文章介绍了易生信培训团队扩增子分析、宏基因组、单物种转录组和单菌基因组的线上/线下培训课程。包括课程内容、培训目标、教学方式等,并附有报名链接。
文章介绍了易生信培训团队即将开展的包括扩增子分析、宏基因组、单物种转录组和单菌基因组等课程的详细信息,包括课程内容和培训目标。
课程覆盖临床基因组数据分析平台搭建、基因组与外显子组学研究概述、测序与数据预处理、经典文章思路与图表解读、全基因组比对与短变异检测、数据库详解、变异注释和过滤、有害性预测、通路和表型富集分析等内容。
课程注重实战实操,结合发表的高水平文章,讲解常用分析图的原理和使用范围,提供丰富的软件和数据库的使用经验。
报名链接为http://www.ehbio.com/Training/,学员可以通过该链接进行报名。
福利公告:为了响应学员的学习需求,经过易生信培训团队的讨论筹备,现决定安排扩增子16S分析、宏基因组、单物种转录组、单菌基因组的线上/线下同时开课。报名参加线上直播课的老师可在1年内选择参加同课程的一次线下课 。期待和大家的线上线下会晤。
目前可以通报的信息:
单物种转录组线上/线下开课时间:
2024/12/27-29, 2025/03/21-23
临床基因组线上/线下开课时间:
2025/2/21-23
单菌基因组线上/线下开课时间:
2025/1/10-12
宏基因组线上/线下开课时间:
2025年5月9-11
扩增子线上/线下开课时间:
2025/4/11-13
报名链接:http://www.ehbio.com/Training/
近几年测序成本急速降低,基因组测序逐渐成为临床上的常规检测。临床基因组测序一般包括全外显子测序 (WES)或全基因组测序 (WGS),极大地加深了我们对于疾病规律的认识,是检测单基因遗传病或罕见病的利器,同时也越来越多地用于常见病的遗传风险评估。
目前很多临床科室积累了一些病人的WGS/WES数据,但由于缺乏大数据分析平台或专业的生信人才而被长期搁置。一些外包或第三方的分析由于分析手段有限,缺乏对疾病背景信息的深入了解和沟通,经常报告不出来可疑的或明确的致病位点,也难以做出高水平文章所需的图和表格,导致既无法报告给患者,也难以用于科学研究和成果发表。相关政策和法规也不鼓励样本外送及外包分析,此外人类遗传资源的采集、保藏、利用和对外合作也应当遵守《人类遗传资源管理条例》。因此临床科室自己独立分析是满足相关临床需求,进行高水平研究,以及保护遗传样本资源的根本办法。
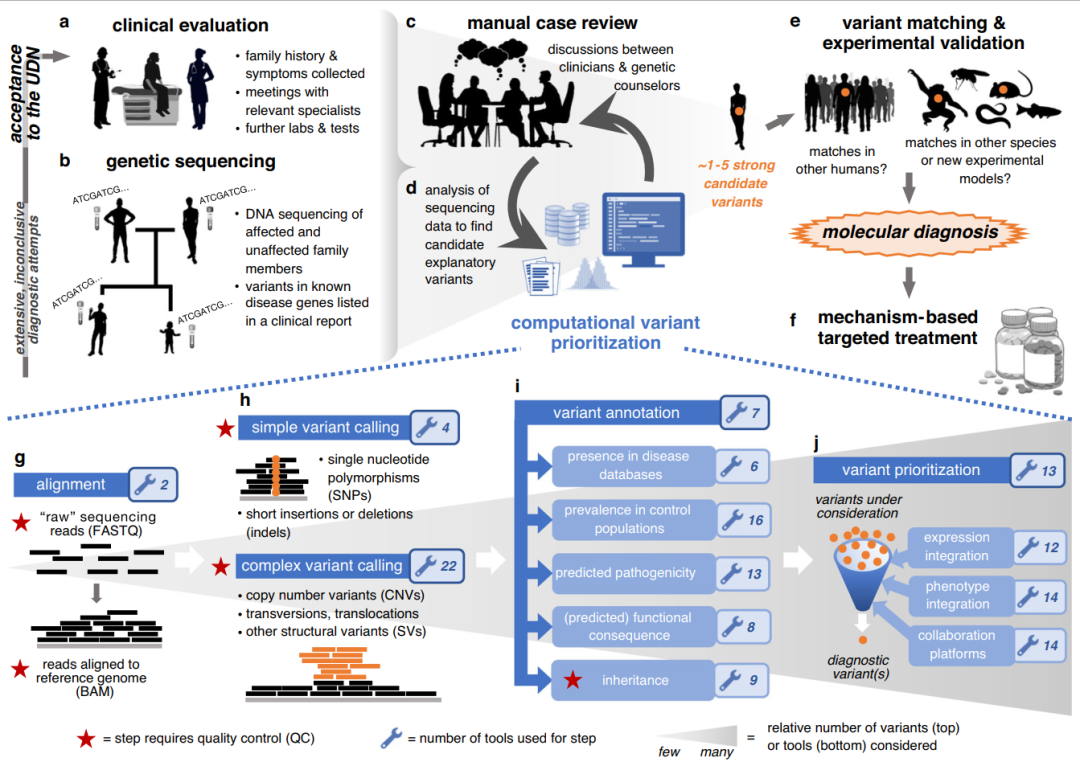
图1. 利用临床基因组测序发现致病遗传变异的工作流程
在这样的大背景下,易生信培训团队推出《临床基因组学数据分析实战》专题培训,为临床医生和相关领域研究人员提供一条走进临床基因组生信大门的捷径,为同行提供学习和交流的平台,切实助力大家理解分析原理,完成实战分析。
本课程帮助您真正实现临床基因组学数据分析,并根据自己课题的背景优化分析方案。在本课程学习过程中,除了学习基于Linux和R语言的标准分析,还包含运用丰富的公共数据库、疾病数据库对突变位点进行注释和可视化,也包含了大量下游分析工具和方法,如:一代测序拼接和测序峰图绘制,多序列比对,突变所处的蛋白结构域预测,突变蛋白翻译后修饰的变化,突变对蛋白三维结构的影响预测(表面电荷、化学键、空间位阻、亲疏水性等),达到临床应用与学术研究双受益。
在课程时间的设置上,独创四段式教学(3天集中授课+自行练习2周+再集中讲解答疑+上课视频回看反复练习),“教—练—答—用”四个环节统一协调,循序渐进,使学员获得独立分析临床基因组数据的能力。
在分析平台上,提前帮助您在自己的笔记本电脑或工作站安装Windows+Linux的双系统;与此同时提供1个月的免费Linux云服务器的使用权限 (配备了全固态硬盘);各个平台上均配备大量,完善的公共数据库资源。确保程序写作、数据传输和实战分析的顺利进行。
课程简介
请详细阅读课程简介,如果以下内容您全精通,不必参加此培训。
为满足广大读者进一步学习的需求,易生信课程开发团队 (现运营《生信宝典》和《聊生信》两个公众号)经长期规划,筹备和专家研讨,现组织和开展临床基因组学专题培训课程,以便进一步普及和交流临床基因组学分析技术,手把手带您快速入门,节约宝贵的时间,助力科研成果早日产出。
本课程一共3天,每天6节课,共18节课,全部课程均理论与实战结合 (只要课上讲的内容,都是要带你亲自实现的分析)。
课程覆盖:
临床基因组数据分析平台搭建 (操作系统与软件);
基因组与外显子组学研究概述;
测序与数据预处理;
经典文章思路与图表解读;
全基因组比对与短变异 (SNV & InDel)检测;
数据库详解 (OMIM, ClinVar, 1000G, ExAC/gnomAD, MalaCards/GeneCards, SWISS-MODEL/AlphaFold);
变异注释和过滤, 变异有害性预测 (SIFT, PolyPhen, CADD, RVIS);
通路和表型富集分析 (GO, KEGG, Reactome, DisGeNET, Human Phenotype Ontology, OMIM Disease等);
蛋白-蛋白互作网络分析;
Sanger测序拼接及峰图绘制, 多序列比对与保守性分析;
突变对蛋白修饰 (磷酸化和糖基化)的影响预测, 突变所在蛋白结构域或保守区预测;
突变对蛋白三维结构影响 (表面电荷, 化学键, 空间位阻, 亲疏水性和残基位置等);
CNV分析,家系分析及ACMG变异评级。
注意:
本课程不包括SV等结构变异分析。
课程大纲
每节课1小时一个主题,理论结合实战,学懂原理,实战实操,全是多年经验和代码的无私分享。下面是课程安排,如:11代表第一天第一节课,23代表第二天第三节课;01、02和03表示课前准备工作 (提前观看相关软件安装等视频和提前进行软件安装直播)。
| 编号 | 主题 | 简介 |
|---|
| 01 | 操作系统及软件 | Bioconda, Git, R, Rstudio, R包等, Ubuntu子系统 |
| 02 | Linux和R基础 | Linux系列教程, Linux常用命令, 生信程序基础课节选 |
| 03 | Linux软件安装 | Conda安装与配置, 相关软件安装 |
| 11 | 基因组与外显子组学研究概述 | 基本概念, 发展史, 常用技术适用范围 |
| 12 | 测序与数据预处理 | NGS, MultiQC, 移除接头和低质量碱基, Trim Galore |
| 13 | 经典文章思路与图表解读 (一) | 文献解读, 多篇文章研究思路, 图表在文章中的意义和解读 |
| 14 | 全基因组比对与短变异 (SNV & InDel)检测 | BWA, GATK, Samtools和Vcftools等 |
| 15 | 全基因组比对与短变异 (SNV & InDel)检测 | BWA, GATK, Samtools和Vcftools等 |
| 16 | 全基因组比对与短变异 (SNV & InDel)检测 | BWA, GATK, Samtools和Vcftools等 |
| 21 | 相关数据库详解 | OMIM, ClinVar, gnomAD, 1000G和AlphaFold等 |
| 22 | 变异注释, 过滤, 有害性及致病性预测 | SnpEff变异注释, gnomAD和1000G人群频率过滤, SIFT, Polyphen, CADD和RVIS变异有害性预测, ClinVar/ClinGen, OMIM和Orphanet变异致病性。 |
| 23 | 变异统计与绘图 | GO/KEGG/Reactome通路富集, OMIM Disease, DisGeNET, ClinVar和Human Phenotype Ontology疾病或表型富集, 蛋白组织特异性表达富集, PPI网络, 变异热图, Circles图绘制 |
| 24 | 变异统计与绘图 | GO/KEGG/Reactome通路富集, OMIM Disease, DisGeNET, ClinVar和Human Phenotype Ontology疾病或表型富集, 蛋白组织特异性表达富集, PPI网络, 变异热图, Circles图绘制 |
| 25 | 变异统计与绘图 | GO/KEGG/Reactome通路富集, OMIM Disease, DisGeNET, ClinVar和Human Phenotype Ontology疾病或表型富集, 蛋白组织特异性表达富集, PPI网络, 变异热图, Circles图绘制 |
| 26 | 家系分析 | 新发 (De novo)突变, 隐性复合杂合变异分析 |
| 31 | 蛋白质生物学概述 | 生物分子的强, 弱相互作用及种类, 蛋白结构和功能基础, 酶的功能原理, 结构域, 磷酸化等翻译后修饰原理, 蛋白互作的意义 |
| 32 | 序列拼接、比对和蛋白质结构预测 | Sanger序列拼接, 测序峰图, 多序列比对, 突变对蛋白修饰(磷酸化和糖基化)的影响预测, 结构域预测, 突变对蛋白三维结构影响, 突变对蛋白表面电荷, 化学键, 空间位阻, 亲疏水性的影响 |
| 33 | 串讲, 答疑, 第二/三篇文献解读 | 临床基因组分析套路(1), 临床基因组分析套路(2), 现场回答每人一问 |
| 34 | 分析环境配置, 导入自己数据分析的使用 | 演示如何分析自己的数据 (Linux软件安装 + Ubuntu子系统) |
| 41 | 答疑-线上 | 答疑, 考试内容串讲 |
教程内容简介如下:
一、临床基因组数据分析流程
包含从下机数据质控,公共数据准备,基因组比对,到变异检测,过滤和有害性预测等全流程。
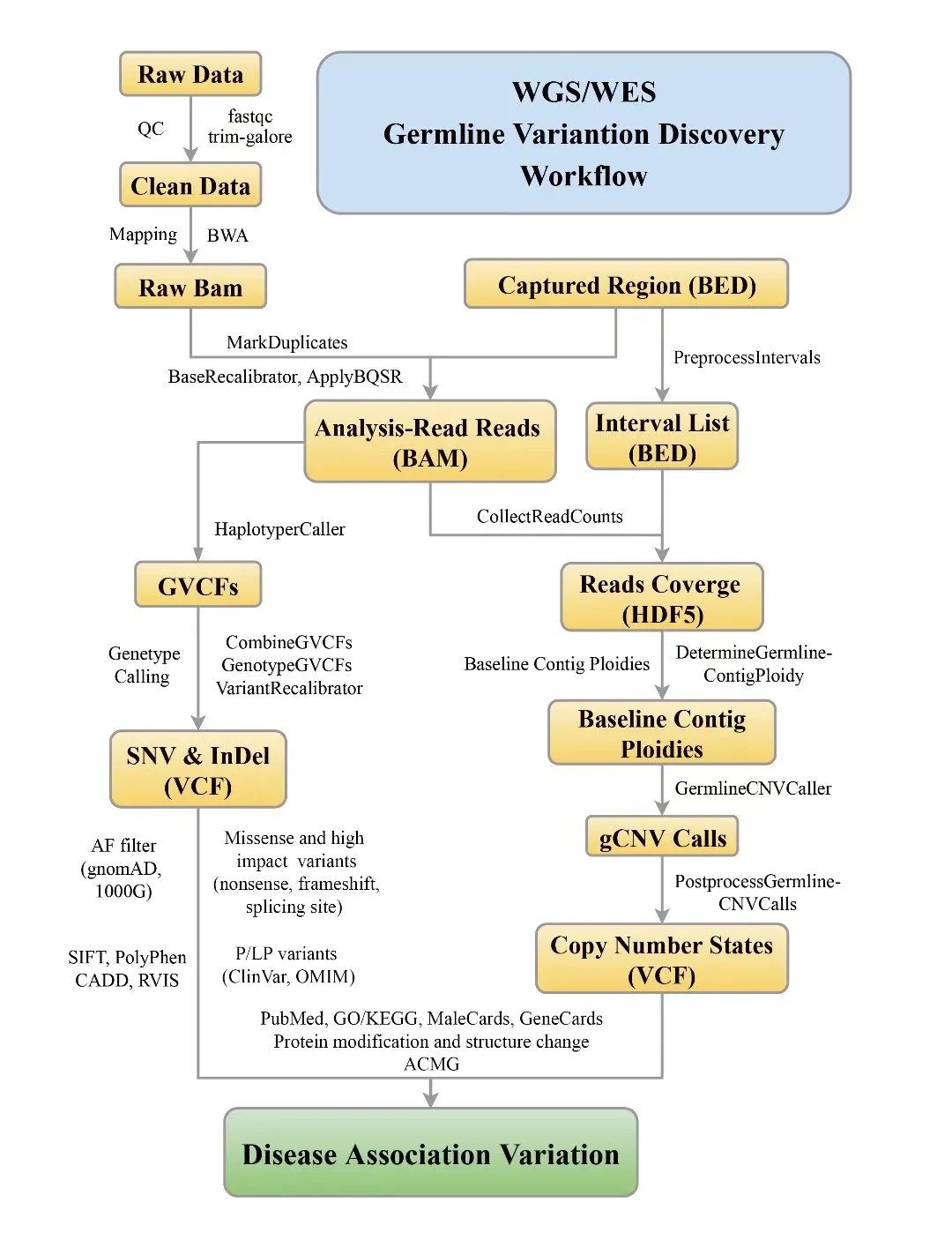
图2. 临床基因组学测序数据分析流程
对原始测序数据去除低质量碱基和接头序列,确保准确地反映样本身的序列信息。
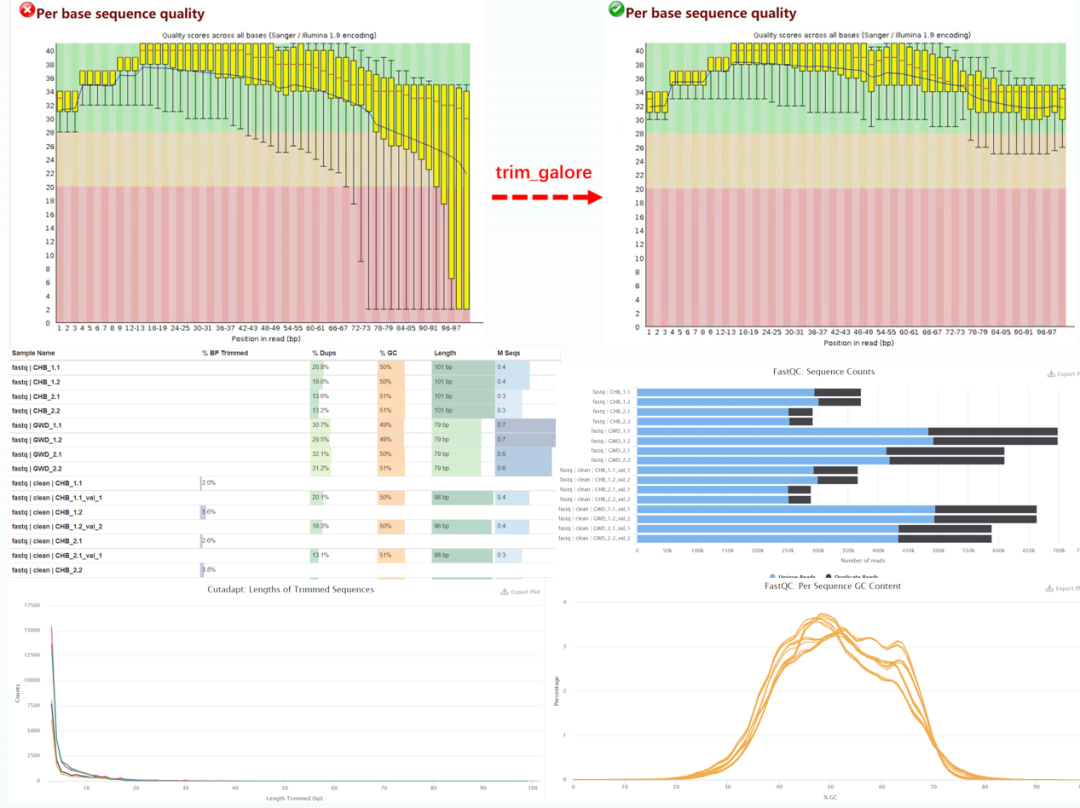
图3. 测序数据质量控制
流程中涉及大量专业软件,方法和分析工具,尤其是大量下游分析工具,全面解析候选变异的致病机制,分析结果满足临床和科研两个方面的需求。

图4. 软件,方法和工具
二、完备的数据库资源
课程中配套了最新权威疾病数据库,如OMIM,ClinVar和Orphanet;广泛覆盖的人群变异频率数据库,如gnomAD和千人基因组计划(1000G)数据库;蛋白质三维结构数据库,如SWISS-MODEL和AlphaFold等。

图5. 调用丰富的数据库
三、生信图表绘制
使用R语言等统计与可视化工具,绘制常用生信相关图形,包括:热图 (变异水平),maftools图 (基因水平),基因的结构、变异位置及结构域标记 (棒棒糖图),基因组Circos图,IGV基因组浏览器,PPI网络图,基因功能的富集结果图。
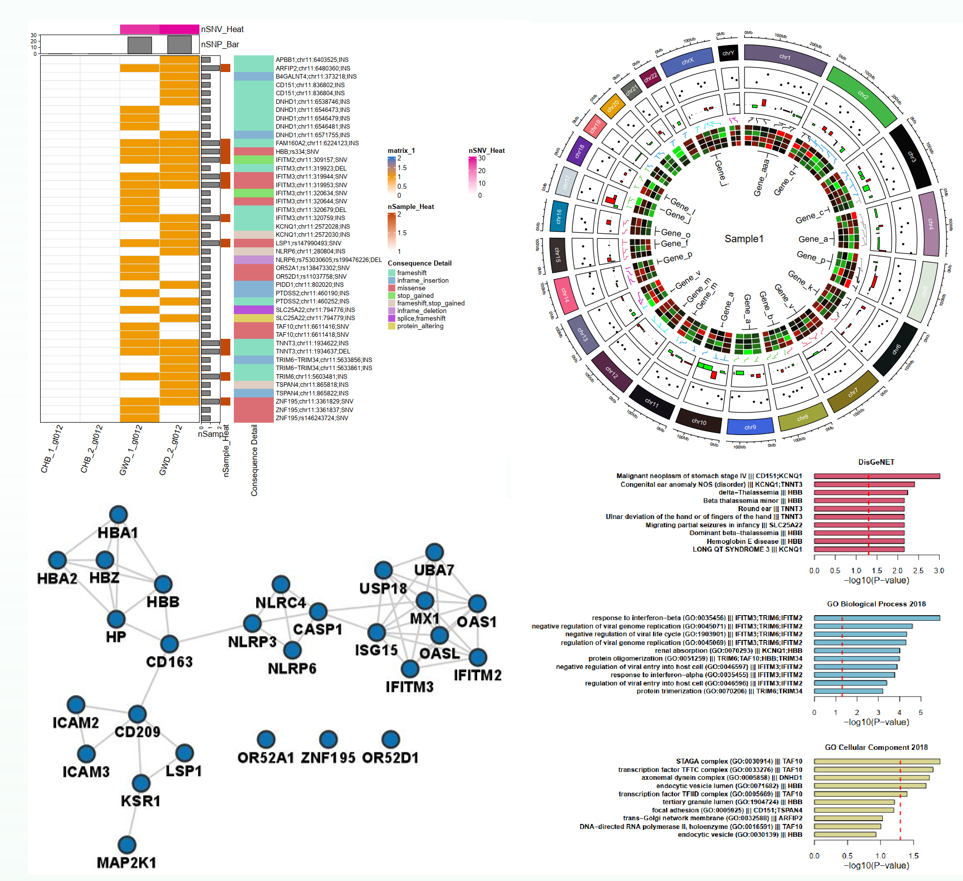
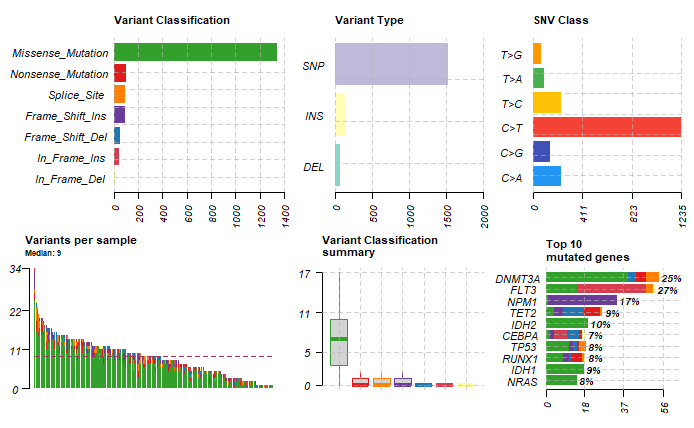
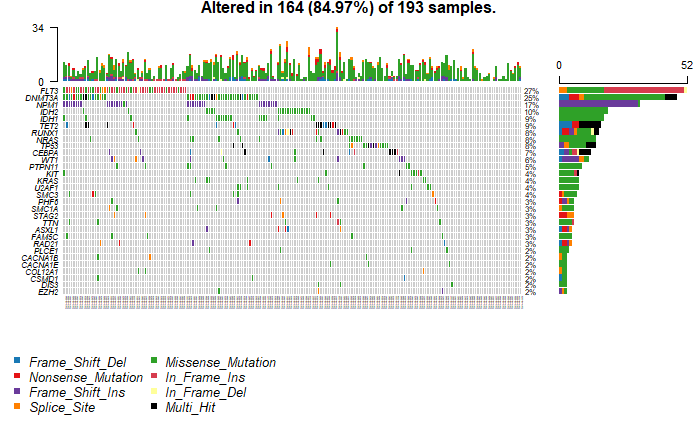
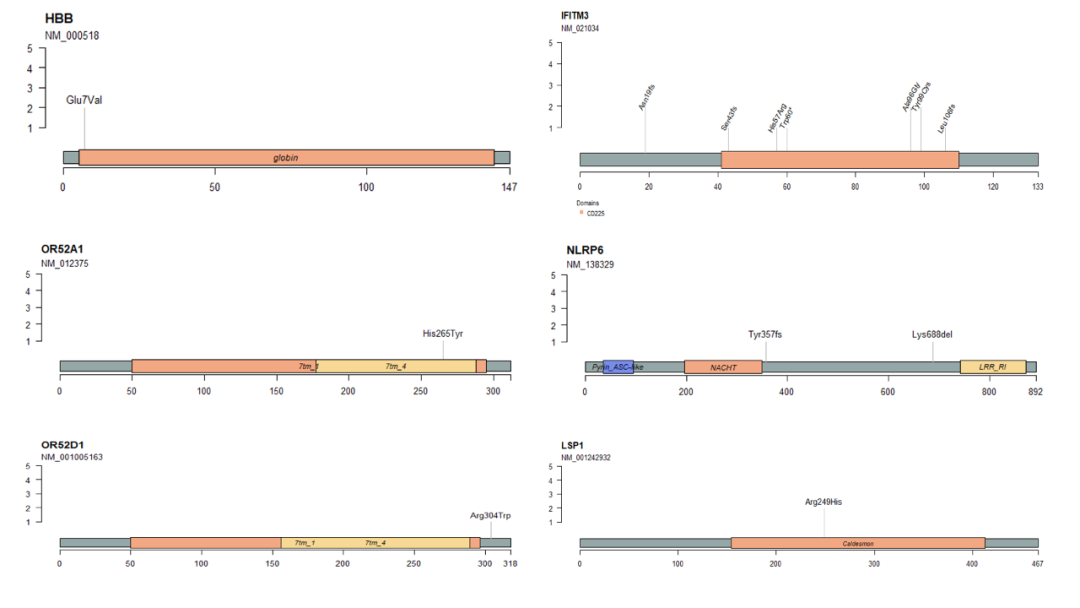
图6. 常用生信图形的绘制。
四、更多下游分析与可视化
在培训时,我们将结合发表的高水平文章,进一步讲解常用分析图的原理和使用范围,让你不仅读懂图,更知道如何应用于自己的研究,并亲自轻松完成绘图。下面的图形也都会手把手教会你如何绘制:
1. Sanger测序拼接和绘图,多序列比对,突变所在的蛋白结构域和翻译后修饰位点预测
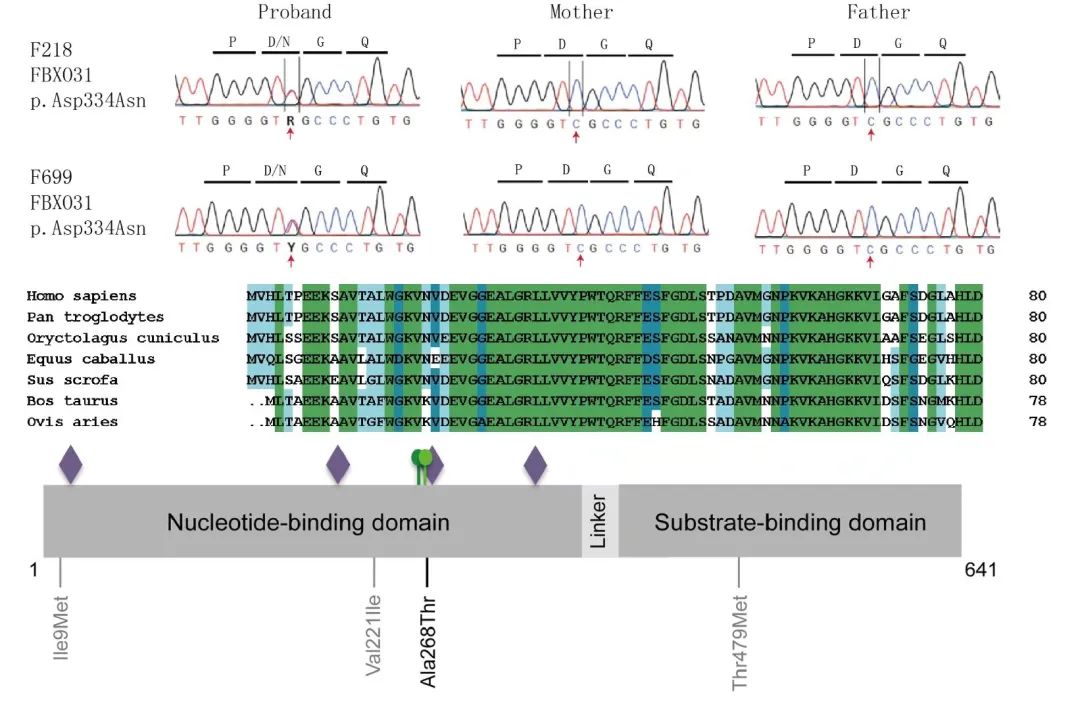
图7. 序列拼接、比对、蛋白结构域和修饰预测。
2. 基于蛋白三维结构的分析,研究突变对表面电荷、化学键、空间位阻、亲疏水性和残基位置等的影响,进而预测其对蛋白具体功能的影响,解释疾病发生的分子机制!
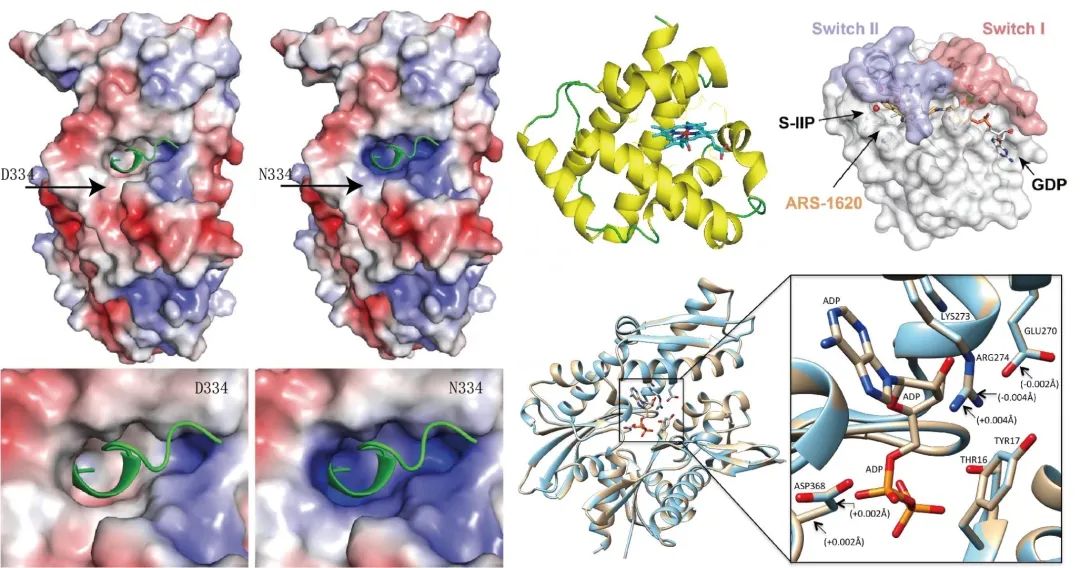
图8. 分析变异对蛋白结构的影响。
学习完本课程,你能得到什么?
1. 深彻理解临床测序数据的基本思想
2. 临床基因组学分析和可视化的全套流程
3. 应用于各个领域的分析经验,代码和发表级别的结果可视化
4. 丰富的软件和数据库的使用经验
几十款本领域软件的安装,使用教程
常用公共数据库,疾病数据库的理解和使用
5. 在临床应用的同时,也能享受科研的乐趣,做高大上且深刻的疾病机制解析
6. 高要求的结果可视化
报名链接:http://www.ehbio.com/Training/










