ESPILON中通过引入域特定闭环策略树(DCP-Tree)来扩展时域决策点。DCP-Tree结点是预定义的语义动作,与一定的时间间隔相关联,树的有向边表示时间上的执行顺序。DCP-Tree从一个正在进行的动作开始,这是在上一个规划周期中最好的策略执行的动作。每当我们进入一个新的规划周期时,通过将当前正在执行的动作设置为根节点来重新构建DCP-Tree,每个策略序列在一个计划周期内最多包含一个行动的变更。在ESPILON中,预测时域为5s,每1s预测一个行为,纵向可能的行为有保持Maintain(M),加速Accelerate(A),减速Decelerate(D),横向可能的行为有车道保持LaneKeeping,向左换道LaneChangeLeft(L),向右换道LaneChangeRight(R),假设当前正在进行的横向行为为车道保持LaneKeeping,则基于当前的横向行为,可生成的DCP树如下:

由此可见,每一时刻,基于当前的横向行为都会生成27种可能的行为序列,之后我们需要剔除不太合理的行为序列,比如上一时刻向左换道,下一时刻规划出向右换道,该行为明显不符合逻辑,可直接剔除。
DCP-Tree生成的C++代码如下图所示:

2.创建多线程
假设当前DCP-Tree的有效行为序列个数为n,则创建n个线程,每个线程针对一条行为序列进行前向仿真。

3.前向仿真过程介绍
(1)判断该行为序列横向行为的变化以及根据下一序列的纵向行为,来为IDM仿真参数赋值。
横向行为的变化过程可分为以下几类:
- 如果下一序列纵向行为为加速,则期望的车速调整为自车车速+10kph
- 如果下一序列纵向行为为减速,则期望的车速调整为自车车速-10kph
首先更新每一个行为序列下自车与周围车辆的轨迹,一个行为序列的最长时间为1s,我们以0.2s为一个仿真步长,时间不够0.2s的放在最前方。

根据仿真步长的个数对自车与周围车辆进行前向仿真。
论文提出,针对不同的语义动作组合,使用不同的横向和纵向控制器。对于车道保持的横向行为,横向控制器遵循纯跟踪控制器(PP),纵向控制器采用IDM控制器。对于变道的横向行为,由于需要考虑当前和相邻车道上的所有车辆,纵向和横向控制是耦合的,我们将横向控制器扩展为反应性纯追踪控制器,纵向控制器扩展为间隙信息速度控制器。
a.如果横向行为为车道保持
(1)首先判断本车道前方是否存在目标车辆。
(2)如果存在,则需要判断当前时刻自车的位置与目标车辆的位置是否会发生碰撞。
(3)之后进行前向仿真。

(4)前向仿真过程的具体实现
i.将自车在笛卡尔坐标系下的信息转换为Frenet坐标系下所需的状态信息。
自车在笛卡尔坐标系下的状态信息主要包括:
自车在Frenet坐标系下的状态信息主要包括:
(1)保持自车与参考线的横向距离不变,纵向距离s上加一个预瞄距离,之后将预瞄距离处自车在Frenet坐标系下的信息转换到笛卡尔坐标下。(2)求预瞄点处车辆位置与自车初始的距离及航向角偏差(3)根据PP算法的基本思想,可计算出所需的前轮转角

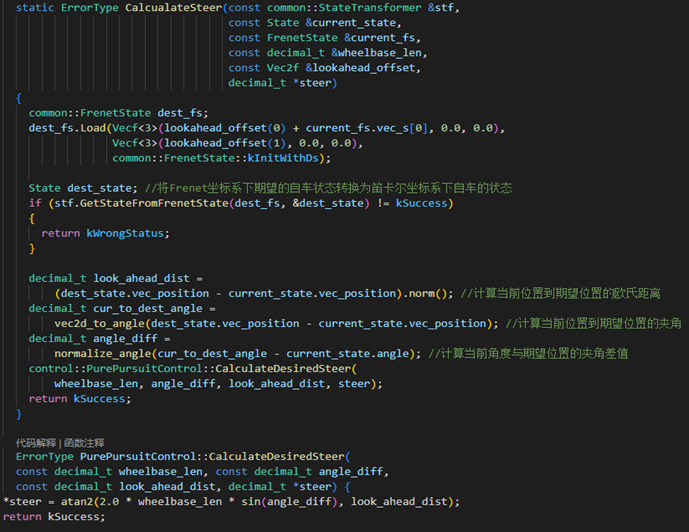
iii.使用IDM模型来计算期望的速度

IDM模型主要通过调节车辆的加速度或减速度来保持与前车的安全距离。根据前车的速度和与前车的距离,驾驶员会做出加速或减速的决定,IDM模型的核心公式如下:
 表示车辆的加速度
表示车辆的加速度 表示自车的期望车速
表示自车的期望车速 表示加速度指数,通常为4,表示速度调整的平滑程度
表示加速度指数,通常为4,表示速度调整的平滑程度 表示自车与前车的速度差
表示自车与前车的速度差 表示期望的跟车距离
表示期望的跟车距离 :表示最小的跟车距离
:表示最小的跟车距离 IDM加速度计算代码如下:

之后更新自车的速度信息。

iv. 根据车辆的运动学模型来计算自车在当前仿真时间内的期望状态


b.如果横向行为为换道
(1)首先检查自车道前方与目标车道前后方是否存在车辆,如果自车道前方存在车辆,检查自车与前方车辆是否会发生碰撞。

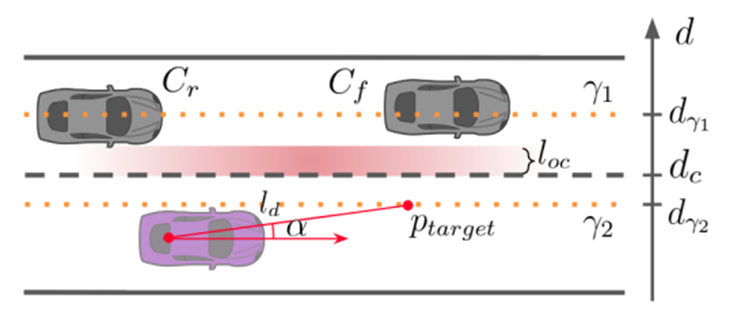
(2)如果存在后方目标,则需要将笛卡尔坐标系下的自车与目标车道的后车信息转换到目标中心线的Frenet坐标系下,之后进行RSS安全校验。

(3)RSS安全校验

4.安全碰撞检测
前向仿真过程会针对当前自车的行为序列生成一条5s的自车轨迹,同时周围车辆也会生成一条5s的预测轨迹,之后我们需要分别检测自车轨迹与周围车辆的轨迹是否会产生碰撞,碰撞检测算法可参考文章Epsilon中碰撞检测算法,代码如下:

5.代价评估
策略的总体奖励是由每个cfb选择的场景的奖励加权和计算得出的,每个场景的奖励函数主要由效率成本,安全成本,导航成本的线性组合组成。
(1)效率成本代价
判断自车车速与驾驶员设定车速之间的关系:
如果自车车速小于驾驶员设定的车速,则自车到期望车速的代价为:0.3*(abs(自车车速-期望车速))。
如果自车车速大于驾驶员设定的车速+1km/h,则自车到期望车速的代价为:0.03*(abs(自车车速-期望车速-1km/h))

判断自车车速与前车车速之间的关系:
如果自车车速与前车车速均小于驾驶员设定的期望车速,且前车与自车的距离小于120m,则前车期望车速的代价为:0.4*0.02*max(自车车速-前车车速,0)*0.1*max(前车车速-期望车速,0);

(2)安全成本代价
对于安全成本,将自车仿真轨迹的所有离散状态与附近车辆的所有轨迹一起进行评估,如果发生碰撞,则相应的场景将直接标记为失败,并以巨大的代价进行惩罚,此外,我们还检查了自车轨迹是否包含rss危险状态,如果状态是rss危险的,在给定当前情况下,我们得到安全速度区间,并通过与安全速度区间的差值来惩罚状态。

(3)导航成本代价
导航成本由用户偏好和决策环境决定,我们对人机界面提供的与用户命令相匹配的策略强制执行奖励,这可以实现驾驶员触发的变道,此外,为了提高决策一致性,我们还对与上一个规划周期做出的决策具有相似意义的策略进行奖励。例如,如果最后一个周期的最优计划是”换道左侧车道”,我们将为实现相同机动的策略分配奖励,代码如下:
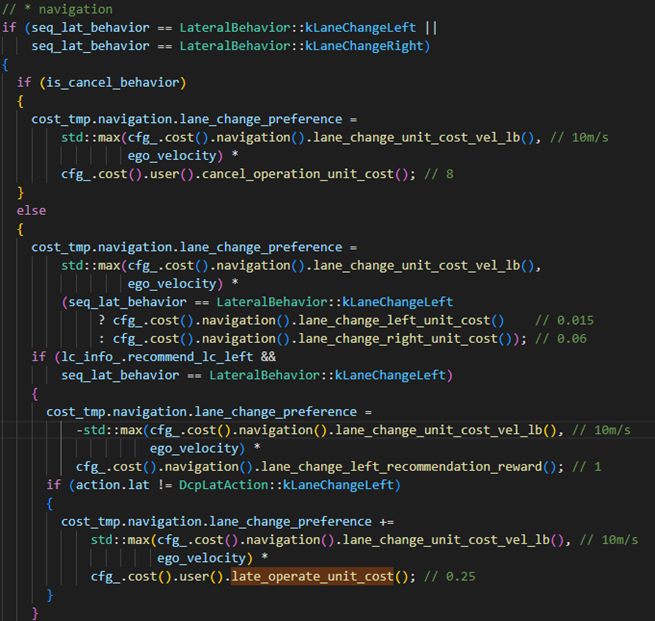
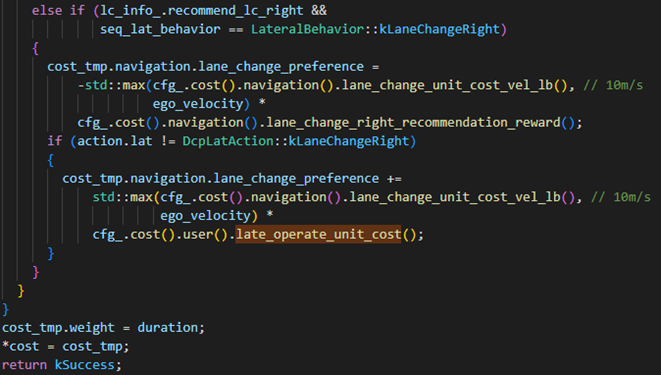
6.选取最优策略
遍历每一条行为序列,从中找出代价最小的行为序列,即为当前时刻的最优行为序列。

如果文章有用的话,可以点击下方链接给作者点点关注,以便及时关注后续更新内容:









