
雷锋网按:
AlphaGo 终于又来了。5月23日,也就是明天,曾在去年以一己之力将“人工智能”浪潮带到新层次的围棋人工智能AlphaGo就将再次出马。在这次为期5天的活动当中,AlphaGo将会与世界最顶尖围棋选手柯洁展开正式对决,同时还会进行耳目一新的“配对赛”以及“团体赛”。

目前雷锋网了解到的具体赛程如下:
•
5月23日,开幕式、柯洁 vs AlphaGo三番棋第一场;
•
5月24日,人工智能论坛;
•
5月25日,柯洁 vs AlphaGo三番棋第二场;
•
5月26日,配对赛,团队赛(相谈棋);
•
5月27日,柯洁 vs AlphaGo三番棋第三场。
这次比赛核心目的只有一个——在公开场合验证AlphaGo的实力,看是否已经打造出了在围棋上超越所有人类的“AI”。
作为国内最重要的科技媒体,雷锋网也将全程跟踪此次赛事。但在比赛正式开始前,有几个问题你可能需要了解一下:
1.
这次的“新AlphaGo”跟“老AlphaGo”有什么不同?
2.
柯洁能否战胜“新AlphaGo”?
3.
比赛相关直播应该如何观看?
新AlphaGo:砍断“人类束缚”

作为一个从2014年发展至今的围棋人工智能项目,其实AlphaGo在发展历程中使用过多个名字,比如最早期亦城围棋上的“DeepMind”,又或者是之前在野狐平台上的“Master”。那么这次的“新AlphaGo”是否也只是一个新名字?
答案必然是否定的,之前起新名字很可能有保密、个人喜好等原因,但这次新添加的“新”字只为了突出一点——这是“机器自学”为主的一版AlphaGo。

这一点判断的线索,来自于今年初,Master在网络上一口气横扫60名人类棋手的时候。当时Master第二次战胜柯洁之后,棋圣聂卫平曾表示:
Master改变了我们传统的厚薄理念,颠覆了多年的定式。围棋远不像我们想象的那么简单,还有巨大的空间等着我们人类去挖掘,阿法狗也好,Master也罢,都是‘围棋上帝’派来给人类引路的。
著名棋手古力在成为Master的第60个手下败将,之后,也在微博发表了自己的感受:
作为第 60 个勇士,牺牲了。。。经过这几天的对局,我深深的感受到围棋的神秘,似乎 Master 给我们打开一道围棋的神秘之门,不论胜负,人类与人工智能共同探索围棋世界的大幕即将拉开,新一次的围棋革命正在进行着。。。
这种表现,与将近一年前的“老AlphaGo”可谓天差地别。想要达成这样的成绩只有一种可能——DeepMind寻找到了一种机制来摆脱围棋中的“人类束缚”。
迷之改进:一举让AlphaGo成为人类老师

作为一个极其特殊的棋类和任务,围棋拥有数量极其庞大的可能性,总的局面数量达到10^172,而可观测宇宙范围内的原子数量不过10^80。这也意味着穷举绝对不是一条明智的路线。
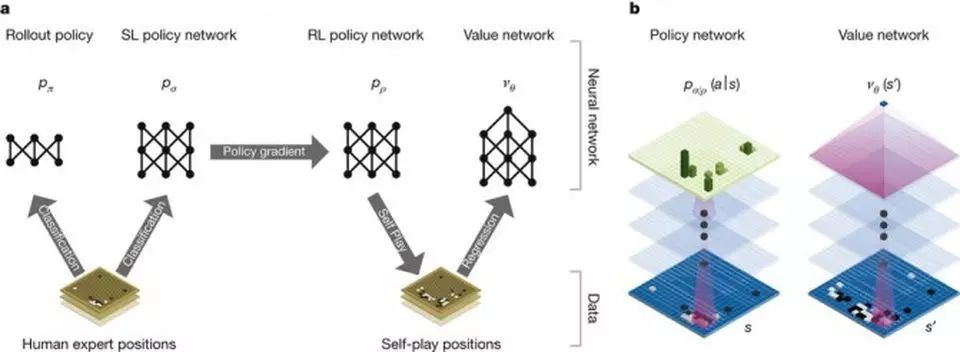
最终DeepMind给出了一套能够“模拟”出人类顶尖高手的方案:深度学习+蒙特卡洛搜索树+自我进化。
这一套架构在DeepMind发布在《自然》杂志中的论文中已经有详细叙述
,
(https://www.nature.com/nature/journal/v529/n7587/full/nature16961.html)
如果你对其中的细节感兴趣,推荐阅读国内人工智能创业公司彩云AI创始人、CEO袁行远在知乎上的相应回答。
(https://www.zhihu.com/question/41176911/answer/90118097)
深度学习用以分析人类棋盘,蒙特卡洛搜索树用来减轻工作量,自我进化用来提升能力。但有限的运算能力还是给DeepMind出了一个不小的难题,后者最终想出了一个办法:只对学习到的人类棋招进行蒙特卡洛搜索树运算,这恰如人类棋手依赖定式。
定式,又名定石,指的是人类下围棋长久积累下来的一种经验,对弈双方在特定情况下会遵循固定下法。著名棋手吴清源则将简单描述为“在角部彼我棋子接触时最合理的走法”。
这些定式被记载在各式各样的棋谱当中,成为新手入门必看的书籍。
虽然定式是某种意义上是最合理的走法,但它却是理想化条件下的产物,想要完整复现定式,意味着双方都必须抱有同样的理想化思路。而历史上并不缺乏不遵守定式,或者用新定式打败对方的事例。
问题来了,为什么千变万化的围棋会出现定式?而且死守定式会输,不学习定式也会输。答案只有一个——人类需要定式来减少围棋上面的变化,这样进入中盘之后人类才能利用自身能力掌握棋局走向。
凑巧的是,这回我们遇到的是运算能力远超人类的计算机,让掌握更多乃至全部围棋奥秘拥有了一丝可能。
但究竟新AlphaGo怎么样摆脱“人类束缚”?参考之前“老AlphaGo”的工作方式,排除运算过程中所有人类元素可能是最彻底的方法。但这样一来就必须找到另外一种减轻运算压力的策略。目前来看,这个秘密也只能等DeepMind方面稍后公开了。
人类败局已定?

尽管去年人类代表是韩国选手,但明眼人都可以看出当下和去年围棋人机比赛的热度差别。这从另外一个侧面也反映出了绝大部分观众的看法:这次人类要输。而去年3月李世乭1:3扳回一局时,柯洁还曾在直播中表示:
我们必须承认谷歌就是了不起, AlphaGo 确实是超一流的水平,但是也没有到不可战胜的地步。

而在上个月的发布会上,柯洁却显得尤为谦逊:
有点小紧张,但我不会轻易言败,在阿尔法围棋出现之前,我以为计算力是AI的优势,后来让我震惊的是他的大局观,AI的宏观思维让我很佩服。AlphaGo围棋让我们重新思考,这么下是不是错的,会给我们很多启发,输的痛苦是外界无法想象的,我会不惜一切去追求胜利。
“轻易言败”这样的措辞与其在央视节目上的慷概激昂形成了强烈对比。客观公正地说,柯洁的胜算很小,三番棋中哪怕有一盘能够获胜都是成功。
而另外两场比赛(配对赛、团队赛)同样值得认真关注,这两场比赛中,人类棋手将首先与AlphaGo配对比赛、然后再“群殴”AlphaGo。这不仅体现了DeepMind的自信,同时也再次突出本次本次围棋峰会的主题:
顶尖棋手以赌局开创性的方式为世人带来精彩绝伦的棋艺展示,挑战人类智慧的极限。同时AlphaGo与世界最优秀的棋手相互启发,共同探索围棋背后的深远奥秘。
换句话说,别再纠结人类和机器谁输谁赢了,赶紧认真感受科技带来的巨大改变、预见未来吧!
注:点击“阅读原文”进入优酷直播页面。






