作者丨李雪岩、
徐磊、吕晓旭
责编丨魏伟
“
去年10月,去哪儿网实现了Spark 1.5.2版本运行在Mesos资源管理框架上。目前,线上已经注册了44 个Spark任务,在运行这些任务的过程中,他们遇到的最大的问题就是动态扩容问题。
”
去年10月,我们实现了Spark
1.5.2版本运行在Mesos这个资源管理框架上。随后Spark出了新版本我们又对Spark进行了小升级,升级并没有什么太大的难度,沿用之前的修改过的代码重新编译,替换一下包,把历史任务全部发一遍就能很好的升级到1.6.1也就是现在集群的版本,1.6.2并没有升级因为感觉改动不是很大。到现在正好一年的时间,线上已经注册了44
个Spark任务,其中28个为Streaming任务,在运行这些任务的过程中,我们遇到了很多问题,其中最大的问题是动态扩容问题,即当业务线增加更复杂的代码逻辑或者业务的增长导致处理量上升的时候会使Spark因计算资源不足,这时候如果没有做流量控制则Spark任务会因内存承受不了而失败,如果做了流量控制则Kafka的lag会有堆积,这时候一般就需要增加更多的executor来处理,但是增加多少合适一般不太好判断,于是要反复地修改配置重新发布来找到一个合理的配置。
我们在Marathon上使用Logstash的时候也有类似的问题,当由于接入一个比较大的日志导致流量突然增加使得Logstash处理不了时,Kafka的Lag产生堆积,这时我们只需直接上Marathon的界面上点Scale然后填入更大的实例数字就能启动了一些Logstash实例自动平衡地去处理了。当发现某个结点是慢结点不干活的时候,只需要在Marathon上将对应的任务Kill掉就会自动再发一个任务替补他的位置,那么Logstash既然都可以做到为什么Spark不可以?因此我们决定在Spark
2.0版本的时候来实现这个功能,同时我们也会改进其它的一些问题,另外Spark2.0是一个比较大的版本升级,配置与之前的1.6.1不同,不能做到直接全部重发一遍任务来做到全部升级。
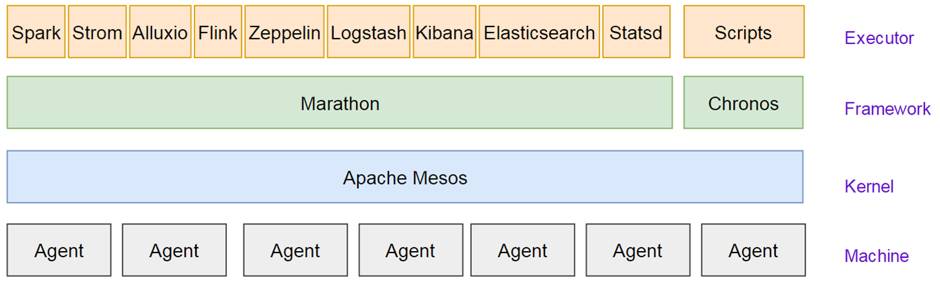
( 图1)使用Logstash的管理架构
在这里我们首先介绍一些Mesos的一些相关概念,Mesos的Framework是资源分配与调度的发起者,Spark自带了一个spark-mesos-dispacher的Framework用来管理Spark的资源调度。而Marathon也是一个Framework他的本质和mesos-dispacher或spark
schedular相同。
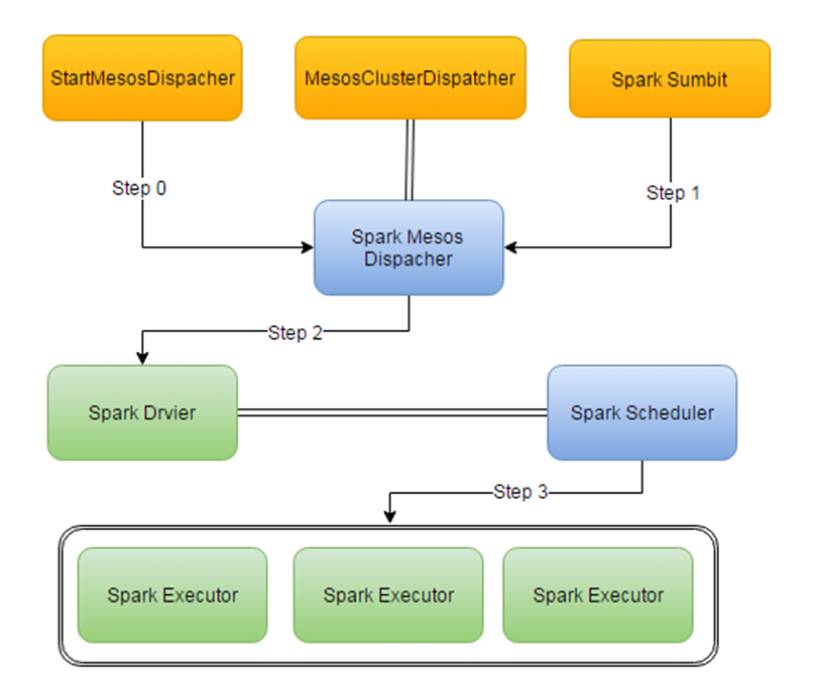
(图2)Mesos-dispacher架构
在图2在这个架构中,你首先得向mesos注册一个mesos-dispacher的Framework,然后,通过spark-sumbit脚本来向mesos-dispacher发布任务,mesos-dispacher接到任务以后开始调度他负责发一个Spark
Driver,然后driver在mesos模式下,他会再次向mesos注册这个任务的Framework也就是我们看到的Spark
UI,也可以理解为他自己也是个调度器,然后这个Framework根据配置来向Mesos申请资源来发一些Spark Executor。
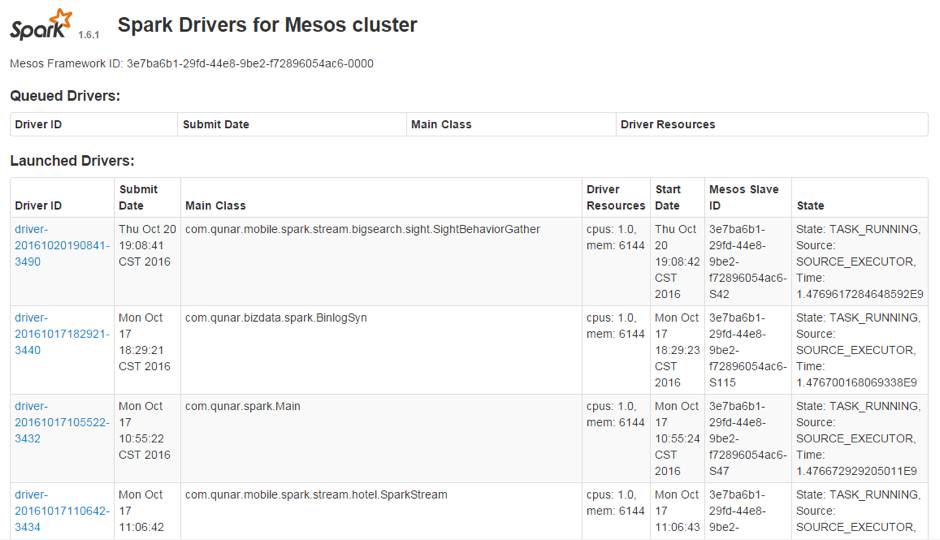
(图3)Mesos-dispacher功能截图
从图3可以看出,mesos-dispacher只提供了下功能:
-
他只提供了一个配置查看的界面,可以看到资源分配的信息,点进去以后可以看到SparkConf的一些参数,但是这个我们在业务线发布的时候已经拿到了这些配置,在这里只能确认下Driver是否配置正确,并且在SparkUI上也能看到。
-
他自带一个Driver队列,他会按顺序依次发布,当资源不足时会在队列里等待。
-
他自带一个Driver的HA功能,但是当你提交Driver代码有问题,他会不断地反复重发,比较难杀掉,但也是能杀掉的,并且没有次数限制。所以我们一般也不开放这个功能。
所以mesos-dispacher并不是一个完备的Framework,在我们使用的过程中发现了存在以下的问题:
-
在我们发布Spark的时候需要向mesos-dispacher提供一个SPARK_EXECUTOR_URI的配置来提供SPARK运行环境的地址,一开始我们是使用http的方式来放环境的,但是在一次需要发60个executor的时候流量打满了,原因是我们编译出来的Spark的环境包大概250MB,在发布的时候60台机器同时拉取这个环境就把流量打爆了。因此我们的解决方案就是在每一台机器上都部署Spark的环境,把SPARK_EXECUTOR_URI设成本地目录来解决这个问题。
-
界面上的配置并不会真正地同步到driver或executor。由于SPARK的配置很灵活,你的mesos-dispacher启动的时候会读取spark-defalut.conf来加载配置,每次发布时他又会从spark-env.conf里读取配置,发driver的时候,driver又会从他的jar包里的配置读取配置,用户自己也可以设置sparkConf的配置,executor的jar包里同样也有配置,最终你会发现有些配置设了生效了,有些配置的设置他没有传递,从而造成配置混乱。
-
mesos-dispacher基本功能缺失。mesos-dispacher虽然是专门为mesos设计的,但是他对mesos的基本功能,如role和constrain支持都不好,如果不修改代码是无法支持role和constrain,关于这个我提交了个一PR并且在Spark2.0已经没有这个问题了。
mesos-dispacher并不能运行时修改配置,必须重启。比如我们上了一些新机器,打了其它一些标签或者是多标签,如果想使其生效必须停止mesos-dispacher再启动才能生效,无法在运行时修改。mesos-dispacher默认工作在非HA模式下,因此在启动mesos-dispacher在的时候一定要加上Mesosr的zk这样当停止了mesos-dispacher以后,在mesos-dispacher上的任务将不会受到影响,当重新启动mesos-dispacher的时候会自动接管任务。
-
没有动态扩容功能。我们希望做到的就是可以让Spark可以在运行时增加实例或减少,但是受于架构限制mesos-dispacher只能管理driver,如果改mesos-dispacher的代码的话只能实现动态扩driver没有意义。
-
此外也有另一种方案就是帮助Spark改进他的Framework使他更强大,但是我们发现只需要Marathon这一个优秀的Framework就可以了,重复造轮子的成本比较大。同时也不希望对Spark代码有过多的修改,这样不利于升级。
由于mesos发布有很多种模式,我们在做这个时候主要考察了2种模式。
独立集群模式
该模式需要启动一个master作为发布的入口,再对每个实例分别启动slave。这时候每个slave在启动的时候资源已经固定了。再增加资源的时候需要启动新的slave然后停止之前的任务修改资源配置数重发,这种模式的好处是有一个单独的界面,你可以直接给业务线这个独立集群模式的界面来用,界面上他们可以根据自己固定的资源发多个任务,并且在SparkUI上可以直接看到日志。另外它是预先占资源模式,在发布时不会有资源争抢导致资源不够的情况,但是缺点就是做不到运行时的动态扩容。
仿mesos-dispacher模式
该模式下,我们使用Marathon这个framework来模仿mesos-dispacher所做的事,就是先发一个driver然后再发executor挂载到driver来执行任务。关于日志,我们还是使用之前的方式调用Mesos的接口来获得日志。当需要增加资源的时候直接往结点继续挂executor就可以,当需要删除结点的时候直接停止executor即可。
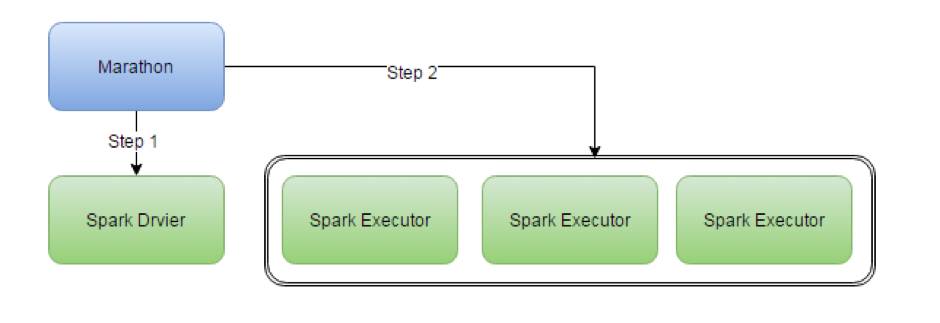
(图4)仿mesos-dispacher模式
如何实现仿mesos-dispacher模式
我们要做的事实际上是把图2的架构图变成图4的模式,其中Step
1和Step 2需要模仿,而Step 0则不需要,因为Step
0只是启动Framework的。我们通过观察meos-dispacher发现Step 1所做的实际上是调用Spark
Submit向Mesos注册一个Framework然后再由driver来负责调度,我们利用mesos的constraints的特性,设置一个不存在的不可调度的策略,例如:colo:none,这样一来driver就无法管理资源,而我们使用Marathon自己来发布Spark
Executor来挂到driver上来实现Marathon控制Spark的资源调度策略。由于Mesos他是把Offer推送给Framework的这一特性,我们使用的这种方式也不会有性能问题。





