技术团队面临的困难总是相似的:在业务发展到一定的时候,他们总是不得不重新设计数据模型,以此来支持更加复杂的功能。在生产环境中,这可能意味着要迁移几百万条活跃的数据,以及重构数以千行计的代码。
Stripe的用户希望我们提供的API要具备可用性和一致性。这意味着在做迁移时,我们必须非常小心:存储在我们系统中的数据要有非常准确的值,而且Stripe的服务必须时刻保证可用。
在这篇文章中,我们将分享我们是如何安全地完成了一次涉及上亿数据量的大迁移经历。
Stripe有上亿规模的订阅数据。对于我们的生产数据库来说,做一次与所有这些数据都相关的大型迁移就意味着非常非常多的工作。想象一下,假如以一种顺序的方式,每迁移一条订阅数据要一秒钟,那要完成上亿条数据的迁移就要耗时超过三年。
Stripe上的业务一直在运行。我们升级所有东西都是不停机操作的,而不是可以在某个计划好的维护窗口内更新。因为在迁移过程中我们不能简单地中止订阅服务,所以我们必须100%地在所有服务都在线的情况下完成迁移操作。
我们很多的业务都用到了订阅数据表。如果我们想要一次改动订阅服务的几千行代码的话,那可以肯定地说我们一定会遗漏某些特殊场景。我们必须确保每个服务都能持续地操作准确的数据。
把数以百万计的数据从一张数据库表迁移到另一张中,这很困难,但对于许多公司来说这又是不得不做的事。
在做类似的大型迁移时,有种大家非常容易接受的四步双写模式。这里是具体的步骤。
-
向旧表和新表双重写入,以保持它们之间数据的同步;
-
把代码库中所有读数据的操作都指向新表;
-
把代码库中所有写数据的操作都指向新表;
-
把依赖旧数据模型的旧数据删掉。
Stripe的订阅功能帮助像DigitalOcean和Squarespace这样的客户构建和管理他们用户的计费账单。在过去的几年里,我们持续不断地增加了许多功能,来支持他们越来越复杂的计费模型,比如多重订阅、试用、优惠券和发票等。
在最开始时,每个Customer对象最多只会有一条订阅数据。所以我们的客户数据都保存成了单条记录。因为用户和订阅之间的映射关系非常直接,所以订阅信息就和用户数据保存在了一起。
class Customer
Subscription subscription
end
后来,我们发现有些客户希望他们创建的Customer对象可以对应多条订阅数据。于是我们决定把服务于单次订阅的单条订阅数据升级一下,换成一个订阅数组,以此来保存多条有效的订阅数据。
class Customer
array: Subscription subscriptions
end
在继续添加新功能的时候,这样的数据模型就出问题了。每一次对用户的订阅信息的改动都意味着要更新整条用户记录,以及查询用户数据的与订阅相关的检索语句。于是我们决定把这些订阅信息单独保存起来。
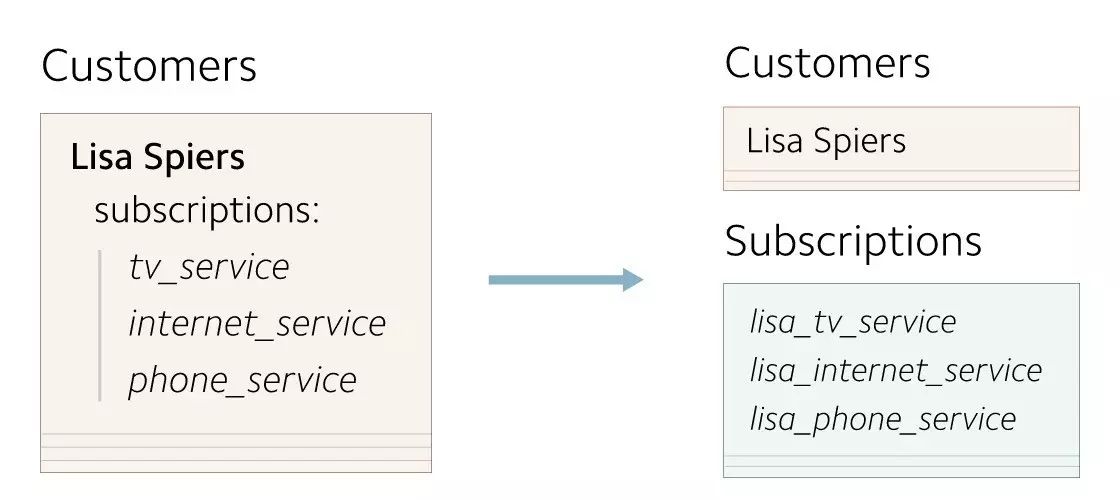
我们重新设计的数据模型把订阅信息移到了它们自己的表里。
复习一下,我们的四步迁移流程为:
-
向旧表和新表
双重写入
,以保持它们之间数据的同步;
-
把代码库中所有
读数据的操作
都指向新表;
-
把代码库中所有
写数据的操作
都指向新表;
-
把依赖旧数据模型的
旧数据删掉
。
接下来我们看看这理论上的四个阶段在我们的实际项目中是怎样实施的。
我们在迁移之前先创建了一张新的数据表。第一步就是开启复制新写入的数据,这样它就可以写到新旧两张表里了。然后我们再把新数据表中缺失的数据慢慢地补充过来,这样新旧两张表里的数据就完全一致了。
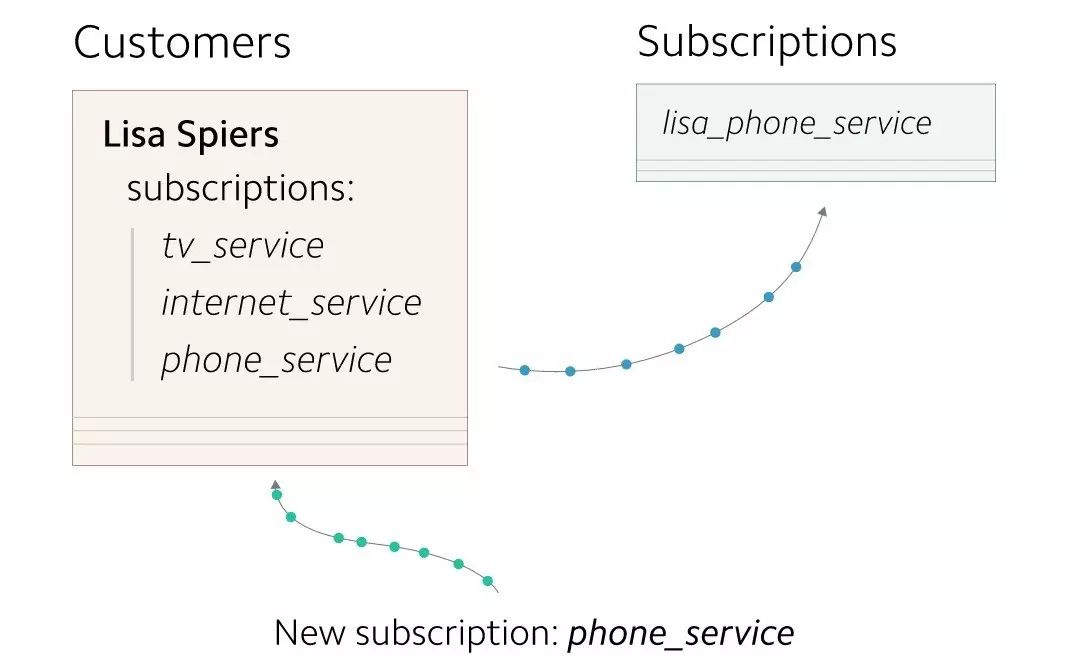
所有新的写入都要更新两张数据表。
在这个案例中,我们会把所有新生成的订阅信息都同时写入用户表和订阅表。在开始双重写入两张表之前,一定要认真考虑一下这一份额外的写入操作给生产库的性能带来的影响。有种减轻性能影响的方法就是慢慢地增大开启复制的数据量,这同时一定要仔细地盯着各项运营指标。
到了这一步,所有新创建的数据就都同时存在于新旧两张表里了,而比较旧的数据只保存在旧表中。于是我们可以以一种缓慢的模式开始拷贝已有的订阅信息:每当有数据被更新的时候,就自动地把它们也拷到新的表中。这种方法让我们可以开始增量地迁移已有的订阅数据。
最终,我们会把所有已有的用户订阅信息都补充到新的订阅表中去。
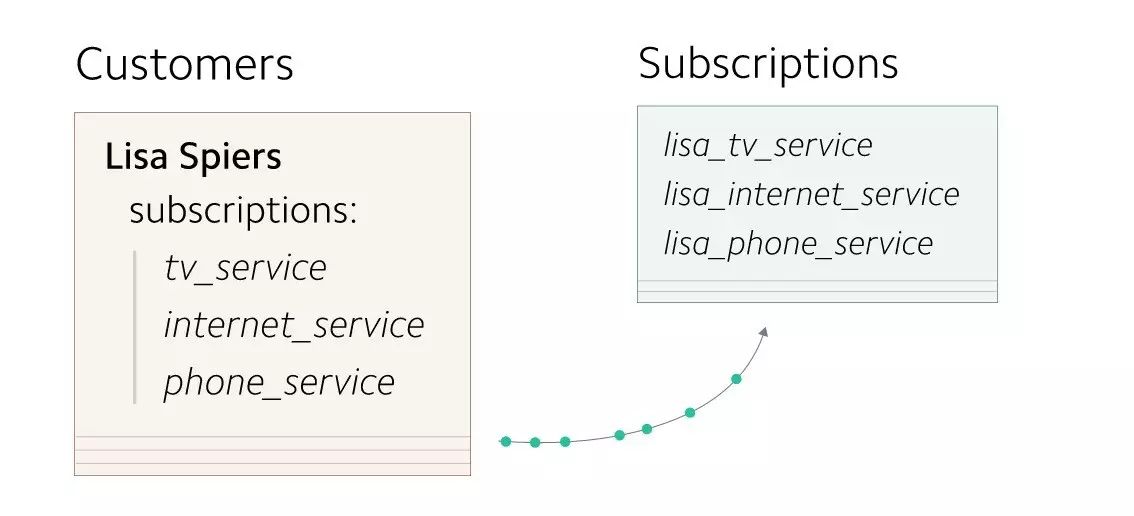

我们会把所有已有的用户订阅信息都补充到新的订阅表中去。
在生产数据库里补充新数据表的操作,代价最大的部分其实就是要找出所有需要迁移的数据而已。通过检索数据库来找出所有这样的数据需要检索生产库很多次,这会花费很多时间。幸运的是,我们可以把这个代价转用一个离线的方式完成,因此对生产库就毫无影响了。我们会为数据生成快照,并上传到Hadoop集群中,然后就可以用MapReduce的方法来快速地以离线、并行、分布式的方式处理数据了。
我们用Scalding来管理我们的MapReduce任务。Scalding是一个用Scala写成的非常有用的库,用它来写MapReduce任务非常容(写一个简单任务的话连十行代码都不用)。在这个案例中,我们用Scalding来找出所有的订阅数据。具体步骤如下:
-
写个Scalding任务来生成所有需要迁移的订阅数据的ID列表;
-
做一次大型的、多线程的迁移操作,来并行地把所有需要迁移的订阅数据快速拷贝过去;
-
当迁移结束之后,再运行一次Scalding任务,确保所有旧订阅表中的订阅数据都迁移到了新表里,没有遗漏;








