基础准备
前面我们推送了三篇多维尺度分析的文章,安排的顺序是由浅入深,方便大家学习和掌握:
阅读过上面文章的朋友应该发现,这些多维尺度分析都是基于一个数据矩阵就能得到分析结果,也就是只考虑一个评判者的态度。如果有多个评判者,获得多个数据矩阵,那么就需要考虑不同评判者之间的个体差异。这就是今天我们将要介绍的内容:加权多维尺度分析。
分析原理
多个评判者对多个变量之间的相似性或相异性打出分数,得到多个不同的数据矩阵,如何对它们进行多维尺度分析呢?学习过前面几篇文章的朋友会很容易想到,将所有矩阵的数据进行平均,整理成一个矩阵,然后用古典MDS分析即可,这种处理方式可以反映多个评判者的平均态度,但是会损失不同评判者态度差异的信息。例如,跳水比赛的裁判打分,对同一个运动员的同一个动作,不同裁判打出的分数时候不一样的,虽然这些裁判在比赛之前都经过训练统一标准,但依旧会存在差异。这种情况,使用加权多维尺度分析更为合适。
加权多维尺度分析不仅会分析每个数据矩阵的结构,而且会进一步分析不同矩阵之间的差异。首先回忆一下古典多维尺度分析的分析原理:找到一个r维空间,用空间中的n个点表示等待分析的n个变量,使得n个点的距离结构关系尽可能的与n个变量的距离结构关系相同。加权多维尺度分析仍然假定n个变量可用r维空间中的n个点表示,但对不同的数据矩阵,其散点间距离的定义公式不同,需要通过矩阵数据情况添加权重。最后综合考虑所有数据矩阵的散点情况,输出加权多维尺度分析的结果。
案例分析
先说些市场情况。根据中国食品工业协会发布的《2016年度饮料行业整体运行报告》,去年我国饮料类商品零售额2175亿元。报告指出,随着消费群体、消费理念以及消费习惯的转变,整个饮料行业的情况也发生了巨大的变化,业绩下滑成为不争的事实,主流消费群体从碳酸饮料过渡到茶饮料后又过渡到包装水和健康饮料。

2016年,包装饮用水类的市场占比继续加大,达到51.6%,比上年同期增加2个百分点;碳酸饮料类比重为9.6%,比上年同期降低0.6个百分点;果汁和蔬菜汁类比重为13.1%,比上年同期降低1.2个百分点;“非三大”饮料比重为25.7%,比上年同期降低1%。在“非三大”饮料中,去年凉茶行业市场销售收入达561.2亿元,同比增长4.2%,占整个饮料行业市场份额的8.8%,位居饮料行业第四大品类。其中,加多宝品牌凉茶以52.6%的销售额市场份额位居首位;而在整个罐装凉茶行业市场,加多宝品牌凉茶以70.7%的销售额市场份额位居第一名。茶饮料、功能饮料和健康饮用水所占份额在不断提高,碳酸饮料市场进一步被蚕食,以凉茶、纤维饮料、近水饮料为代表的新品类迅速增长,在市场份额中挤入主流。
由以上情况可知,饮料市场正经历着消费者分化和口味变化的剧变过程,因此开发新品饮料,不断满足细分市场要求,成为各家饮料企业的工作重心。现在有一份由10个消费者对10种饮料的不相似性的打分数据(分值在0~100分),每位消费者的打分数据形成一个矩阵,整理进SPSS软件的形式如下:
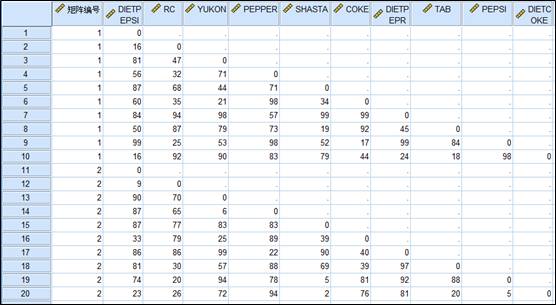
(例题数据文件已经上传到QQ群中,需要的朋友可以前往下载)
分析思路
本案例涉及的相异性矩阵有10个,可以用重复多维尺度分析,但是这样会损失掉数据的变异信息;其次可以使用加权多维尺度分析,下面具体介绍如何用SPSS进行加权多维尺度分析,并对结果进行解释。
分析步骤
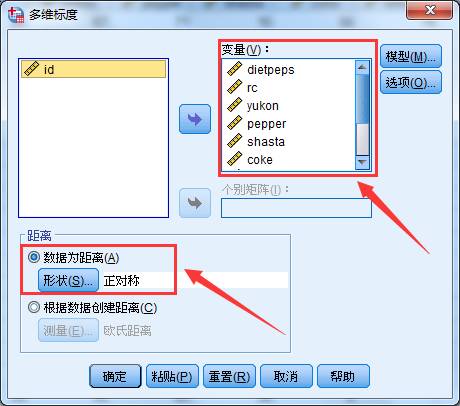
1、选择菜单【分析】-【标度】-【多维标度(ALSCAL)】,在跳出的对话框中进行如下操作,将10种饮料的品牌选入变量框中;因为案例的数据整理成正对称矩阵,因此选择的矩阵形状为正对称。
2、点击【模型】按钮;因为数据是由消费者打分得到的,所以作为定序数据处理比较合适,考虑到消费者的打分都是主观打分,即使分数相同,饮料之间不相似程度也可能不同,因此再选中解除绑定已绑定的观察值。在标度模型中,选择个体差异欧式距离,并将允许主体权重为负选中,这样就会为每个矩阵赋予不同的权重。
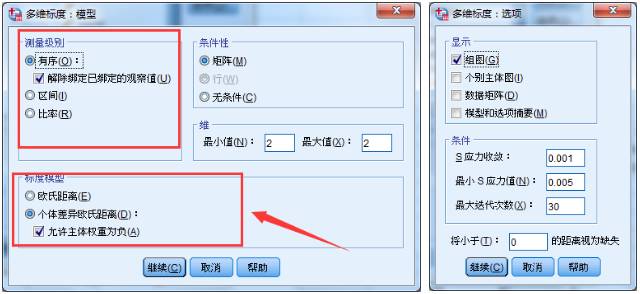
3、点击【选项】,选中组图。最后点击确定,输出结果。
结果解释
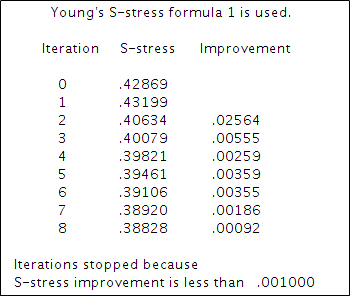
1、迭代计算过程;本次加权多维尺度分析经过8次迭代计算,应力值S-stress的变化小于0.001,得到最终结果。
2、拟合情况;模型首先会对10个矩阵分别拟合MDS模型,然后按照加权的方式进行模型效果平均。从结果可知,每个矩阵的拟合效果差异很大,如第一个消费者的决定系数(RSQ)为0.531,第2个消费者的决定系数只有0.278。最终加权平均后,总的决定系数为0.51487,应力系数达到0.3156,可见模型的拟合效果很差,结果只能作为参考。

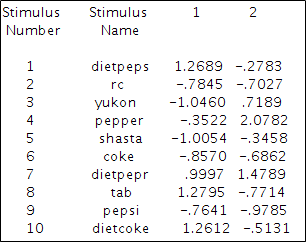
3、10种饮料在二维空间中的坐标值。
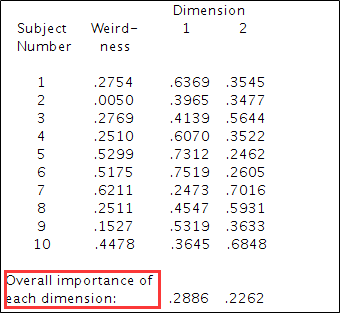
4、权重结果;下表给出了每个矩阵在最终模型中的权重,以及在每一个维度的分配比例。还会给出最终两个维度的重要性比例。维度1能够解释原始信息的28.86%,维度2能够解释原始数据信息的22.62%%,两者相加就是上方RSQ值0.5148。从这里同样可以知道最终的拟合结果不好。
5、根据这10种饮料的具体情况并结合位置结构图,可以从两个方面进行解释:两个维度含义和不同饮料的接近程度。
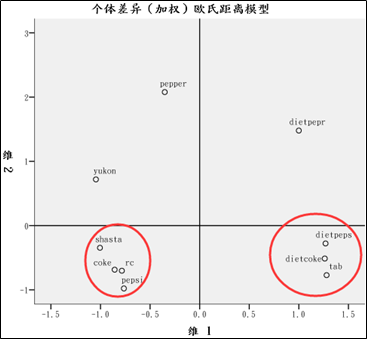
在第一维度上,三种无糖饮料(dietpepr,dietpeps,dietcoke)在右侧,而与它们对应的有糖版本(peper,pepsi,coke)在左侧,因此第一维度可以解释为饮料对健康的有利程度;在第二位维度上,pepper和dietpepr在上方,yukon在中间,其它的饮料在下方,所以第二维度可以解释为饮料的口感。
根据各种饮料的销售情况,并结合以上的维度解释,就能够帮助饮料厂家分析出那些区域还存在品牌空缺,那些区域的饮料是当下消费者愿意买单的区域。这就是加权多维尺度提供给公司商务部门进行市场研究的分析方向。
总结一下
虽然一个消费者对于某个产品的评价有其自身的考虑方向和权重,有随机性,但众多消费者对于同一个产品的看法却具有聚集性和局部共性,这就是商务部门调查和分析消费市场时需要抓住重要信息。问卷调查是将人们主观感受量化的最好工具之一。本案例通过问卷采集消费者主观感受数据,然后运用加权多维尺度分析总结出大多数消费者对于饮料的评价指标中,口感和健康度的权重是很大的。因此饮料公司在开发和宣传饮料时需要在这两个方面多下功夫。除此之外,消费者是分群的,不同消费者喜欢不同维度的饮料,所以开发针对不同消费群体的产品也可以重点考虑。
SPSS生活统计学希望通过数据分析方法和实际应用的结合介绍,让大家更加深刻的理解数据分析方法的分析理论、逻辑和内涵,这样才能真正的学以致用,触类旁通。统计分析重点不在分析方法,而在与分析者的分析逻辑思维,而分析逻辑思维的基础就是理论基础。
所有例题的数据文件都会上传到QQ群中,需要对照练习的朋友可以前往下载,QQ群号见下方温馨提示。
生活统计学不仅有各种数据分析方法,更有容易被大家忽视的生活常识。
温馨提示:






