都不是,每一个词在不同的程度具有大小不同的概率,能够把两个领域连接起来,关键是机器如何能够自动地发现它。
第五个进展:迁移学习作为元学习
第五个进展,把迁移学习本身作为一个元学习(Meta Learning)的方法,赋予到不同学习的方式上。假设以前我们有一个机器学习的问题或者是模型,现在你只要在上面套一个迁移学习的罩子,它就可以变成一个迁移学习的模型了。这种套一个罩子的办法怎样才能够实现呢?我们现在就在强化学习和深度学习上做这样的实验,假设你已经有一个深度学习模型和一个强化学习模型,那么我们在上面做一个「外套」,能够把它成功变成一个迁移学习模型。
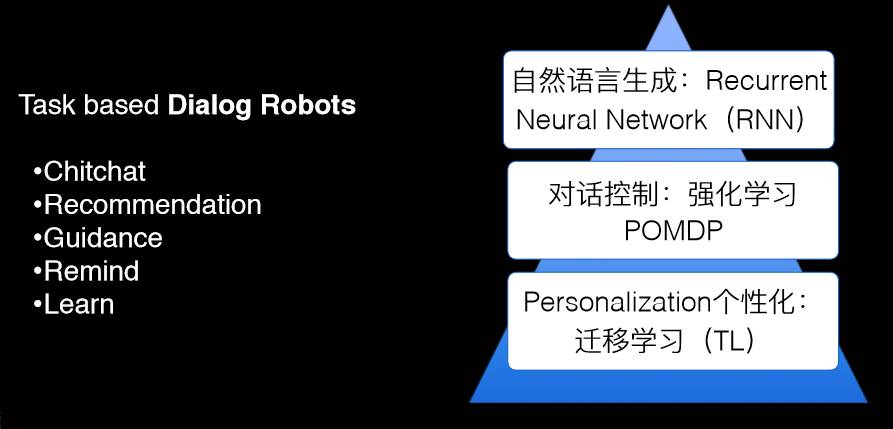
举个例子,假设存在个性化的人机对话系统,而我们做了一个任务型的对话系统,它是可以帮助我们做通用型的对话。但是如何能够把这个系统变成一个个人的、个性化的系统呢?我们既用深度学习、RNN,又用强化学习和所谓的 POMDP 来做了一个通用型的任务学习系统。现在我们就可以通过几个个性化的例子而得到个性化的选择。
迁移学习进展 6:数据生成式迁移学习
下面进入到最后一个进展,即数据生成式的迁移学习。我们最近听到比较多的是生成式对抗网络,这个词听起来有点复杂,但是这个图就是最好的解释。对于生成式对抗网络来说,图灵测试外面的裁判是学生,里面的那个机器也是学生,他们两个人的目的是在对抗中共同成长,在问问题当中,假设提问者发现一个是机器了,那么就告诉机器你还不够真,还需要提高自己。而如果机器发现它把人骗过了,那么它可以去告诉外面这个裁判,它还不够精明,还需要提高自己。这样两方不断互相刺激,形成一种对抗,这个是一种共同学习的特点。
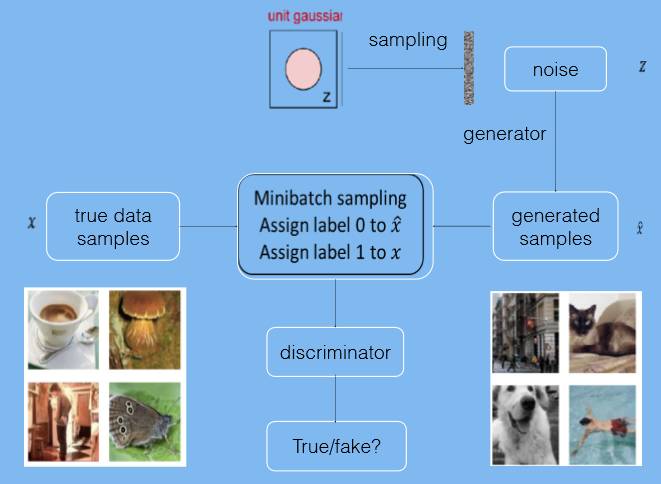
所以,这种生成式对抗网络的一个特点,通过小数据可以生成很多模拟数据,通过模拟数据又来判定它是真的还是假的,用以刺激生成式模型的成长。这个就好象是计算机和人之间的博弈,下图左边展示的是一棵博弈树。
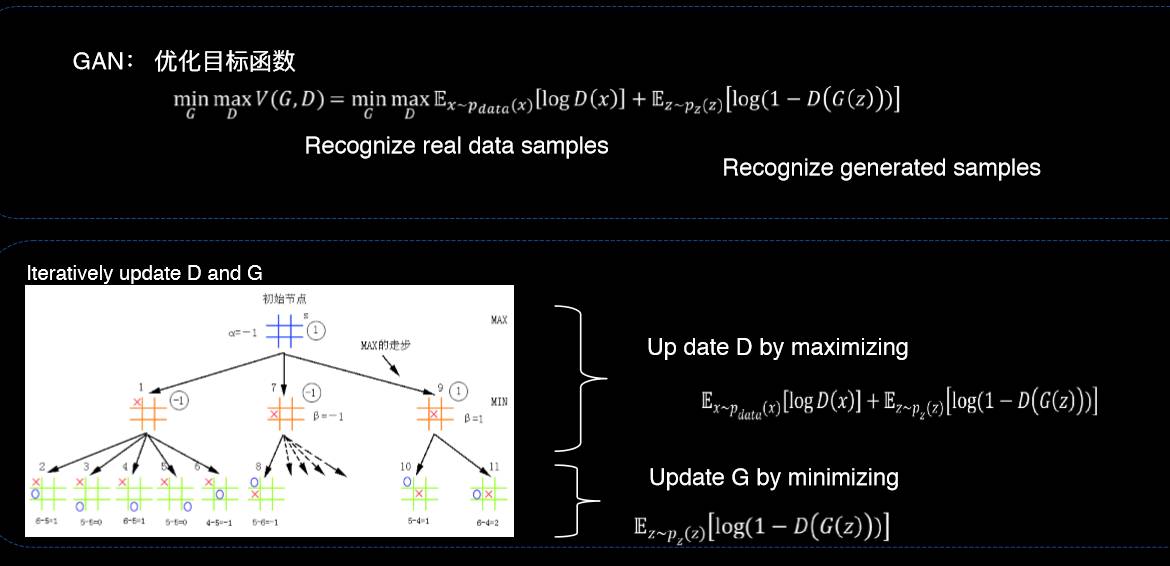
我们可以用这个方法来做迁移学习,这里举的一个例子是最近的一项工作,我们用判别式模型来区分数字到底是来自于源数据还是目标数据。我们让生成式模型不断模拟新的领域,使得到最后我们能够产生出一大堆新数据,它的数据就是和真实的数据非常的一致。通过这个办法,一个判别器区分领域,另外一个生成器在生成数据,我们就可以通过小数据产生更多的数据,在新的领域就可以实现迁移学习的目的。
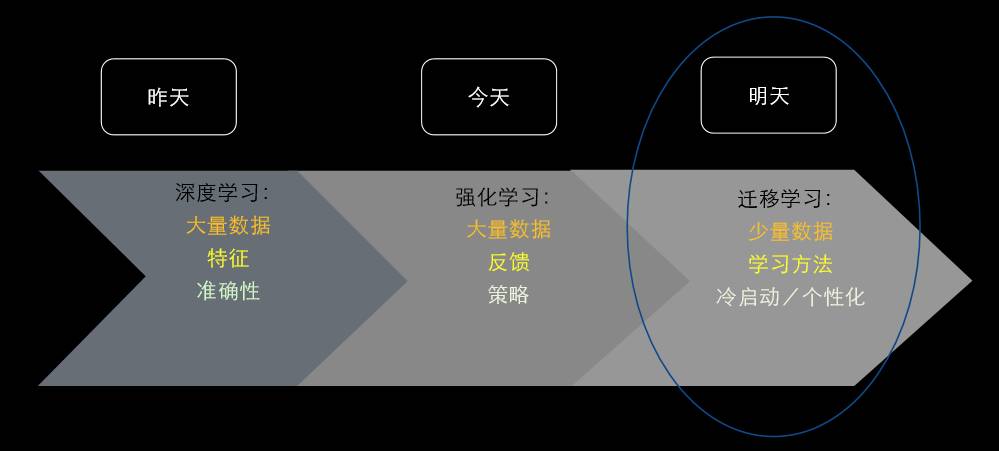
最后我要说,我们在深度学习上已经有了很大的成就,我们今天也在努力进行各种强化学习的尝试(比如说 AlphaGo),但是我认为机器学习的明天是在小数据、个性化、可靠性上面,那就是迁移学习,这是我们的明天。
谢谢大家!
更多有关GMIS 2017大会的内容,请点击「阅读原文」查看机器之心官网 GMIS 专题↓↓↓











