选自research.facebook
作者:Julie Schiller 等
机器之心编译
参与:吴攀、微胖、曹瑞、黄小天
Automatic Alt-Text 服务让盲人可以更好地理解他们的动态消息(News Feeds)中的照片。用户通过采访、可用性测试和调查等研究而协助了对这一工具的开发。
如果你对这项成果感兴趣,可在本周在波特兰的 CSCW 2017 上与相关开发者联系讨论,本研究的主要作者、数据科学家 Shaomei Wu 将会在会上呈现相关的研究细节。此外,机器之心还曾编译过 Facebook 官方发布的另一篇相关的技术解读文章《深度 | 详解 Facebook 全新图像识别系统:无需依赖标记的自由搜索》。
背景
你也知道,你的 Facebook 动态消息常常排满了你的好友分享的图片和视频。手机上高品质相机越普及,人们分享的图片和视频就会越多。能够观看和讨论视觉媒体的内容一直是 Facebook 的一个关键组成。实际上,每天在 Facebook、Instagram、Messenger 和 WhatsApp 上分享的照片多达 20 亿张。听起来很赞吧?但并不是每个人都会这样想。对于那些有视觉障碍(比如:失明)的人来说,他们很难围绕一张图片来展开对话。
Facebook 的使命是创造一个更加开放和互联的世界,并赋予人们分享的能力。在整个世界,有大约 3900 万人是盲人,有超过 2.46 亿人有严重的视觉障碍。据报道,因为他们无法充分地参与到围绕图片和视频的对话中,他们会产生沮丧感和疏离感和被孤立排斥的感觉。为了让更多人参与到查看照片方面的社交活动中,Facebook 推出了 Automatic Alt-Text(AAT),让屏幕阅读器的用户也能够理解其动态消息中的大多数照片的内容(期待很快就能阅读所有照片)。
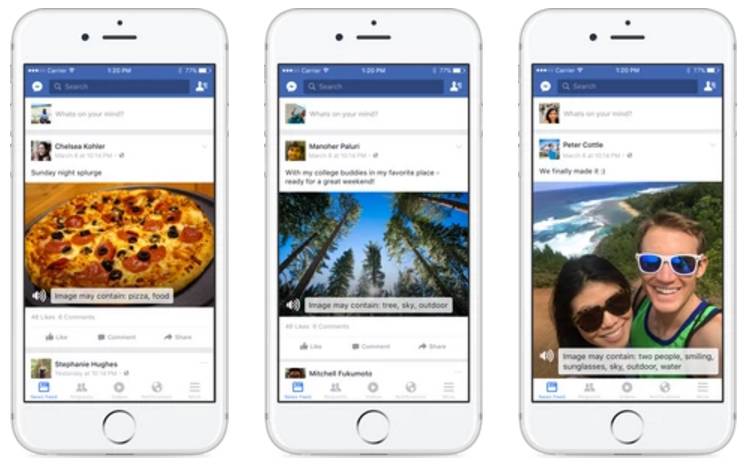
过去是什么,现在又怎样?
应该从哪里开始来解决这个难题?对于这个计算机视觉模型之下 AAT 和 Lumos 技术的创造请参阅《深度 | 详解 Facebook 全新图像识别系统:无需依赖标记的自由搜索》。本文我们将关注我们如何通过与盲人用户合作来为他们创造出色的用户体验。
从之前的研究中我们了解到,一些服务会使用定制化的服务(或使用好朋友)来描述照片,用户需要为每一张想要了解的照片提出请求。不幸的是,这种方法存在一些问题:
速度太慢
需要其他人在场,而且他愿意接受这个任务
会打断使用动态消息的流动性
可能最重要的:难以大规模应用
然而,这种方式也有好的一面。一位朋友或一位代表为你翻译照片的准确度是非常高的。朋友还能根据你们的关系给出额外的语境信息(比如,增加描述的色彩或说一个你们才懂的笑话)。但是这种解决方案能够在扩展的同时还能避免那些缺陷吗?我们的目标是创造一种新的 Facebook 功能,使其成为这类思想的下一代革命。
AAT 项目的目标是以一种大规模、无延迟的方式来通过算法生成有用且准确的照片描述。我们以 image alt-text 的方式提供这些描述,这是一种为文本替代图像的内容管理而设计的 HTML 属性。因为 alt-text 是 W3C 可访问性标准的一部分,所以当人们将任何屏幕阅读器软件上的阅读光标移动到一张图像上时,该阅读器就可以抓取其 alt-text 然后将其朗读出来。
研究
为了构建一个可扩展的人工智能系统,我们用了 10 个月的时间完成了 2 种类型的研究。我们在 Shaomei Wu 设计的原型上进行了定性调查和可用性测试。这些定性环节有助于找出这种系统的关键问题,从而让我们可以进行一些修改,得到让人惊喜和感激的结果,而不是最终让人失望和困惑。我们用于确定我们的发现的另一个方法是推出一个实验性版本,告知人们我们会为他们发布一些实验性的功能,然后对他们进行一些和没有使用这些实验功能的用户(我们的对照组)一样的调查。这两组都来自于 VoiceOver Facebook iOS 用户。
访谈 & 可用性测试
正如我们在这个过程中了解到的一样,最大的难题是在人们想要了解其消息流中关于图像的更多信息的愿望与这些信息的质量和社会智能之间找到平衡。对视觉内容的解读可能是非常主观的,而且可以也很依赖于语境。比如说,尽管人们基本上关心的是照片中有什么人以及他们在做什么事,但有时候关于这张照片的背景才是有意思的或重要的。对于我们最终组织读给人们听的句子方面,这是一个关键的发现。
此外,让人来寻找一张照片中最有意思的地方是一个相当微不足道的任务,但对机器而言,即使最智能的人工智能也会感到相当困难。想让这项服务的体验优质,必须要了解照片的社会背景以及确定合适的反馈量,我们希望最终能达成这一目标!根据我们的访谈,我们发现比起丢下我们不确定的项不管,给出图片的错误信息实际上会更加糟糕。比如说,如果该服务说一张照片中有一个小孩,而实际上那却是一个个子很小的女子。我们也思考了其它公司的人工智能系统出现严重错误的地方,比如误将人类识别为动物,这可能会导致所有人都不愿看到的情况。如果该用户不知道该朋友没有孩子,那么他就可能会给出会导致难堪和社交尴尬的评论。在与开发团队的合作中,我们一直牢记这一点,并对我们要创造的系统有以下要求:
能大规模地识别内容
能从照片中选取用户感兴趣的概念和事物
能为用户提供有意义的反馈
能提供无缝交互的感觉
在定性环节,最后一个大的教训就是:在人工智能确定图片中的内容时,不要谈论把握有多大,这很重要。从参与者那里,我们得知这会让系统感觉起来像机器人或者不吉利。还会慢慢让用户不信任该系统。这里,我们做出了修改,让系统可以对图片中的内容达到极度确信状态(高于某个人工智能准确度阈值标准)。我们也很快去除了复述人工智能评级的确定性(用来确定每个图片中的内容)的机器人特性。尽管将准确性的指标抬得更高了,但是,在识别所有传到 Facebook 中的图片中的某个内容时,准确率也仅是超过 50%。这个数字会随着技术的不断改进而日趋增高。
总之,在参与者们的非常有用的帮助下,关于如何采访那些想要分享一些定性研究小技巧的盲人,我们学习到了很多。
一个简单的经验就是要有盲人参与者携带他们自己的设备。这会让他们在研究中感觉更加舒服自然(在对任何参与者来说这都是非常好的一个技巧),但同时也要允许他们对他们自己携带的辅助设备进行预配置。
另一个技巧是让屏幕阅读器的使用者将语速调慢一点,这样你就能跟着进行出声思考。用很多的方式进行出声思考是参与者将屏幕阅读器中的读出的东西解释出来的方法。如果你跟不上这两者(参与者和阅读器的声音),就会丢失一半的数据。在你开始之前,就尝试使用屏幕阅读器,这样你才能成为一名更加高效的主持。
最后,一些研究人员表示,仅仅是招募屏幕阅读器用户就很难,因为很多 UX Recruiters 并不熟悉这一类人群。我们发现和宣传组织(advocacy groups,比如,Lighthouse)合作或者联系专门的招募单位寻找参与者是很有效的。
调查
在深度定性理解的帮助下,我们为了描绘一个更全、更泛化的 AAT 使用反馈而转向了调查。我们调查了 550 名具有轻度视觉损害或全盲的参与者。如上所述,我们收到了来自控制组(通常是 Facebook)或 AAT(实验组)的更新版本的 Facebook 的反馈,总样本大约 9000。参与者填写了几乎相同的调查,调查涉及了很多问题,唯一区别是如果参与者来自实验组,有几个问题是专门为 AAT 准备的。参与者还有机会参加抽奖活动并获得一张价值 100 美元的亚马逊礼物卡。与任何调查书写一样,针对目标受访者创建最为简洁、易于理解的调查至关重要。我们就创建针对盲人用户的调查提出了一些实际的建议:
避免使用横向单选按钮,以及拖/放问题。前者比垂直选项更难以分页,后者则对屏幕使用者来说根本不可能。
避免使用矩阵和星级评分问题,前者不总是在 HTML 旁边被正确标记,使得在矩阵中识别应答者变的不可能;后者应该被替换为非图形 HTML 元素以使不同的屏幕阅读器可以更通用地访问。
为屏幕阅读器用户提供返回功能,因为无意的错误会更频繁地发生。
做一项关于屏幕阅读器的调查比调查一个视力正常的用户通过鼠标使用 OS 更费时一点。
如果屏幕阅读器用户响应你的调查对你来说很重要,那么让屏幕阅读器的用户首先进行导航,这可能很重要。
与传统的优秀调查设计一样,尽量在每页之中仅包含少量问题,以避免出现认知复杂化和导航问题。
使用间距,确保单选按钮和复选框与其标签清楚相关,以防止模糊和混乱。
首字母缩略词和缩写在调查中很常见。然而并不是所有的受访者都会熟悉或记住它们,屏幕阅读器可能难以读出首字母缩略词和缩写。虽然「acronym」和「abbr」标签可以缓解这一点,并且「标题」属性可以在需要时提供进一步的信息。
调查/试验发现:亮点
测试组中的人对该 AAT 功能评价不错。这是通过与没有开启这一功能的控制组的比较而得出的结论。总体而言,测试组的参与者更有可能做以下事情:
来自调查的样本问题:
我们让 AAT 用户确认在动态消息中一旦点击了一张图片是否会听到一句话。如果他们确实听到了以「图片可能包含…」开始的一句话,接着我们会问一些问题。
问题:(如果在测试组)听到这个替换文本你有什么感受(检查所有使用)?
测试组中的受访者被展示了一个随机分类的词集帮助他们描述听到图片之中的替换文本的感受。我们还启用了其他方法帮助受访者写下他们的想法。根据调查结果,我们发现受访者更强调积极词汇:快乐(29%)、惊喜(26%)和印象深刻(25%)分别排在前三名。
问题:回想一下动态消息中你还记得的最后几张照片,以回答这个页面上的问题。对于那些照片,描述照片关于什么的难/易程度是多少?
「还算容易」与「很难」的答案有很大不同,前者是 23% 与 2%,后者是 42% 与 73%。这表明 AAT 提供了额外价值。

接下来呢?
这项研究还处在婴儿期,有关改善建议主要关注以下两类问题:
其它要求包括扩大该算法的词汇,增加既有标签的重新调用,可以在更多语言以及平台语境下用到 AAT 等。
原文链接:https://research.fb.com/accessibility-research-developing-automatic-alt-text-for-facebook-screen-reader-users/
©本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]









