选自arXiv
作者:Iulian V. Serban等
机器之心编译
参与:路雪、李泽南
The Alexa Prize 是亚马逊在对话人工智能领域中发起的一项竞赛,本届比赛的奖金为 250 万美元,将于 11 月决出优胜者。本文介绍的是蒙特利尔大学 Yoshua Bengio 团队(MILA Team)参与本次比赛的 Chatbot 设计。
对话系统和聊天智能体(包括聊天机器人、个人助理和声控界面)在现代社会中越来越普遍。比如,移动设备内置的个人助理、电话中的自动技术支持、卖东西的在线机器人(从时尚服饰、化妆品到法律咨询、自助医疗服务)。但是,构建智能聊天机器人仍然是人工智能研究中未解决的一个重要问题。
2016 年,亚马逊主办了一场国际大学竞赛,旨在构建社交机器人——一款能够与人类就热门话题进行连贯可爱的语音对话的智能体,话题涉及娱乐、时尚、政治、体育、技术等领域。社交机器人通过亚马逊的 Echo 设备进行自然语音交谈(Stone & Soper 2014)。本文描述了该模型、实验和我们团队开发的最终系统(MILABOT)。我们参与该比赛的主要动机是帮助推动人工智能的研究。该竞赛提供了一个特别的机会,用真实用户在相对宽松的设置中对先进的机器学习算法进行训练和测试(即自然环境中的机器学习)。用真实用户进行实验在人工智能社区是独特的,大部分工作的实验在固定数据集(如标注数据集)和软件仿真(如游戏引擎)进行。此外,亚马逊提供的计算资源、技术支持和资金支持也对我们在扩展系统、测试先进机器学习方法等工作上帮助很大。这些支持帮助我们在 Amazon Mechanical Turk 平台通过众包方式处理了 20 万个标签,并维护系统运行所需的 32 个 Tesla K80 GPU。
我们的社交机器人基于大型综合系统,该系统结合深度学习和强化学习。我们开发了一套新的深度学习模型用于自然语言检索和生成,包括循环神经网络、序列到序列模型和隐变量模型,并在竞赛提供的上下文中对其进行评估。这些模型连接成一个整体,生成一个对话响应的候选集合。我们进一步使用强化学习(包括价值函数和策略梯度方法)训练该系统,以从综合系统的模型中选择一个合适的响应。尤其是,我们提出了一种新型强化学习步骤,基于对马尔科夫决策过程的评估进行。训练在众包数据上进行,真实用户和该系统初代版本之间的互动被记录下来。训练后的系统在真实用户进行的 A/B 测试实验中取得了巨大的进步。
在竞赛半决赛中,我们表现最好的系统在级别 1 − 5 上获得 3.15 的用户平均分,手工干预的状态和规则数量最少,且未参与非聊天活动(如玩游戏或猜谜)。最佳系统的表现可以媲美半决赛中的部分顶级系统。该系统平均每次对话包括 14.5 − 16.0 轮。用户和系统的反复交流产生的这个改进说明我们的系统可能是参与竞赛的所有系统中互动性最强的系统。最后,如果有额外的数据,该系统还能够继续改进,因为几乎所有的系统模块都是可学习的。
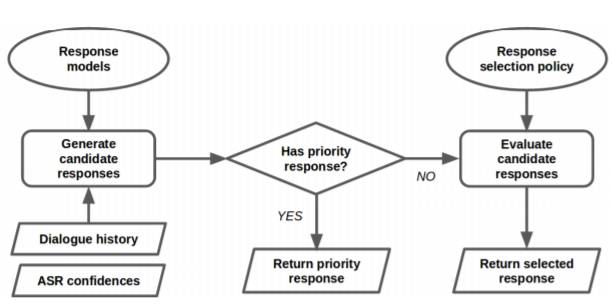
图 1:对话管理器控制流程。
该系统包含 22 个响应模型,包括基于检索的神经网络、基于生成的神经网络、基于知识库的问答系统和基于模板的系统。候选模型响应的示例如表 1 所示。
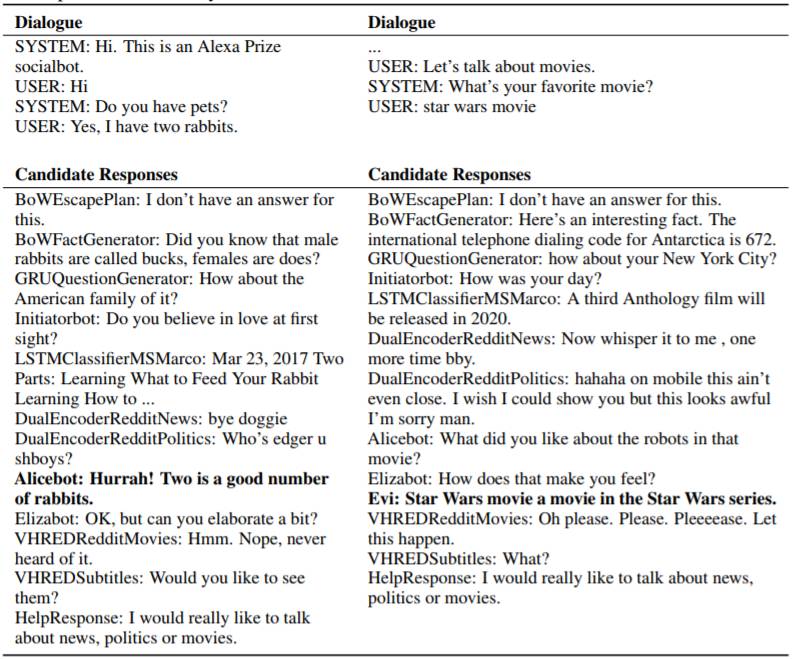
表 1:由模型生成的对话与候选语句。最终系统的回答语句为粗体。
模型架构
评分模型是一个 5 层神经网络,第一层作为输入,包含 1458 个特征。第二层包含 500 个隐藏单元,通过将线性变换和修正的线性激活函数(Nair&Hinton,2010;Glorot 等,2011)应用于输入层单元进行计算。第三层包含 20 个隐藏单元,通过对前一层单元应用线性变换来计算。类似于矩阵分解,这一层将 500 个隐藏单元压缩至 20 个。第四层包含 5 个输出单元,它使用了概率(即所有数值都是正值同时和为 1)。这些输出单元是通过对前一层单元应用线性变换,然后进行 softmax 变换来计算的。该层对应于 Amazon Mechanical Turk 上获得的标签。第五层是通过对第三层和第四层中的单元应用线性变换来计算的最终输出标量。该模型如图 2 所示:
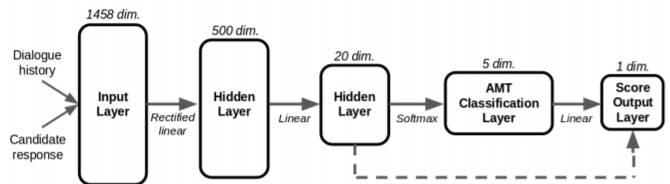
图 2:评分模型的计算图,基于行为价值函数和统计策略参数化用于模型选择策略。该模型包含一个带有 1485 个特征的输入层、一个带有 500 个隐藏单元的隐藏层、带有 20 个隐藏单元的隐藏层、带有 5 个输出可能性的 softmax 层(对应论文章节 4.3 中的 5 个 AMT 标签)、一个标量值输出层。虚线箭头表示一个 skip 连接。
论文:A Deep Reinforcement Learning Chatbot

论文链接:https://arxiv.org/abs/1709.02349
我们展示了 MILABOT:蒙特利尔算法研究实验室(MILA)为参与亚马逊 Alexa 大奖赛而开发的深度强化学习聊天机器人。MILABOT 能够与人类就流行的闲聊话题进行语音和文本交流。该系统包括一系列自然语言生成和检索模型,如模板模型、词袋模型、序列到序列神经网络和隐变量神经网络模型。通过将强化学习应用到众包数据和真实用户互动中进行训练,该系统学习从自身包含的一系列模型中选择合适的模型作为响应。真实用户使用 A/B 测试对该系统进行评估,其性能大大优于竞争系统。由于其机器学习架构,该系统的性能在额外数据的帮助下还有可能继续提升。 
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]








