本文介绍了如何通过Python面向对象编程与金融数据网站Financial Modeling Prep(FMP)的API进行高效交互,以简化数据导入流程。文章首先概述了FMP API的特点和优势,然后详细阐述了如何使用面向对象编程来重构代码,提高数据导入效率。接着,通过创建一个名为SP500data的类,实现了一站式数据导入工具,能够快速导入S 500 指数中的各大公司财务数据。文章还介绍了并行编程在数据导入中的应用,以及如何通过fetch_all_data方法快速拉取所需全部数据。最后,通过实际用例展示了如何根据格雷厄姆数寻找折价股票。文章结尾提供了完整源码的获取方式。
FMP API提供准确、实时的市场数据和公司财务信息,支持多种端点服务,简化了复杂的财务数据获取流程。
OOP通过将数据和操作数据的函数封装在一起,提供了一种清晰的结构来组织和管理代码,适合将不同类型的财务数据请求封装成独立的功能模块。
SP500data类通过定义类和对象,将从API获取的数据封装成易于操作的形式,提高了代码的复用性,使数据导入更加简洁和直观。
结合格雷厄姆数模型,通过创建SP500data类的实例,快速获取到所需的必要信息,筛选出最具折价潜力的股票。

大家好,我是橙哥!今天,我将带你们一起深入了解如何通过 Python 实现面向对象编程,简化数据导入流程,并与金融数据网站Financial Modeling Prep(FMP) 的 API 进行高效交互。文末可获取本文完整源码。首先,让我们了解一下 FMP API。FMP 提供了一个简单且强大的接口,专注于为金融分析提供准确、实时的市场数据和公司财务信息。无论你是投资分析师、数据科学家,还是对金融建模感兴趣的开发者,FMP API 都能为你提供丰富的资源,包括全球股票、ETF、财务报表、财务指标、历史数据等。它的易用性和高效性让我一开始就深深喜爱,尤其是它提供的多种端点服务,简化了复杂的财务数据获取流程。更重要的是,FMP API 的文档清晰、直观,支持灵活的查询方式,使得用户可以快速上手。
我开始使用 FMP API 已有一段时间,然而,在最初的阶段,我总是不断地编写重复的函数来处理各种数据请求和解析任务。这种方式不仅繁琐,还容易出错。为了解决这个问题,我决定通过面向对象编程(OOP)来重构代码,将所有功能封装到一个 Python 类中,简化数据导入流程并提高效率。今天,我将带你们一步一步了解这个过程,并展示如何通过创建一个类来与 FMP API 高效交互。在软件开发中,面向对象编程(OOP)是一种常见的编程范式,它通过将数据和操作数据的函数(方法)封装在一起,提供了一种清晰的结构来组织和管理代码。OOP 可以帮助开发者将复杂的任务分解为可管理的模块,从而提高代码的可重用性、可扩展性和可维护性。在与 FMP API 交互时,面向对象编程非常适合将不同类型的财务数据请求封装成一个个独立的功能模块。每个模块可以独立执行任务,并且可以轻松进行扩展和修改。具体来说,我们通过定义类和对象,将从 API 获取的数据封装成易于操作的形式,不仅提高了代码的复用性,还使得数据导入变得更加简洁和直观。在本次分享中,我定义了一个名为 SP500data 的类,它专门与 FMP API 对接,旨在帮助用户快速导入 S&P 500 指数中的各大公司股价、财务报表、公司概况以及相关的财务指标。通过这个类,你可以轻松地获取到所需的各类财务数据,而无需重复编写请求和解析的代码。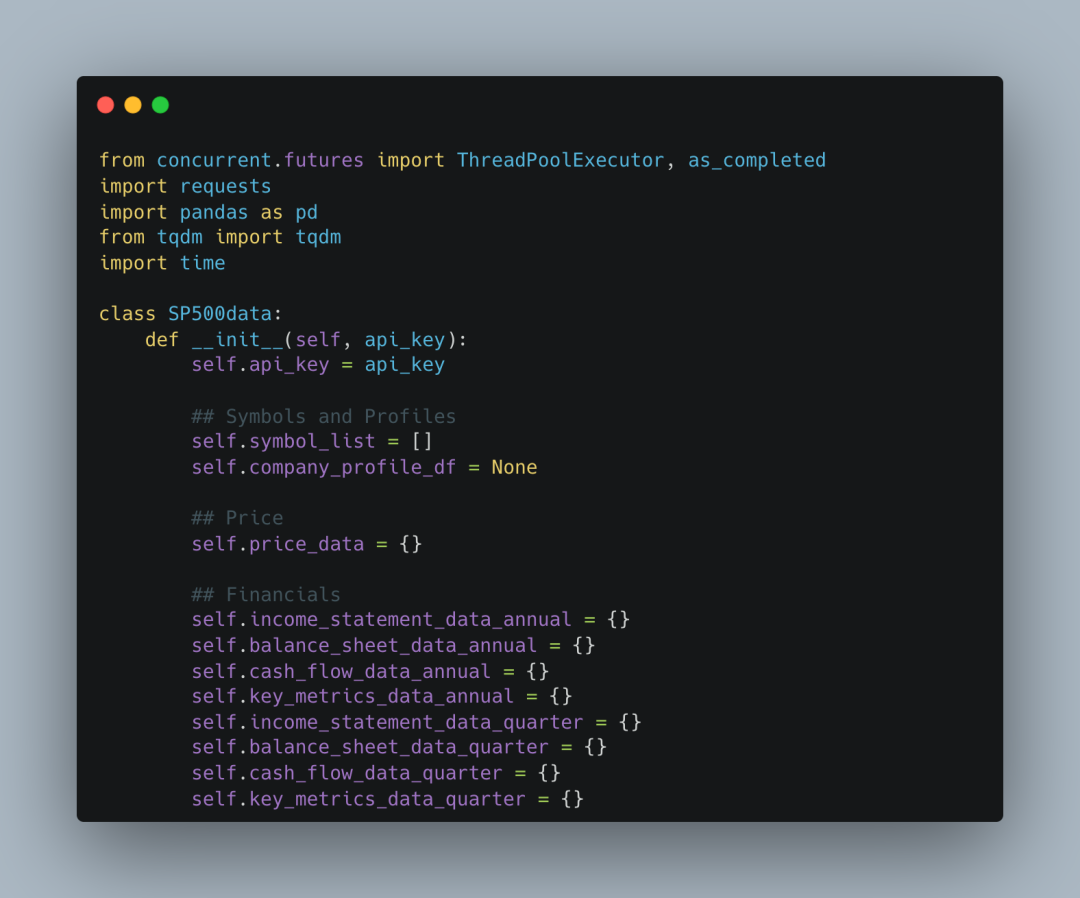
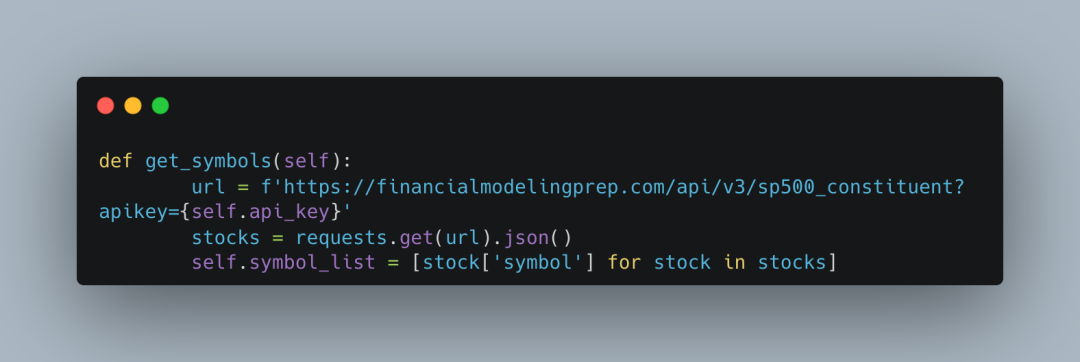
首先,我们需要用到股票代码和公司信息。接下来介绍的方法会依赖于标普500(SP500)指数中的公司股票代码。具体来说,get_symbols 方法会通过 sp500_constituent 端点获取这些股票代码,让你能够轻松获取到所需的公司信息。
导入公司简介和其他数据可能会非常耗时,特别是在数据量较大的情况下。而且,我发现导入数据的顺序其实并不那么重要。基于这两个原因,我决定利用并行编程来优化数据导入过程。通过并行编程,计算机可以将多个任务分配到不同的处理器上,这样就能同时运行多个任务,大大提高数据导入的效率,节省时间。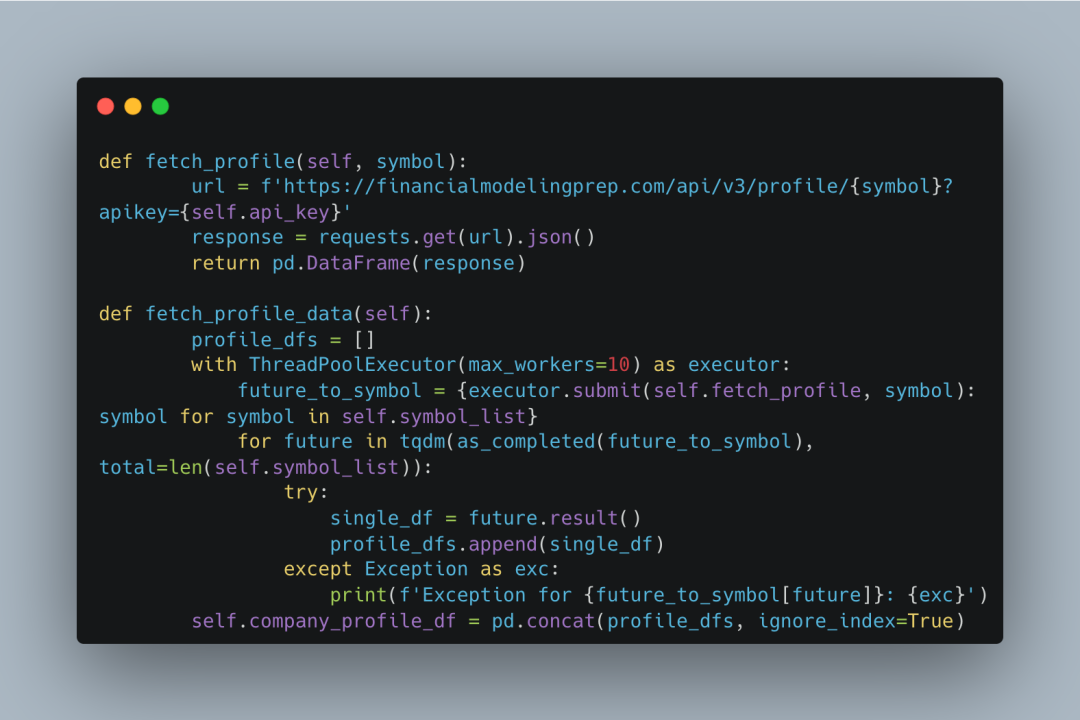
- 每家公司的过去五年OHLC(开盘、最高、最低、收盘)价格数据当你执行这些方法后,你的对象将瞬间变成一个财务数据的宝库。想要可视化一家公司的完整历史关键利润率?或者更高效地比较多家公司之间的财务表现?一旦调用这些方法,你的实例几乎只需要一行代码,就能轻松获取所有必要的数据。而且对于财务报表,值得注意的是,API 支持检索季度和年度报表,让你能灵活选择最适合的时间粒度。
到目前为止,我已经创建了多个方法,但如果我想进行更深入的分析,可能需要从这些方法中提取所有的数据。为此,我设计了一个 fetch_all_data 方法,它会自动调用之前创建的所有函数,快速拉取所需的全部数据。为了确保调用不会超出 API 限制,我添加了一个延迟变量,用户可以根据自己的 API 计划进行灵活调整。比如,FMP API 的高级计划允许每分钟进行 750 次调用。虽然这个调用频率已经很充足,但考虑到 fetch_all_data 方法可能在短短一分钟内发出数千次 API 请求,因此适当调整延迟是必要的。一旦数据拉取完成,所有所需的信息都会自动汇总到对象实例中,下一步的分析工作可以立刻开始!
实际用例:基于格雷厄姆数寻找折价股票
工作已经完成,现在是时候展示一个实际用例了。最近,我读完了本杰明·格雷厄姆的经典之作《聪明的投资者》,这让我受到启发,决定根据最新的格雷厄姆数,抓取按行业和部门分类的最具折价潜力的股票列表。
接下来,让我们创建一个对象实例,并调用 fetch_all_data 方法来拉取所有相关数据。通过这一方法,我们能够迅速获取到所有的必要信息,为接下来的分析和决策打下基础。









