|
|
专栏名称: 待字闺中
| 深度分析大数据、深度学习、人工智能等技术,切中实际应用场景,为大家授业解惑。间或,也会介绍国内外相关领域有趣的面试题。 |
目录
相关文章推荐

|
axb的自我修养 · 上班上到位了是什么感受。下班开车回家,前面跟 ... · 昨天 |

|
封面新闻 · 已报案!零容忍!刚刚,百度回应了 · 昨天 |
|
|
封面新闻 · 已报案!零容忍!刚刚,百度回应了 · 昨天 |

|
杭州市市场监督管理局 · 最新消息!三项国际新标准在杭发布! · 2 天前 |
|
|
杭州市市场监督管理局 · 最新消息!三项国际新标准在杭发布! · 2 天前 |

|
宁德广播电视台 · 喜讯!宁德新增1家国家级博士后科研工作站! · 2 天前 |
|
|
宁德广播电视台 · 喜讯!宁德新增1家国家级博士后科研工作站! · 2 天前 |

|
文商资讯 · 创业融资丨股权融资的9个阶段 · 2 天前 |

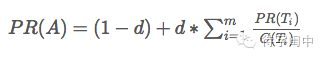

推荐文章
|
|
axb的自我修养 · 上班上到位了是什么感受。下班开车回家,前面跟你毫无交集的车在路口-20250319230025 昨天 |
|
|
封面新闻 · 已报案!零容忍!刚刚,百度回应了 昨天 |
|
|
封面新闻 · 已报案!零容忍!刚刚,百度回应了 昨天 |
|
|
杭州市市场监督管理局 · 最新消息!三项国际新标准在杭发布! 2 天前 |
|
|
杭州市市场监督管理局 · 最新消息!三项国际新标准在杭发布! 2 天前 |
|
|
宁德广播电视台 · 喜讯!宁德新增1家国家级博士后科研工作站! 2 天前 |
|
|
宁德广播电视台 · 喜讯!宁德新增1家国家级博士后科研工作站! 2 天前 |
|
|
文商资讯 · 创业融资丨股权融资的9个阶段 2 天前 |

|
伊犁我的家 · 免费清洁打扫只是噱头······伊宁市已有人上当受骗! 7 年前 |

|
爱股君2020 · 【侃市】寻股启示:刘主席又操着手机摸着号码,谁是下一个倒霉蛋? 7 年前 |

|
环球时报 · 4月27日19时07分,我国成为第三个掌握推进剂在轨补加关键技术的国家! 7 年前 |

|
百度百家 · 腾讯入股一月之后,转转为什么没有变得更好? 7 年前 |

|
大学生赛事资讯 · 3000元奖学金等你来拿!环球海外香港金融精英实习奖学金计划招募中 7 年前 |