2017 年 4 月 3 日至 8 日,第 26 届国际万维网会议(26
th
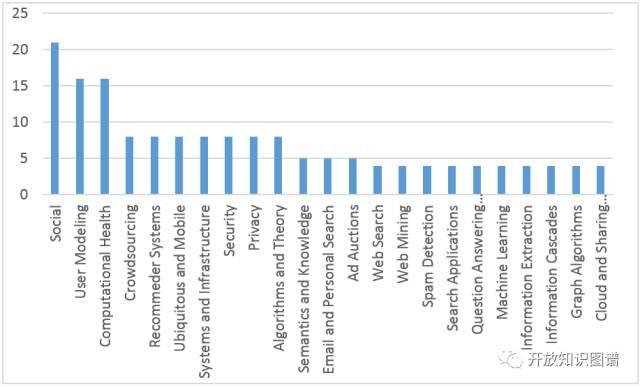
International World Wide Web Conference) 在澳大利亚珀斯顺利举行,本届大会共收到 966 篇论文投稿,比去年增长了 33%,大会最终录用 164 篇论文,录用率为 17%。不同主题下的收录论文数量如下表所示:
本文主要介绍总结一下 WWW2017 中语义和知识相关的论文,一共 9 篇文章。
在 WWW2017 的 Semantic and Knowledge 主题下共有 5 篇文章,分别涉及语义和知识的五个不同方面,包含在线本体使用的用户行为分析、RDF 查询、结合社交网络的实体挖掘、特殊知识库的构建以及知识追踪。下面分别介绍一下这五篇文章。
1 How Users Explore Ontologies on the Web: A Study of NCBO's BioPortal Usage Logs
作者分别来自斯坦福大学和德国科布伦茨-兰道大学以及格拉茨技术大学。垂直领域的本体构建和维护需要花费大量的人力物力,所以已有本体的发现和重用是重要的策略。目前已经有一些已经有集成了许多本体的在线仓库并有很多人使用,为了提供更好的服务来帮助用户重用已有本体,本文以生物医药领域 BioPortal 为例,对用户浏览本体的行为做了分析:
1)
探索用户使用本体时不同的行为模式,通过一阶马尔可夫链对用户的每次浏览记录(a session,用户的一次操作序列记录)进行建模,并用转移矩阵的特征向量表示本次的浏览行为,然后对所有用户行为的向量表示进行 k-means 聚类,主要分析出7种不同的行为类型,记录最多的两种类型为 Class Explorers 和Specific Class Browsers, 其他五种分别为 Main Page Visitors, Ontology Overview Visitors, Ontology Tree Explorers 和 BioPortal Experts。
2)
探索不同的行为模式在不同本体的分布情况。结果如下图所示:
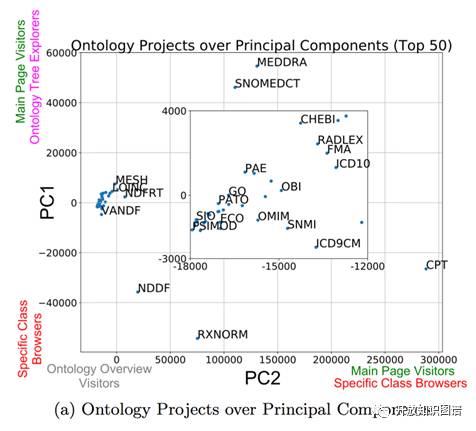
文章中指出本体本身的特征也会影响用户的交互行为。作者希望这个研究能够帮助引导在线本体系统的建设以带给用户更好的体验。
2 Extracting Emerging Knowledge from Social Media
本文关注的问题是 emerging entities 的抽取,由于知识库的不完整性,现在有很多抽取技术用于自动抽取知识用于补充完整知识库,但是多数的抽取技术倾向于关注比较流行的事物,对于用于低频数据记录的事物的提取有限,从而造成了知识库中的长尾。低频的长尾实体包括 emerging entities,虽然当前的受关注度不高,但可能在未来有较大的影响力,所以尽早发现低频实体并在知识库中建立相关描述,有利于捕捉发展趋势,例如在电子商务领域。本文主要从社交媒体中挖掘 emergency entities,由于社交媒体包含有大量及时的讯息,即使是低频的信息也有所踪迹。面对的主要挑战来源于社交媒体中相关的记录的一些特性:unclassified、dispersed、disorganized、uncertain、partial、possibly incorrect,这些特性都给提取造成了一定的困难。
本文的实用Twitter做为社交媒体数据源,选取了三个领域进行抽取工作:Fashion designers, Fiction writers,Live events。首先由相关的领域专家提供少量种子实体(emerging entity seeds),然后通过 seeds 选取相关的候选实体(candidates),并将每个实体表示为向量,根据种子实体的表示得到中心表示(centroid),通过计算候选实体到中心表示的距离排序各实体并提取距离最近的k个候选实体为最终结果。本文将抽取方法分为两类:1)Syntacticmethods:分析对应种子(seeds)的推文,主要利用用户名(handles,以@为标识)以及话题(hastags,以#为表示)相关的特征。2)Semantic Methods:由领域专家提供和本领域相关的可以对应到 DBPedia 定义的类别,例如 fashion designer相关的类别有brands、photographers、magazines。用 Dandelion(一个商用软件)将文本中的handles、hashtags和专家提出的相关类别作映射。利用推文文本本身的特征的同时也利用文本和DBPedia的部分映射关系,更好地把握文本的语义信息。
3 Distilling Task Knowledge from How-To Communities
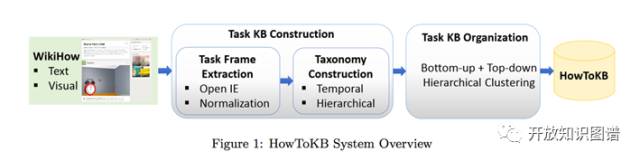
这篇文章提出了一个很有意思的问题:在搜索引擎中有大量用户在搜索问题解决型的信息,例如如何修自行车,但是作为搜索引擎中日益重要的知识库却缺乏这类问题解决型(How-to)的知识。WikiHow 是一个专注于解决“怎么做”问题的网站,作者基于 WikiHow 最终构建了一个专门包含问题解决型知识的知识库 HowToKB。HowToKB 的主要构建步骤有:1)通过 OpenIE 4.2 软件从 WikiHow 网站的文本中抽取三元组。2)组织 Task KB,主要包含两个任务,一个是WikiHow内容的去重和聚类,例如任务 paint a wall 和 color aceiling 有很大相似性。另一个是任务之间的消歧,例如任务 use a keyboard 可能是 use a music keyboard 也可能是 use acomputer keyboard。首先计算三种相似度:Categorical similarity、Lexical similarity 和 Vector similarity,将三种相似度当作特征生成最种两种任务(task)之间的相似度,然后采用层次聚类算法对任务进行聚类。HowToKB最终包含了去歧后的任务层次分类,每个任务的子任务顺序以及完成这个任务所需要的工具。在关于知识库构建和知识库组织方面的测评中,HowToKB 都有较高的准确率。作者最后还测试了一个 use case:自动搜索和 HowToKB 中的任务相关的 Youtube 视频。HowToKB 的构建过程如下图:
原文链接:
https://mp.weixin.qq.com/s/nj70fFupsY1m0Efip2frdg





