加入雷锋网,分享AI时代的信息红利,与智能未来同行。听说牛人都
点了这里
。
如果横向对比语音和视觉两种技术,大多数人可能会直观地认为视觉是比语音更复杂的一种技术,但事实真是如此吗?
在17日举办的中国人工智能产业大会上,思必驰首席科学家、“思必驰-上海交大智能人机交互联合实验室”主任、上海交通大学计算机教授俞凯博士在接受雷锋网采访时表示,“语音和视觉是两种不同的模态,前者是一维信号,后者是二维信号,视觉的帧率比语音低很多,因为视觉可能是一张图片或者是视频,视频一秒24帧,而语音1秒钟100帧就能听出来差别,所以从实时性来看,语音的难度要高于视觉,但是从本身处理的信息量来讲,视觉则会难于语音。”
当然语音交互涉及到的问题不仅如此,它所做的不仅仅是语音识别。
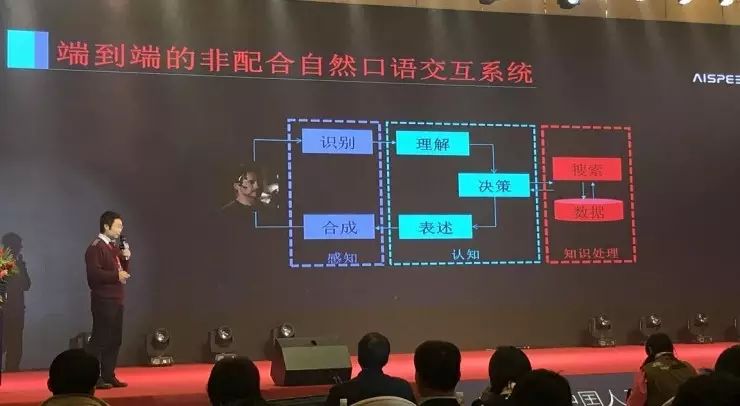
语音识别属于感知层,而感知只是语音交互的一部分
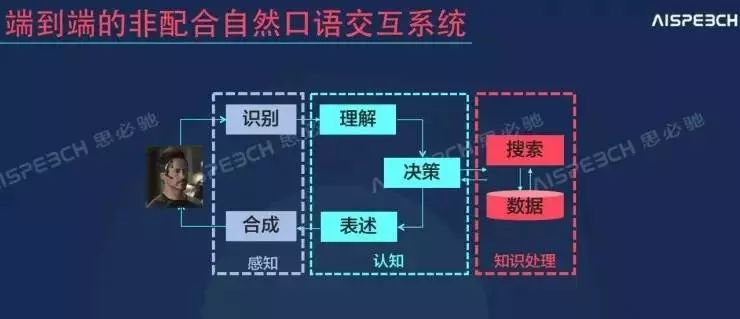
从上图来看,一个端到端的语音交互方案包括了感知、认知和知识处理三个部分。俞凯表示,“识别和合成都属于感知范畴,这部分的目的是把语音信号转为编码文字,在后端需要对转成的编码文字进行相应的理解决策以及相关的表述,这是认知。”如何把感知和认知连接起来是一个问题,也是目前思必驰正在做的一件事情。
如果只看感知和认知部分,大数据和深度学习无疑是最核心的两个因素。
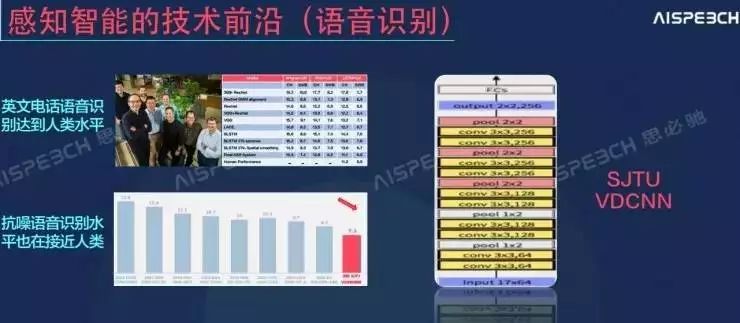
俞凯举了两个例子:
不久前,微软研究院发布的最新的语音识别测试结果显示,电话语音在语音识别的测试当中已经达到了人类的水平(上图左上角),人类的水平是在5.9,而这次测试的数据达到了5.8。俞凯指出,语音识别能够达到这一水平的关键就是大幅度的计算。
第二个例子是上图左下角展示的结果,这是思必驰利用极深的神经网络在一组抗噪的语音识别上做的测试,测试结果是7.1,这是一个什么样的概念?
俞凯解释,在深度学习产生之前,全世界最好的结果是13.4,深度学习产生之后这一数值降到了12,而7.1是目前最好的结果,如果做到5以下,就达到了人类水平,事实上,在一些特定场景下,结合深度学习以及大数据的技术已经可以达到人的水平。因此,大数据和深度学习对人工智能的意义是显而易见的。

但俞凯强调,站在学术界和产业界的角度看,感知层并不是最高深的问题,远场和外噪声环境下的语音识别、非配合式的语音交互这些问题学术界和从业者进一步深入研究就可以解决。
认知问题,是深度学习和大数据组合之外,业界需要探索的方向。
“认知的难点在于你并不知道什么是好的什么是坏的,我们很难去理解在什么程度上是好的,交互决策用什么精确的指标来客观的衡量它,现在有很多不同的指标提出来,所以在学术界和产业界都会存在很大的难点。”
认知计算是什么?
如果在网上查阅资料,你会发现认知计算算不上高频词,至少相比深度学习,认知计算在业界的热度还没那么高,俞凯坦言,关于认知计算业界目前还没有一个统一的定义。
那么它和深度学习相比有什么特点?
俞凯向雷锋网解释道,“深度学习是一种方法,我们可以把它用在人工智能和控制上,它解决的是输入和输出之间的映射(算法),例如输入语音,输出的是文字;而认知计算解决的是理解、反馈和学习问题,它对应于人脑当中比较抽象的推理部分,认知的输入和输出都不明确。”

它用坐标描述了语音交互在认知计算上的分类。按照对话的应用场景来看,以轮回的次数作为横坐标,结构的引进程度作为纵轴,我们就可以在坐标的象限里分成四个部分(如上图):命令式、问答式、闲聊式和任务式四种场景。可以看出,命令式的交互和闲聊式的交互本质上都没有引进绝对的结构化信息,命令相对简单,闲聊会更复杂,而问答和任务这两种交互场景是目前应用得比较多的类型。

再来看看认知计算涉及到的技术,它包括深度(序列)学习、知识与数据双轮驱动以及强化学习。
1.深度学习带动了包括语音识别、对话交互在内的技术进步,而在认知系统里,最大的进步还是深度序列学习,即把整个文字序列看成学习目标。
2.知识与数据双轮驱动的应用越来越多,这其中出现了很多基于规则和统计混合的新的技术。
3.强化学习在AlphaGo之后被广泛关注,其在对话交互当中已经成为最前沿的一种方式,现在深度Q网络也已经被广泛应用起来了。
认知计算需要解决大数据和深度学习之外的问题

俞凯认为,深度学习和大数据是基础,但它们并不是万能的,认知计算需要解决的就是深度学习和大数据不能解决的问题。例如,一个方言识别器准确率即便达到了95%以上也不代表就有了好的交互体验,这涉及到的是深度学习和大数据之外的问题。
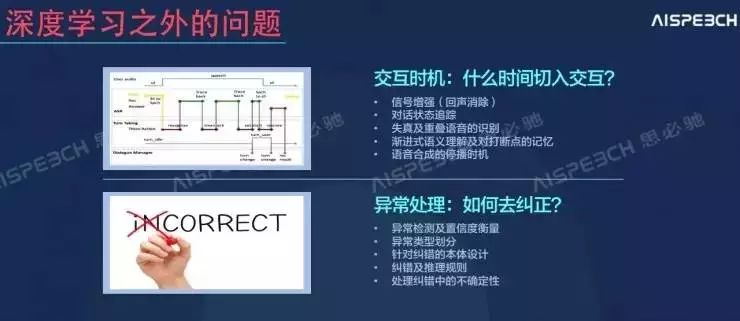
首先,在深度学习之外,有两个需要解决的问题:交互时机和异常处理。交互时机是指在对的时间切入交互,这里面包含了信号增强、对话状态追踪、失真及重叠语音的识别等任务;异常处理就是要知道如何去纠正,这其中的问题有异常检测及置信度衡量、异常类型划分等等。
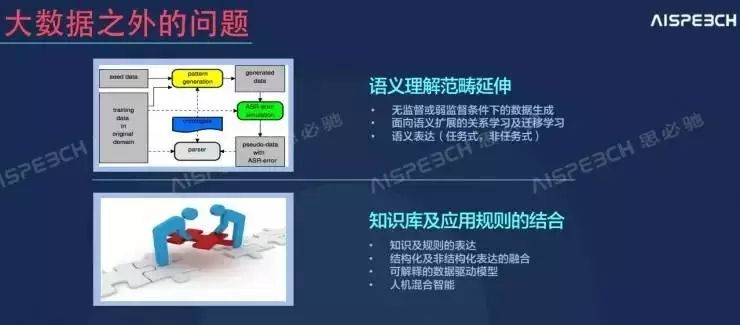
除此之外,俞凯还介绍,大数据之外也涉及到了两个问题,即语义理解范畴延伸、知识库和应用规划的结合,这些都不是通过收集到的原始大数据就能解决的,它们都需要加入很多算法。
一言以蔽之,认知计算需要解决上述问题才能够在用户层面有好的交互体验。
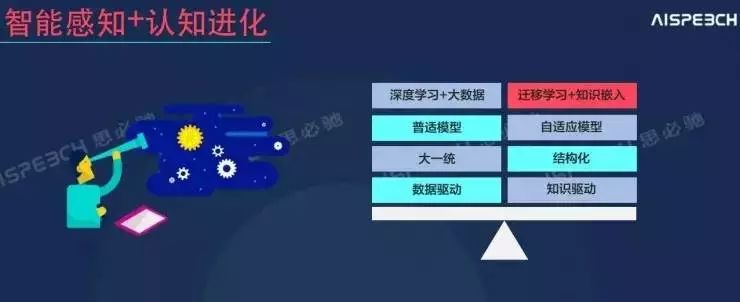
“我们会看到大数据和深度学习对普适模型以及大一统方案上将有很大的进步,但是真正实际使用过程中,要一些新型技术结合进去才有可能解决,科学上的进步往往是从产业上的问题作为入手点,而提出的解决方案可能会超越大家现在的想象。”俞凯如此表示。言下之意,至少在语音交互上,产业界还存在很多问题亟待解决。
但我们对未来还是要保持乐观的心态,随着技术问题的进一步解决,语音交互领域未来会产生一些新的商业模式。俞凯告诉雷锋网,预计明年将会有很多专业领域提供语音识别服务的公司会涌现出来,如医疗、金融和教育等领域,这些都需要专业的人来做数据模型,他们只需要用一套标准化的方案就可以实现应用。换言之,虽然未来可能很难再有类似思必驰这些向第三方提供lisense的平台型的公司出现,但创业企业可以从这些平台公司获取基础技术,再根据细分行业的具体需求来形成应用,这是语音交互产业的未来一个发展方向。






