打车、导航、外卖、AR 红包等各种基于位置的应用已经成为我们日常生活的重要组成部分,但位置的隐私安全也随之成为了我们需要关注的问题之一。近日,微软亚洲研究院高级研究经理 Winnie Cui 在微软研究博客上发文介绍了他们为位置隐私安全所提出的一种新算法 PrivTree。点击文末「阅读原文」可查阅相关论文。
数据科学家 Anthony Tockar 在西北大学攻读硕士学位期间曾经尝试了一个研究,成功利用网上公开的数据追踪了纽约市的名人,详情可查阅:https://research.neustar.biz/author/atockar/。通过交叉参考(cross-referencing)名人在纽约市搭乘出租车的公开新闻和照片,Tockar 找到了名人搭上出租车的地点和目的地位置,以及他们为此支付了多少钱。
这个案例说明,基于位置的服务(location-based services,即根据 GPS、IP 地址和 WiFi 网络映射获取用户的位置数据并基于其提供服务)可能会是隐私的一个噩梦。但它们也可能具有非常重要的价值,能够为用户提供实时导航、本地天气、基于地理位置的定向搜索结果等等有用的功能。
在 2011 年微软的一项调查《位置的使用和感知》(参阅:http://thelbma.com/research/3/microsoft-location-usage-and-perceptions/)中,我们发现有 94% 的消费者认为基于位置的服务很有价值。但是,这个调查还发现 52% 的用户对于与地理位置有关的数据隐私问题有所担忧。
隐私问题现在是研究界的焦点之一。南洋理工大学教授 Xiaokui Xiao(萧小奎)说:「如今的计算机算力和公开可用的数据让我们可以更加简单地根据数据识别出个人。」
近日,Xiaokui Xiao 教授团队与位于北京微软亚洲研究院的 Xing Xie(谢幸)团队一个合作项目发现了有可能有可以缓解这种隐私问题的方法。这个联合团队提出了一种名叫 PrivTree 的数据操作技术,其可以对地理位置数据进行预处理以保护个人的隐私。之后,这些被隐私保护的数据可以被用在任何前瞻性分析(prospective analysis)之中,甚至可以公开发布,而不会有泄漏用户隐私的风险。
PrivTree 可以通过数学的方式对个人的地理位置信息进行模糊化处理,同时还能在整体上维持该数据集的整体精度。在下面的例子中,数据集中的个人被投射到了一个由他们的地理位置坐标提供的地图上。
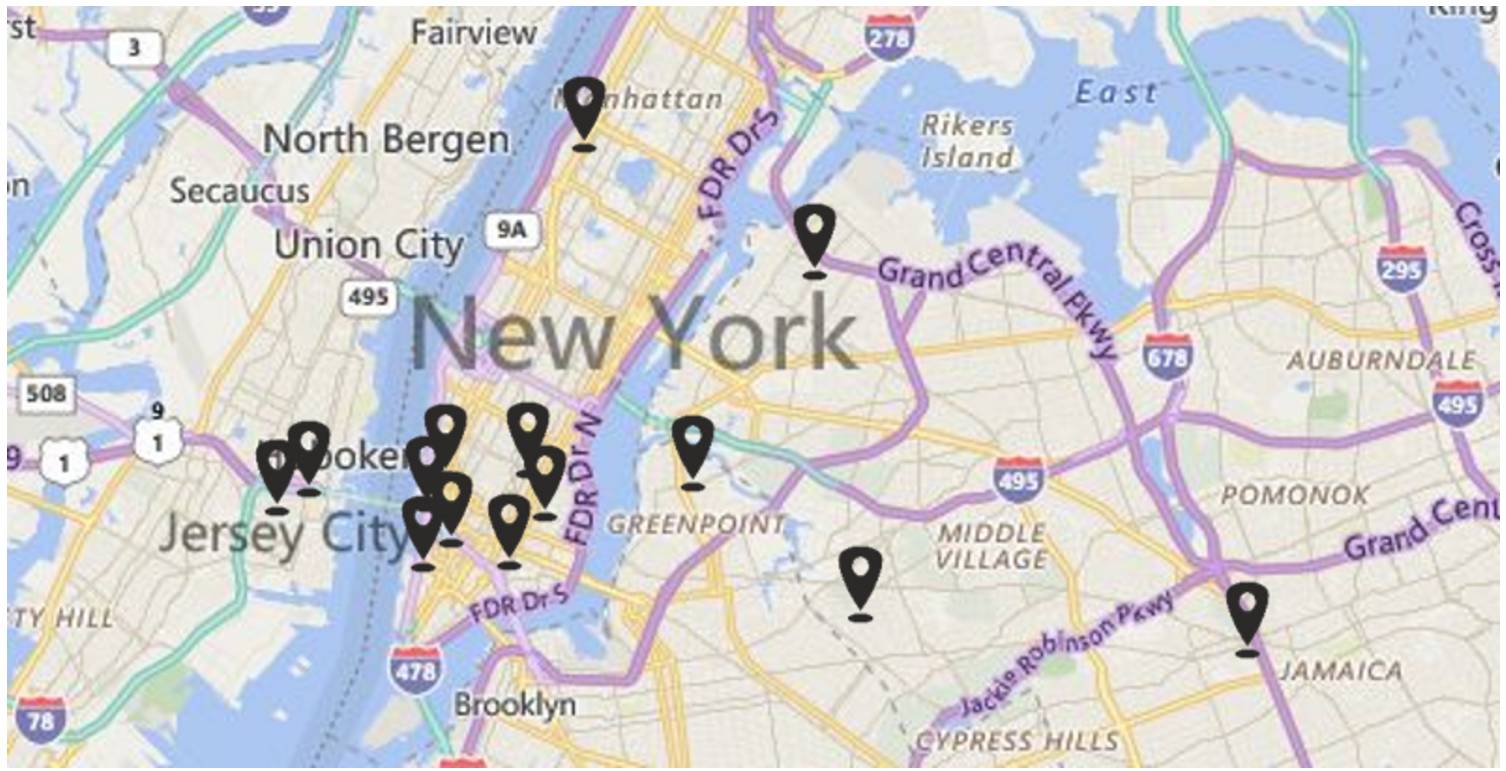
其中每一个标记都代表了该地理位置数据库中的一个个体。
接下来,PrivTree 会经历两个阶段来实现对单个个体的地理位置信息的模糊化处理。
阶段 1:地图分区
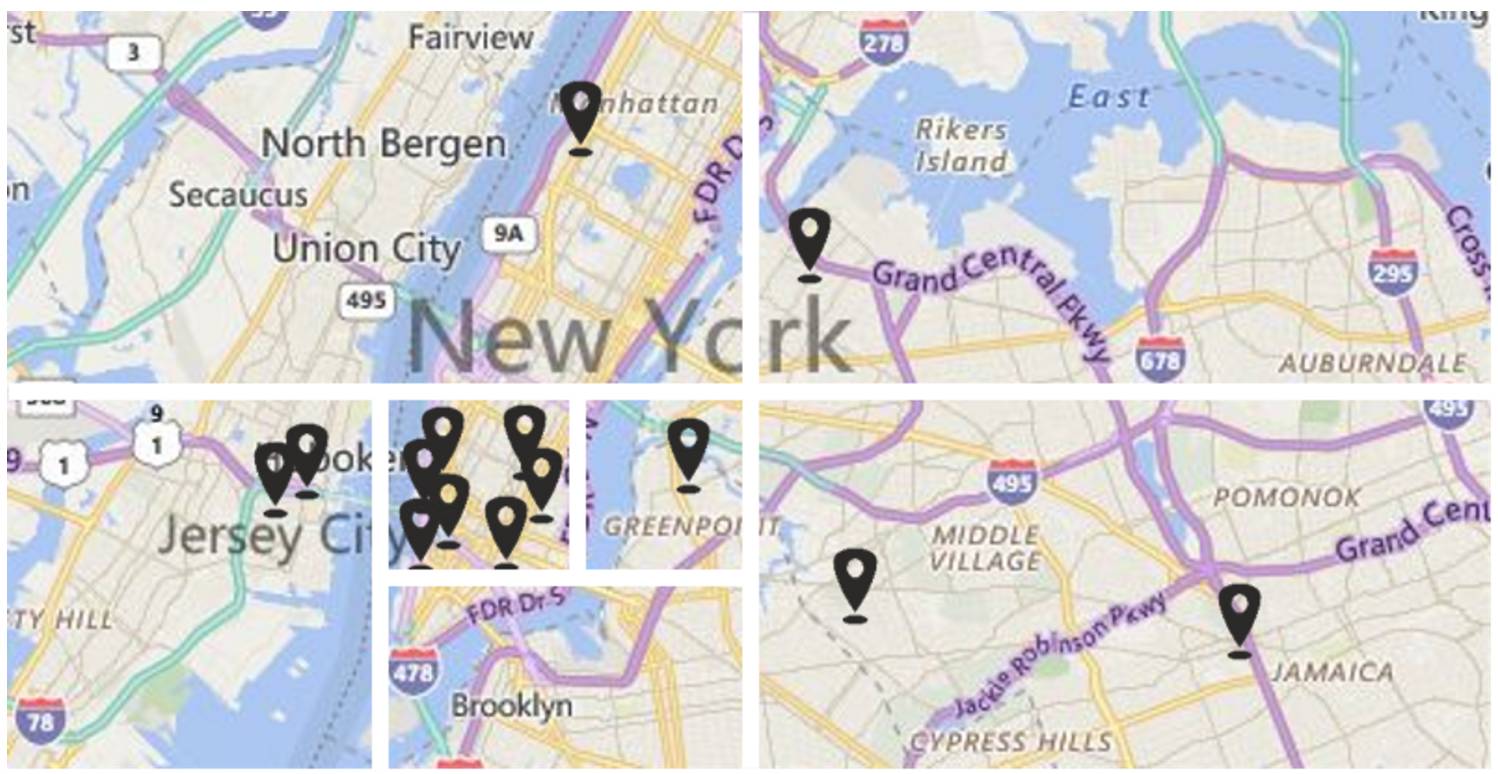
该地图会基于数据点的密度而被分割成一些子区(sub-regions)。
阶段 2:地点扰动
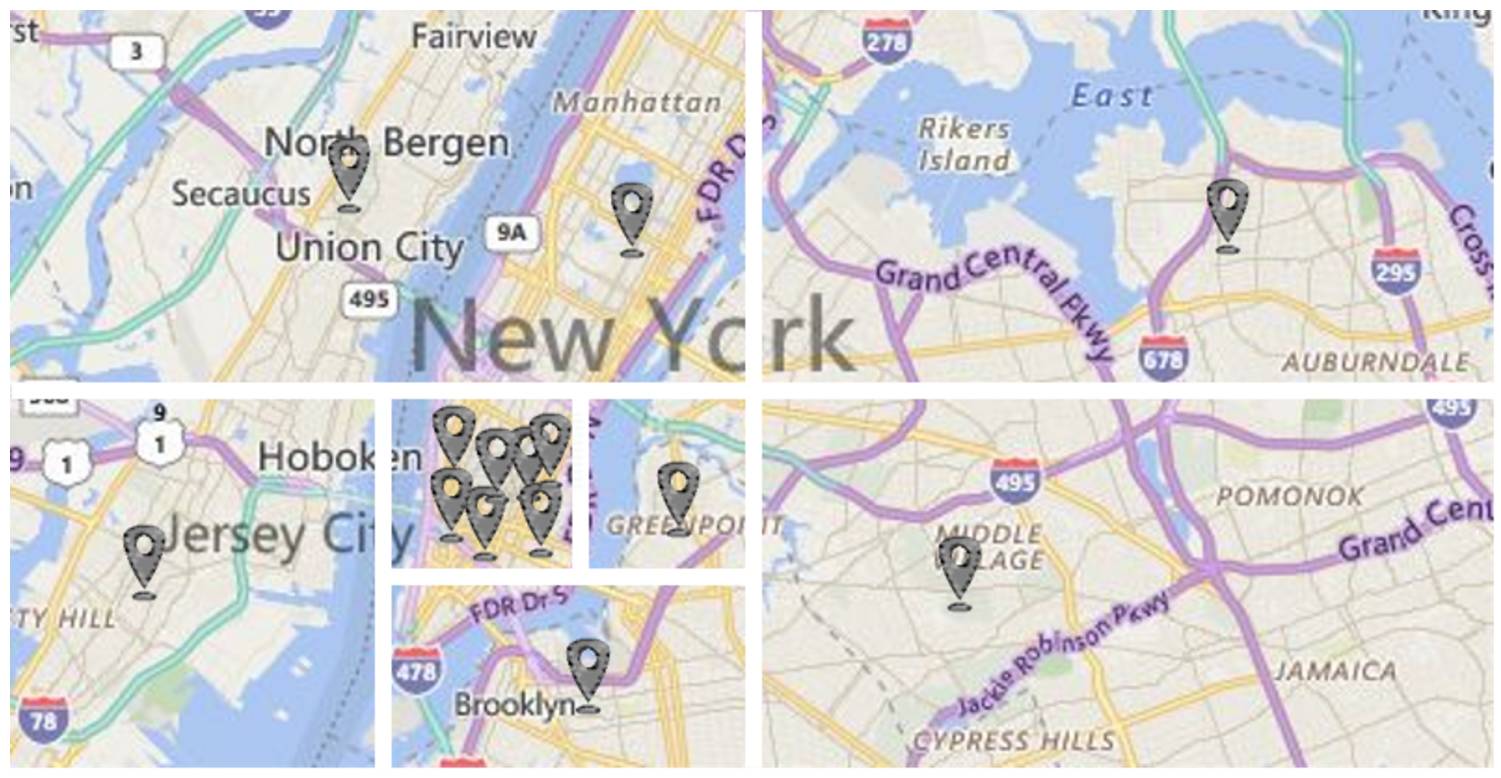
使用统计学分析,个体会按扰动方案(perturbation scheme)被随机移除,在添加或搅乱来保证隐私性的同时保证统计学的准确性。在对每个子区进行位置扰动(location perturbation)后,新的地理位置数据库就可以使用了。
这将产生一组新的数据点,并且它和原数据遵循类似的分布,只不过每个参与者真实的地理位置已经被掩盖了。然后经过隐私保护的数据将作为 PrivTree 的输出。PrivTree 可以扩展支持各种类型的地理位置数据,例如将你日常慢跑的线路上传到健康应用软件。
研究论文《PrivTree:一种用于层级分解的差分隐私算法(PrivTree: A Differentially Private Algorithm for Hierarchical Decompositions)》已经被 ACM SIGMOD 2016(世界顶级数据管理会议)接收。
Xiao 教授谈到了与微软研究员之间的合作:「微软亚洲研究院在管理大型定位数据上的专业性在此项目成功上扮演着重要角色,比如北京的出租车数据。它帮助了我们开发、测试模型。」
Xiao 教授计划进一步将 PrivTree 技术融合到微软的定位技术中,从而提供隐私保护。微软亚洲研究院的高级研究员 Xing Xie 教授也参与到了这一项目中,他说:「数据隐私是云计算时代的重大挑战,特别是包含大量个人隐私内容的用户定位数据。我们希望这一研究能有所贡献,并最终为每个人带来更安全的世界。」
论文:PrivTree: A Differentially Private Algorithm for Hierarchical Decompositions

摘要:给定 Omega 域上定义的一个元组集合 D,我们研究了在 Omega 上构建直方图(histogram)以逼近 D 中的元组分布的差分隐私算法(differentially private algorithms)。对于该问题现有的解决方案大多数都采用了一种分层分解方法(hierarchical decomposition approach),其递归式地将 Omega 分成子区域并计算每个子区域的有噪声元组数,直到所有的噪声数都低于一个特定的阈值。但是,这种方法需要我们
(i) 在 Omega 的分割中的递归深度上施加一个限制 h;
(ii) 设置每个计数中的噪声,使之与 h 成比例。
h 的选择是一个非常严重的难题:h 太小会导致直方图粒度太粗糙,h 太大则会导致当在确定一个子区域是否应该被分割时在元组计数中出现太多的噪声。此外,h 不能直接基于 D 而进行调制;否则,h 自身的选择就会暴露隐私信息和违反差分隐私。为了弥补现有方法的不足,我们提出了一种直方图构建算法 PrivTree,该算法采用了分层分解(hierarchical decomposition),但完全消除了对预定义的 h 的需求。PrivTree 的核心是一种全新的机制,其可以
(i) 在拉普拉斯分布(Laplace distribution)上利用一种新分析;
(ii) 让我们可以在决定应该分割哪个子区域时仅使用常量的噪声,而无需担心分割的递归深度(recursion depth)。我们在建模空间数据上演示了 PrivTree 的应用,结果表明其可以被扩展到能处理序列数据(其中子区域中的决策并不是基于元组数,而是一个更复杂的度量)。我们在许多不同的真实数据集上的实验表明 PrivTree 在数据效用方面显著超越了当前最佳水平。
©本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]









