
前言
为何要测试
以前不喜欢写测试,主要是觉得编写和维护测试用例非常的浪费时间。在真正写了一段时间的基础组件和基础工具后,才发现自动化测试有很多好处。测试最重要的自然是提升代码质量。代码有测试用例,虽不能说百分百无bug,但至少说明测试用例覆盖到的场景是没有问题的。有测试用例,发布前跑一下,可以杜绝各种疏忽而引起的功能bug。
自动化测试另外一个重要特点就是快速反馈,反馈越迅速意味着开发效率越高。拿UI组件为例,开发过程都是打开浏览器刷新页面点点点才能确定UI组件工作情况是否符合自己预期。接入自动化测试以后,通过脚本代替这些手动点击,接入代码watch后每次保存文件都能快速得知自己的的改动是否影响功能,节省了很多时间,毕竟机器干事情比人总是要快得多。
有了自动化测试,开发者会更加信任自己的代码。开发者再也不会惧怕将代码交给别人维护,不用担心别的开发者在代码里搞“破坏”。后人接手一段有测试用例的代码,修改起来也会更加从容。测试用例里非常清楚的阐释了开发者和使用者对于这端代码的期望和要求,也非常有利于代码的传承。
考虑投入产出比来做测试
说了这么多测试的好处,并不代表一上来就要写出100%场景覆盖的测试用例。个人一直坚持一个观点:基于投入产出比来做测试。由于维护测试用例也是一大笔开销(毕竟没有多少测试会专门帮前端写业务测试用例,而前端使用的流程自动化工具更是没有测试参与了)。对于像基础组件、基础模型之类的不常变更且复用较多的部分,可以考虑去写测试用例来保证质量。个人比较倾向于先写少量的测试用例覆盖到80%+的场景,保证覆盖主要使用流程。一些极端场景出现的bug可以在迭代中形成测试用例沉淀,场景覆盖也将逐渐趋近100%。但对于迭代较快的业务逻辑以及生存时间不长的活动页面之类的就别花时间写测试用例了,维护测试用例的时间大了去了,成本太高。
Node.js模块的测试
对于Node.js的模块,测试算是比较方便的,毕竟源码和依赖都在本地,看得见摸得着。
测试工具
测试主要使用到的工具是测试框架、断言库以及代码覆盖率工具:
1、测试框架:Mocha、Jasmine等等,测试主要提供了清晰简明的语法来描述测试用例,以及对测试用例分组,测试框架会抓取到代码抛出的AssertionError,并增加一大堆附加信息,比如那个用例挂了,为什么挂等等。测试框架通常提供TDD(测试驱动开发)或BDD(行为驱动开发)的测试语法来编写测试用例,关于TDD和BDD的对比可以看一篇比较知名的文章The Difference Between TDD and BDD。不同的测试框架支持不同的测试语法,比如Mocha既支持TDD也支持BDD,而Jasmine只支持BDD。这里后续以Mocha的BDD语法为例
2、断言库:Should.js、chai、expect.js等等,断言库提供了很多语义化的方法来对值做各种各样的判断。当然也可以不用断言库,Node.js中也可以直接使用原生assert库。这里后续以Should.js为例
3、代码覆盖率:istanbul等等为代码在语法级分支上打点,运行了打点后的代码,根据运行结束后收集到的信息和打点时的信息来统计出当前测试用例的对源码的覆盖情况。
一个煎蛋的栗子
以如下的Node.js项目结构为例
├── LICENSE
├── README.md
├── index.js
├── node_modules
├── package.json
└── test
└── test.js
首先自然是安装工具,这里先装测试框架和断言库:npm install --save-dev mocha should。装完后就可以开始测试之旅了。
比如当前有一段js代码,放在index.js里
'use strict';
module.exports = () => 'Hello Tmall';
那么对于这么一个函数,首先需要定一个测试用例,这里很明显,运行函数,得到字符串Hello Tmall就算测试通过。那么就可以按照Mocha的写法来写一个测试用例,因此新建一个测试代码在test/index.js
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('should get "Hello Tmall"', () => {
mylib().should.be.eql('Hello Tmall');
});
});
测试用例写完了,那么怎么知道测试结果呢?
由于我们之前已经安装了Mocha,可以在node_modules里面找到它,Mocha提供了命令行工具_mocha,可以直接在./node_modules/.bin/_mocha找到它,运行它就可以执行测试了:
Hello Tmall
这样就可以看到测试结果了。同样我们可以故意让测试不通过,修改test.js代码为:
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('should get "Hello Taobao"', () => {
mylib().should.be.eql('Hello Taobao');
});
});
就可以看到下图了:
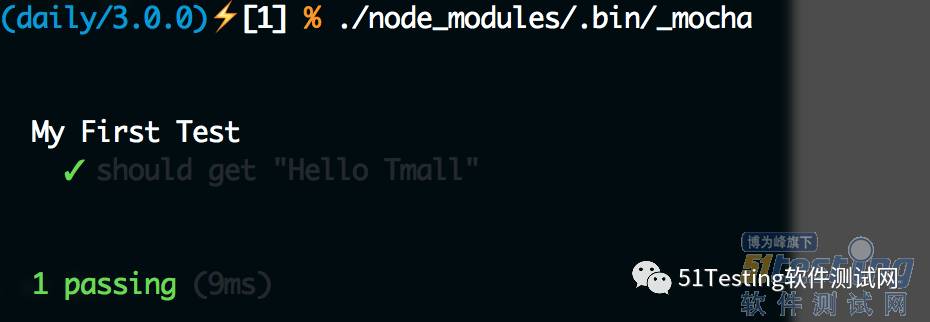
Taobao is different with Tmall
Mocha实际上支持很多参数来提供很多灵活的控制,比如使用./node_modules/.bin/_mocha --require should,Mocha在启动测试时就会自己去加载Should.js,这样test/test.js里就不需要手动require('should');了。更多参数配置可以查阅Mocha官方文档。
那么这些测试代码分别是啥意思呢?
这里首先引入了断言库Should.js,然后引入了自己的代码,这里it()函数定义了一个测试用例,通过Should.js提供的api,可以非常语义化的描述测试用例。那么describe又是干什么的呢?
describe干的事情就是给测试用例分组。为了尽可能多的覆盖各种情况,测试用例往往会有很多。这时候通过分组就可以比较方便的管理(这里提一句,describe是可以嵌套的,也就是说外层分组了之后,内部还可以分子组)。另外还有一个非常重要的特性,就是每个分组都可以进行预处理(before、beforeEach)和后处理(after, afterEach)。
如果把index.js源码改为:
'use strict';
module.exports = bu => `Hello ${bu}`;
为了测试不同的bu,测试用例也对应的改为:
'use strict';
require('should');
const mylib = require('../index');
let bu = 'none';
describe('My First Test', () => {
describe('Welcome to Tmall', () => {
before(() => bu = 'Tmall');
after(() => bu = 'none');
it('should get "Hello Tmall"', () => {
mylib(bu).should.be.eql('Hello Tmall');
});
});
describe('Welcome to Taobao', () => {
before(() => bu = 'Taobao');
after(() => bu = 'none');
it('should get "Hello Taobao"', () => {
mylib(bu).should.be.eql('Hello Taobao');
});
});
});
同样运行一下./node_modules/.bin/_mocha就可以看到如下图:
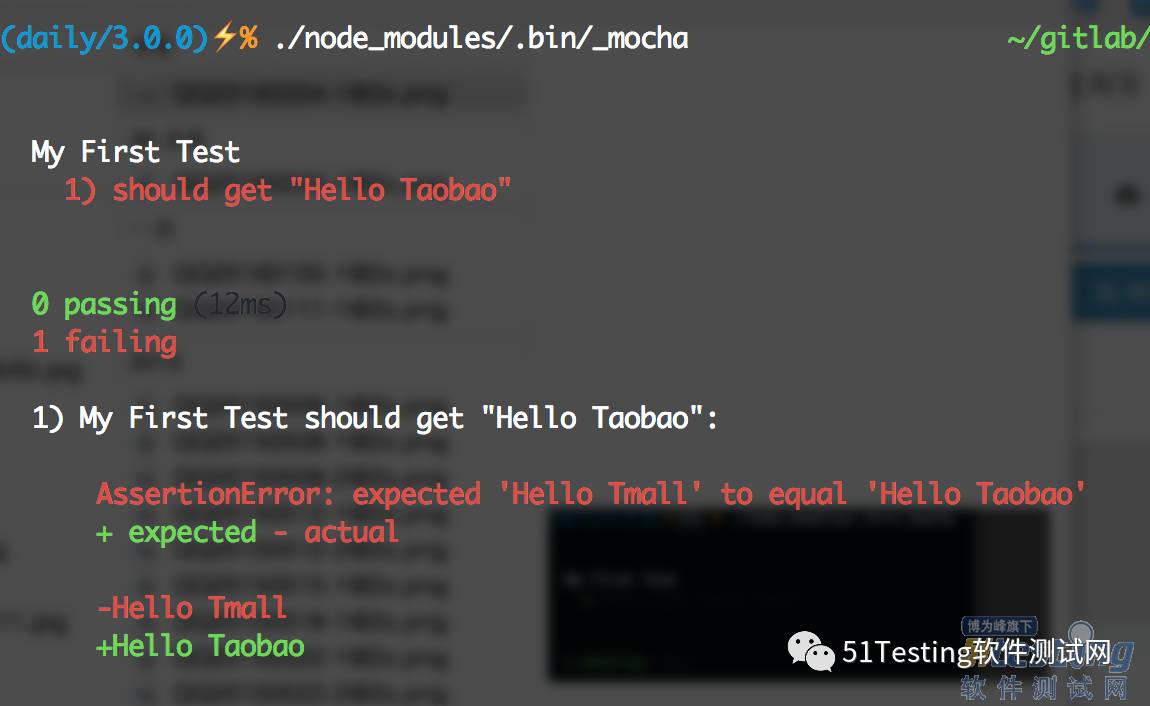
all bu welcomes you
这里before会在每个分组的所有测试用例运行前,相对的after则会在所有测试用例运行后执行,如果要以测试用例为粒度,可以使用beforeEach和afterEach,这两个钩子则会分别在该分组每个测试用例运行前和运行后执行。由于很多代码都需要模拟环境,可以再这些before或beforeEach做这些准备工作,然后在after或afterEach里做回收操作。
异步代码的测试
回调
这里很显然代码都是同步的,但很多情况下我们的代码都是异步执行的,那么异步的代码要怎么测试呢?
比如这里index.js的代码变成了一段异步代码:
'use strict';
module.exports = (bu, callback) => process.nextTick(() => callback(`Hello ${bu}`));
由于源代码变成异步,所以测试用例就得做改造:
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('Welcome to Tmall', done => {
mylib('Tmall', rst => {
rst.should.be.eql('Hello Tmall');
done();
});
});
});
这里传入it的第二个参数的函数新增了一个done参数,当有这个参数时,这个测试用例会被认为是异步测试,只有在done()执行时,才认为测试结束。那如果done()一直没有执行呢?Mocha会触发自己的超时机制,超过一定时间(默认是2s,时长可以通过--timeout参数设置)就会自动终止测试,并以测试失败处理。
当然,before、beforeEach、after、afterEach这些钩子,同样支持异步,使用方式和it一样,在传入的函数第一个参数加上done,然后在执行完成后执行即可。
Promise
平常我们直接写回调会感觉自己很low,也容易出现回调金字塔,我们可以使用Promise来做异步控制,那么对于Promise控制下的异步代码,我们要怎么测试呢?
首先把源码做点改造,返回一个Promise对象:
'use strict';
module.exports = bu => new Promise(resolve => resolve(`Hello ${bu}`));
当然,如果是co党也可以直接使用co包裹:
'use strict';
const co = require('co');
module.exports = co.wrap(function* (bu) {
return `Hello ${bu}`;
});
对应的修改测试用例如下:
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('Welcome to Tmall', () => {
return mylib('Tmall').should.be.fulfilledWith('Hello Tmall');
});
});
Should.js在8.x.x版本自带了Promise支持,可以直接使用fullfilled()、rejected()、fullfilledWith()、rejectedWith()等等一系列API测试Promise对象。
注意:使用should测试Promise对象时,请一定要return,一定要return,一定要return,否则断言将无效
异步运行测试
有时候,我们可能并不只是某个测试用例需要异步,而是整个测试过程都需要异步执行。比如测试Gulp插件的一个方案就是,首先运行Gulp任务,完成后测试生成的文件是否和预期的一致。那么如何异步执行整个测试过程呢?





