新媒体管家


作者 CDA 数据分析师
关联规则挖掘是数据挖掘中成果颇丰而且比较活跃的研究分支。采用关联模型比较典型的案例是“尿布与啤酒”的故事。在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,超市也因此发现了一个规律,在购买婴儿尿布的年轻父亲们中,有30%~40%的人同时要买一些啤酒。超市随后调整了货架的摆放,把尿布和啤酒放在一起,明显增加了销售额。同样的,我们还可以根据关联规则在商品销售方面做各种促销活动。
除此以外,关联规则挖掘还经常被用于:
· 电信套餐的捆绑销售
· 歌曲推荐或者视频的“猜你喜欢”
· 电商的产品推荐
· 财务的归因分析
最近参加了一些学生的创新创业活动,令人印象深刻的是,他们的脑海中总能迸发出无穷的创意。受此启发,我想着尽快把这部分的内容整理出来,希望能够对大家在商业模式的选择上有所帮助。
先了解几个相关的概念:
· 关联(association):两个或多个变量的取值之间存在某种规律性。
· 关联规则(association rule):指在同一个事件中出现的不同项的相关性。
· 关联分析(association analysis):用于发现隐藏在大型数据集中的令人感兴趣的联系。
· 项和事物:令I={i1, i2, ……,id}是购物篮数据中所有项的集合,而T={t1, t2, ……,tn}是所有事务的集合。
· 项集(itemset):包含0个或者多个项的集合被称为项集。
· 支持度计数,即包含特定项集的事务个数。
关联规则是形如A=>B的蕴含表达式,其中A和B是不相交的项集。下面我们来看三个重要的公式:
· 支持度(support):support(A=>B)=P(A or B)
· 置信度(confidence) confidence(A=>B)=P(B|A)
· 提升度(lift) lift(A=>B)=P(B|A)/P(B)
这里我们不难看出,支持度指的是两个事件同时发生的概率(实践中用频率表示),这个值如果太小,只能认为是偶尔事件,而不能认为是规则,置信度是指条件概率,表示A发生条件下B发生的强度,提升度是一个比值,用来衡量A条件的重要性。
看一个小例子:
下面是一个购物篮清单
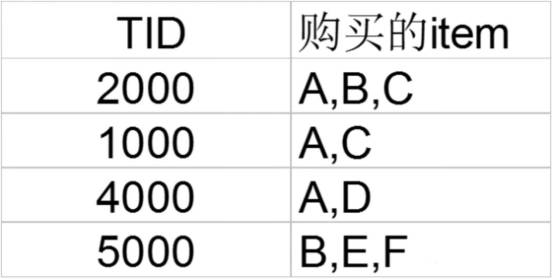
这里TID是交易编号,不参与计算,右边ABCDEF分别表示不同的商品,下面两个规则的支持度和置信度分别为:
· A => C (50%, 66.6%)
· C =>A (50%, 100%)
关联规则挖掘的基本过程
给定事务的集合T,关联规则发现是指找出支持度大于等于minsup,并且置信度大于等于minconf的所有规则,其中minsup和minconf是对应的支持度和置信度的阈值。由于需要计算每一个可能规则的支持度和置信度,这种方法过高的代价让人望而却步。因此,我们将目标做相应转化为找出所有频繁项集,即发现满足最小支持度阈值的所有项集,这些项集称作频繁项集(frequent itemset),并进一步由频繁项集中提取所有高置信度的规则(受篇幅影响,这部分暂时省略),这些规则称作强规则(strong rule)。下面我们通过算例来实现上面的想法。
让“机器”猜猜谁是你喜欢的歌手
这是我在概率论课上的一个案例,目的是帮助学生理解条件概率,于是让学生每人填写3个以上的华语歌手(呵呵,要是填英语歌手的话,“事物”太多,而学生有限,这样结果会不好)。于是,同学们填出来的结果是这样的:
| 学号 | 喜欢的歌手 |
| 13*34 | 梁静茹 |
| 13*45 | 邓紫棋 |
| …… | …… |
为了计算歌手之间的相关规则,我们可以调用R语言的arules包来进行计算,代码如下:
##### code start #####
# 加载包
library(arules)#加载程序包arules,当然如果你前面没有下载过这个包,就要先install.packages(arules)
setwd("G:\\公文包\\R语言 关联分析")#这里设置你自己的工作路径
# 加载数据
singer
# 将数据转换为arules关联规则方法apriori 可以处理的数据形式.交易数据
data 歌手, singer$学号), "transactions")
# 查看一下数据
attributes(data)
# 使用apriori函数生成关联规则
rules
####说明
#apriori(data, parameter = NULL, appearance = NULL, control = NULL)
#data:数据
#parameter:设置参数,默认情况下parameter=list(supp=0.1,conf=0.8,maxlen=10,minlen=1,target=”rules”)
#supp:支持度(support)
#conf:置信度(confidence)
#maxlen,minlen:每个项集所含项数的最大最小值
#target:“rules”或“frequent itemsets”(输出关联规则/频繁项集)
#apperence:对先决条件X(lhs),关联结果Y(rhs)中具体包含哪些项进行限制,如:设置lhs=beer,将仅输出lhs含有beer这一项的关联规则。默认情况下,所有项都将无限制出现。
#control:控制函数性能,如可以设定对项集进行升序sort=1或降序sort=-1排序,是否向使用者报告进程(verbose=F/T)
rules.sorted "lift")
#检查排序后的变量。
inspect(rules.sorted)
# 使用inspect函数提取规则
inspect(rules)
# find redundant rules
#生成一个关联规则的子集矩阵,
subset.matrix
#将矩阵对角线以下的元素置为空
subset.matrix[lower.tri(subset.matrix, diag=T)]
#将子集矩阵中每列元素和大于等于1的列找出来
redundant = 1which(redundant)
#从规则矩阵中去掉这些列
rules.pruned
#检查最终生成的结果集
inspect(rules.pruned)
上述代码输出如下
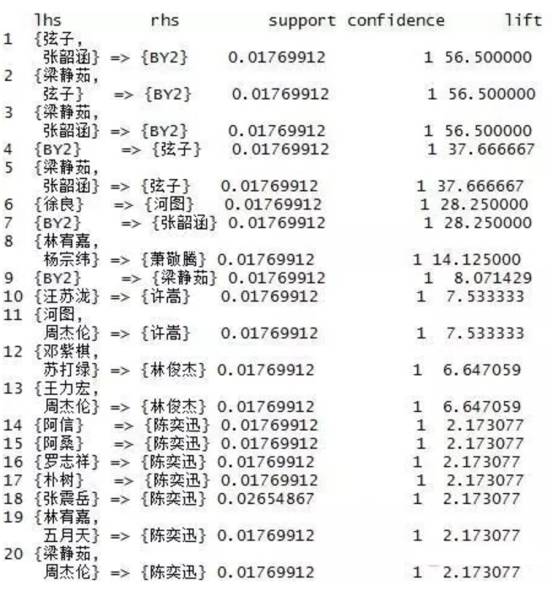
结果说明
以No1为例,弦子、张韶涵和BY2 同时被喜欢的概率为1.7%(学生人数有限的原因),喜欢弦子, 张韶涵的同学会喜欢BY2的概率为100%,该规则的提升度为56.5。因此,如果有人在音乐平台上听了弦子和张韶涵的歌,那就放心的把BY2推荐给他吧!!

值得注意的是,陈奕迅真的是万人迷,居然有9位歌手能够指向他,好吧故事结束了,你也动手试试吧!!

如果你想系统学习R语言进行机器学习,同时想在商业领域有所应用。又面临自学太慢无人指导?没有实战案例亲身体会?需要同行的小伙伴一起学习进步?
CDA 建模分析师-R语言课程,带你从R语言机器学习开始,立足与商业实践话题,稳扎稳打,带你有组织有纪律的走上你的数据科学家之路!
北京&远程直播:10月14~10月29
授课安排:现场班5900元,远程班4400元
(1) 授课方式:面授直播两种形式,中文多媒体互动式授课方式
(2) 授课时间:上午9:00-12:00,下午13:30-16:30,16:30-17:00(答疑)
(3) 学习期限:现场与视频结合,长期学习加练习答疑。
1.在线填写报名信息

2. 确认报名信息,网上缴费
3. 开课前加入课程微信与QQ学员群
4. 开课前一周发送电子版课件和教室路线图
第一阶段:[10.14]数据挖掘前沿与R语言
第二阶段:[10.15]回归建模分析方法
第三阶段:[10.21]决策树与神经网络建模
第四阶段:[10.22]分类器与组合模型
第五阶段:[10.28]客户与市场分析方法
第六阶段:[10.29]推荐算法提升客户价值
第七阶段:[线上选修]数据分析统计基础理论(一周)
第八阶段:[线上选修]Mysql数据库基础知识(一周)
第九阶段:[线上选修]Tableau数据可视化(一周)
1.全日制学生及CDA LEVEL Ⅰ老学员8折优惠(需提供学生证件证明);
2.同一单位三人及以上报名9折优惠,五人及以上8折优惠;
3.CDA LEVEL Ⅰ等级资格证书持有者立省1000元;
4.同时报名参加LEVELⅠ和LEVEL Ⅱ享受8折优惠。
王老师
Tel:18511302788
QQ:2315561922
Mail:[email protected]










