
专利挖掘工作是企业进行专利布局及实施专利管理工作的基础,因此,专利挖掘中有效的挖掘方法,是助力企业专利挖掘工作的一个利器。专利挖掘工作中,如何确定待挖掘的数据源,即从何种对象入手实施专利挖掘,是达成专利挖掘的项目目标的一个关键。通常情况下,企业会考虑主要基于如下几类数据源来规划挖掘工作:
1.基于企业产品来挖掘某一技术领域的专利;
2.基于某一类技术现有的专利来挖掘外围专利;
3.基于单一竞争对手的专利来有针对性的实施专利挖掘;
4.针对一类产品挖掘其在某一技术领域的标准专利。
此处需要注意的是,企业在上述挖掘工作中,都同时面临如何管理好待挖掘的数据源的问题。那么,是否可以找到一种可靠的数据管理模型,来提供高效的数据管理方式?
在此,我们先引入一个在计算机的数据挖掘领域广泛使用的概念“数据存储库”(例如数据仓库)。数据挖掘可以应用于任何类型的数据存储库,一般情况下,数据存储库可以包括如下几种类型:数据仓库、关系数据库、事物数据库、万维网、一般文件和数据流等。本文将重点关注数据仓库。所谓数据仓库,是一种具有收集并组织多维度数据功能的信息存储库,正是基于这种特性,本文考虑将其作为着重讨论的一种应用于专利挖掘工作的数据管理模型。
下面就针对基于企业产品来挖掘某一技术领域的专利挖掘工作,以依靠自主研发技术而闻名的A企业为例,讨论一下在专利挖掘过中如何应用数据仓库这种数据管理模型,使得专利挖掘工作更简单、挖掘结果更准确。
假设A企业是一个成功的跨国公司,我们当前的任务是挖掘该公司每种产品在人工智能领域的专利,A公司产品部门分布全球,涉及的产品线多达几十个,且每个产品线在人工智能领域都有完善的自主开发的技术集。目前,该企业计划布局每个产品在人工智能领域的专利。
分析可知,A公司产品线多,从数据管理的角度来看,每个产品在人工智能领域开发的技术方案相对分散,散布在多个开发部门的开发组中实现,因此,在专利挖掘过程中,A公司应考虑如何高效、无遗漏地挖掘并管理来自不同开发组开发的专利方案。图1展示了一种数据仓库构造和使用的典型系统框架,经过研究,可以考虑将图1所示的数据仓库的结构模型应用在该专利挖掘项目中,以高效、高质地完成专利挖掘目标。
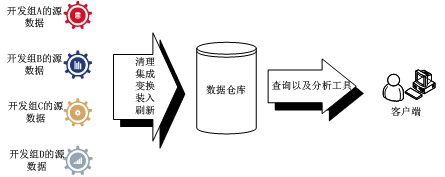
数据仓库的核心是多维数据库结构建模,该模型实现了一种典型的物理结构,即多维数据立方体(multidimensionaldatacube)。数据立方体可以提供数据的多维视图,每个维对应于模式中的一个或一组属性,好处是可以快速查询到汇总数据。
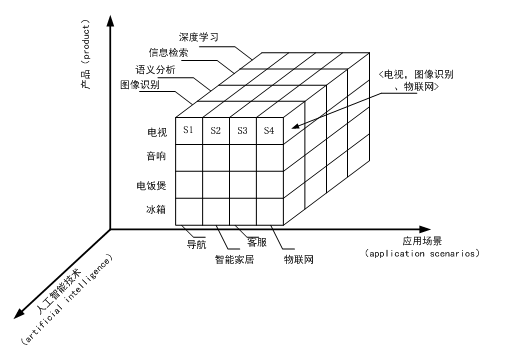
针对A公司的专利挖掘项目,在待挖掘的数据源是各个产品中人工智能领域的技术内容的情况下,我们可以利用上述多维数据立方体构建一种可靠的数据管理模型。如图2所示,在此项目中,多维数据立方体中的三个维度可以定义为:产品(电视、音响、电饭煲、冰箱等)、人工智能技术(图像识别、语义分析、信息检索、深度学习)和产品的应用场景(物联网、智能家居、导航、客服等),即本次项目的挖掘工作可以采用上述模型所限定的三个维度元素进行组合遍历,该多维数据立方体中的每个单元存储挖掘到的专利的技术方案。如图2所示,在物联网场景下,同图像识别相关的家用电视的专利技术方案内容为S4,存放在单元中,而其他立方体单元中可以存放遍历其他几个维度组合上挖掘到的技术方案。
下面就基于上述数据管理模型,简述A公司产品在人工智能领域的专利挖掘过程和挖掘结果。
分析A公司的产品系列,可以综合考虑产品的重要度、成熟度等几个方向综合确定产品的专利挖掘方向和重点。
在产品重要度的分类中,可以考虑将产品按照重点产品和非重点产品划分,分别估算重点产品和非重点产品能产出的专利量。需要说明的是重点产品具有如下一个或多个属性:市场占有率和增长率高、技术含量高、销售利润高等。
在产品成熟度的分类中,可以考虑将产品按照市场应用和技术实现的成熟性进行划分,重点估算成熟度高的产品的专利量。需要说明的是高成熟度的产品包括如下一个或多个属性:涉及前沿的实现完善的成熟技术、用户反馈良好的方向等。
另外,关于新产品,需要根据具体情况部署关键技术的专利。
针对人工智能技术所涉及的如图3所示的多个分支技术,结合已经确定的产品挖掘方向,实现在深度、广度两个维度上分别进行纵向布局和横向布局。
人工智能技术的分支技术的分类如下图3所示:

纵向布局的挖掘结构,主要是实现基于每一类分支技术开展纵向布局,可以围绕某一类或某一个分支技术在延续、纵向这个维度上进行的改进和迭代,形成纵向布局结构。
上述采用延续、纵向的布局方式,主要基于技术不断更新发展的特性来确定。技术的不断发展,必然产生迭代的技术改进点,因此,纵向布局结构主要跟随技术的更迭而产生。
横向布局的挖掘结构,主要是实现基于不同类型技术的关联因素开展的横向布局,可以围绕不同技术之间的关联关系,形成横向布局结构。
采用不同技术之间的关系支持的布局方式,主要是因为各类技术都处于相关技术群中,任何一项技术都不是孤立地发展。随着相关技术群以及技术群与技术群之间的关联日益密切,关联技术之间的创新点必然不断产生,因此,横向结构布局主要是基于相关技术之间的关系因素为支撑点。
基于本文所讨论的专利挖掘方法,将最后一个挖掘维度——应用场景与上述两个维度的挖掘方向进行结合,最终实现多维数据立方体在专利挖掘项目中的有效应用。
基于本文讨论的多类产品和人工智能技术,当前涉及到的应用场景的类型大致如下图4所示:
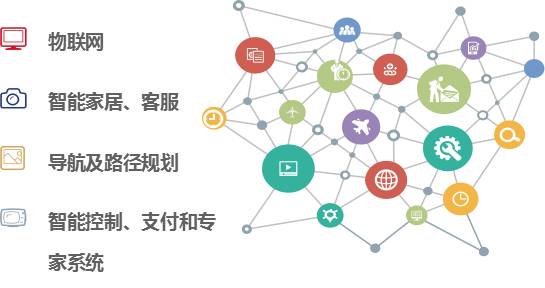
对于图4中罗列的应用场景,可以结合1.2中完成的技术布局结构,实现在网状结构上进行网状式布局。技术总是从已知领域渗透至未知领域,并且随着产品种类的增长,技术及技术之间更迭也是迭代发展,这也使得技术在不同领域应用时会产生意想不到的新用途,从而可以蔓延出覆盖型的网状布局结构。这种网状布局结构,可以理解为产品的实现技术应用在各个应用场景下所形成的枝蔓结构。
由此可知,基于1.1、1.2和1.3,我们可以完成A公司产品中关于人工智能专利的自主布局和挖掘工作;进一步的,在产品后续的更新迭代过程中,A公司仍旧可以采用上述挖掘方式,作为继续专利进行申请。
此处需要说明的是,在A企业部署外围专利、规避性专利和标准专利的过程中,同样可以考虑使用本文涉及到的数据管理模型,来开展和规划专利挖掘工作。
专利挖掘的过程是一个反复循环的过程,每一个挖掘步骤如果没有达到预期目标,都可以回到前面的步骤,重新调整并执行专利挖掘。本文提供的关于数据仓库的数据管理模型,为整个挖掘过程提供了一个可回溯的技术支持,即这种数据管理模型易查询、易追溯、易替换的优点能够在专利挖掘的过程中,帮助企业回溯、调整之前的挖掘步骤,真正做到为企业的专利挖掘项目提供有效、高效的工具。
[1]马天旗.专利挖掘.北京:知识产权出版社,2016.
[2]马天旗.专利布局.北京:知识产权出版社,2016.
[3]JiaweiHan,MlcelineKamber,JianPei.DataMining.北京:机械工业出版社,2012.
[4]JiaweiHan,MlcelineKamber,JianPei著.范明,孟小峰译.数据挖掘:概念与技术.北京:机械工业出版社,2007.
作者:谢湘宁 北京康信知识产权代理有限责任公司
来源:《中国知识产权》杂志总第130期
《知产观察家》
一档全新的知识产权行业对话式新闻评论节目
第八期:
开发APP你真的想好名字了吗?


↓
↓
↓
↓
↓
点下方“
阅读原文
”访问《中国知识产权》杂志网站




