
原文来源
:
GitHub
「机器人圈」编译:
嗯~阿童木呀、多啦A亮
 Tensorflow
Tensorflow
主要特征和改进
•在Tensorflow库中添加封装评估量。所添加的评估量列表如下:
1.
深度神经网络分类器(DNN Classifier)
2.
深度神经网络回归量(DNN Regressor)
3.
线性分类器(Linear Classifier)
4.
线性回归量(Linea rRegressor)
5.
深度神经网络线性组合分类器(DNN Linear Combined Classifier)
6.
深度神经网络线性组合回归量(DNN Linear Combined Regressor)
•我们所有预构建的二进制文件都是用cuDNN 6构建的。
•import tensorflow现在运行要快得多。
•将文件缓存添加到GCS文件系统中,其中文件内容具有可配置的最大失效期(configurable max staleness)。这允许跨关闭/开放边界缓存文件内容。
•将轴参数(axis parameter)添加到tf.gather中。
•向tf.pad中添加一个constant_values关键字参数。
•添加Dataset.interleave转换。
•添加ConcatenateDataset以连接两个数据集。
•在TensorFlow中为Poets训练脚本添加Mobilenet 的支持。
•将块缓存添加到具有可配置块大小和计数的GCS文件系统中。
•添加SinhArcSinh Bijector。
•添加Dataset.list_files API。
•为云TPU引进新的操作和Python绑定。
•添加与tensorflow-android相对称的TensorFlow-iOS CocoaPod。
•引入集群解析器(Cluster Resolver)的基本实现。
•统一TensorShape和PartialTensorShape的内存表示。因此,张量现在最多有254个维度,而不是255个。
•更改对LIBXSMM的引用版本,使用1.8.1版本。
•TensorFlow调试器(tfdbg):
1.
使用-s标志显示数字张量值的概要,用命令print_tensor或pt。
2.
使用curses UI中的print_feed或pf命令和可点击链接显示Feed值。
3.
op级别和Python源代码行级别的运行分析器(Runtime profiler)使用run -p命令。
•统计分布库tf.distributions的初始版本。
•一元tf.where和tf.nn.top_k的GPU内核和速度改进。
•将单调注意包装器(Monotonic Attention wrappers)添加到tf.contrib.seq2seq。
•添加tf.contrib.signal,一个用于信号处理原语的库。
•添加tf.contrib.resampler,它包含CPU和GPU操作,用于区分图像的重采样。
API的突破性更改
•当tf.RewriterConfig在1.2版本的候选版本中可用(它从来没有在实际版本中应用)后将其从Python API中删除,图重写(Graph rewriting)仍然可用,只是不像tf.RewriterConfig那样。而是添加显式导入。
•打破对tf.contrib.data.Dataset API期望有一个嵌套结构的更改。列表现在被隐式转换为tf.Tensor。你可能需要在现有代码中将列表的用法更改为元组。此外,现在还支持程序具有嵌套结构。
contrib API的更改
•添加tf.contrib.nn.rank_sampled_softmax_loss,这是一个可以提高秩损失(rank loss)的采样softmax变体。
•当他们看到小于或等于1个单位的权重时,tf.contrib.metrics {streaming_covariance,streaming_pearson_correlation}修改为返回nan。
•在contrib中添加时间序列模型。有关详细信息,请参阅contrib / timeseries / README.md。
•在tensorflow / contrib / lite / schema.fbs中添加FULLY_CONNECTED操作。
错误修正以及其他更改
•在python中使用int64 Tensor index进行切片时,修复strides和begin 类型失配问题。
•改进卷积padding文件。
•添加标签常量,gpu,以显示基于GPU支持的图形。
•saved_model.utils现在显然是支持SparseTensors的。
•非最大抑制(non-max suppression)更为有效的实现。
•除了对在线L2的支持之外,还增加了对从收缩型L2到FtrlOptimizer的支持。
•固定矩计算中的负方差。
•拓展UniqueOp基准测试,以涵盖更多的collision案例。
•提高Mac上GCS文件系统的稳定性。
•在HloCostAnalysis中添加时间评估。
•修复Estimator中的错误,即构造函数中的参数不是对用户提供参数的深度复制。这个错误无意中使得用户在创建Estimator之后突变参数,从而导致潜在的未定义的行为。
•在saver.restore中添加了无检查保存路径。
•在device_mgr中以旧名称注册设备,以便轻松转换到集群规范传播(cluster spec-propagated)的配置。
•将向量指数添加到分布中。
•添加一个具有bitwise_and,bitwise_or,bitwise_xor和invert函数的按位模块(bitwise module)。
•添加固定网格的ODE集成例程。
•允许将边界传递到scipy最优化接口。
•将fft_length参数修正为tf.spectral.rfft&tf.spectral.irfft。
•使用“预测”方法导出的模型签名将不再使其输入和输出密钥被静默地忽略,且被重写为“输入”和“输出”。如果一个模型在1.2版本之前以不同的名称导出,并且现在使用tensorflow / serving,它将接受使用'inputs'和'outputs'的请求。从1.2版本开始,这样的模型将接受导出时指定的密钥。因此,使用“输入”和“输出”的推理请求可能会开始有所失败。为了解决这个问题,请更新任何推理客户端,以发送具有训练器代码所使用的实际输入和输出密钥的请求,或者相反地,更新训练器代码以分别命名输入和输出张量为'inputs'和 'outputs'。使用“分类”和“回归”方法的签名不会受此更改的影响;它们将继续像以前一样规范其输入和输出键。
•将内存中的缓存添加到Dataset API中。
•将数据集迭代器中的默认end_of_sequence变量设置为false。
• [Performance]通过使用nn.bias_add将use_bias = True设置为2x,可以提高tf.layers.con2d的性能。
•更新iOS示例以使用CocoaPods,并移动到tensorflow / examples / ios中。
•在tf.summary操作中添加一个family =attribute,以允许控制Tensorboard中用于组织摘要的选项卡名称。
•当配置GPU时,如果在configure脚本中存在请求,则可根据请求自动构建GPU,而不需要--config = cuda。
•修复CPU / GPU多项式中小概率的不正确采样。
•在session上添加一个list_devices()API以列出集群中的设备。此外,此更改增加了设备列表中的主要API以支持指定session。
•允许使用过参数化的可分离卷积。
•TensorForest多重回归错误修复。
•框架现在支持armv7,cocoapods.org现在可显示正确的页面。
•为CocoaPods创建iOS框架的脚本。
•现在,TensorFlow的Android版本已经被推到了jcenter,以便更方便地集成到应用中。有关详细信息,请参阅
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/android/README.md
。
•TensorFlow调试器(tfdbg):
1.修复了一个阻止tfdbg使用多GPU设置的错误。
2.修复了一个阻止tfdbg使用tf.Session.make_callable的错误。
资源下载:
源代码(zip)
https://github.com/tensorflow/tensorflow/archive/v1.3.0-rc2.zip
。
源代码(tar.gz)
https://github.com/tensorflow/tensorflow/archive/v1.3.0-rc2.tar.gz
。
Pytorch0.2.0
这里是PyTorch的下一个主要版本,恰恰赶上了国际机器学习大会(ICML)。今天开始可以从我们的网站
http://pytorch.org
下载安装。
此版本的软件包文档可从
http://pytorch.org/docs/0.2.0/
获取
我们引入了期待已久的功能,如广播、高级索引、高阶梯度梯度,最后是分布式PyTorch。
由于引入了广播,某些可广播情况的代码行为与0.1.12中的行为不同。这可能会导致你现有代码中出现错误。我们在“重要破损和解决方法”部分中提供了轻松识别此模糊代码的方法。
目录:
•张量广播(numpy样式)
•张量和变量的高级索引
•高阶梯度
•分布式PyTorch(多节点训练等)
•神经网络层和特征:SpatialTransformers、WeightNorm、EmbeddingBag等
•torch 和 autograd的新应用:矩阵相乘、逆矩阵等
•更容易调试,更好的错误信息
•Bug修复
•重要的破损和解决方法
张量广播(numpy样式)
简而言之,如果PyTorch操作支持广播,则其张量参数可以自动扩展为相同大小(不复制数据)。
PyTorch广播语义密切跟随numpy式广播。如果你熟悉数字广播,可以按照之前流程执行。
一般语义学
如果以下规则成立,则两个张量是“可广播的”:
•每个张量具有至少一个维度。
•当从尺寸大小开始迭代时,从尾部维度开始,尺寸大小必须相等,其中一个为1,或其中一个不存在。
例如:

如果两个张量x、y是“可广播”的,则所得到的张量大小计算如下:
•如果x和y的维数不相等,则将尺寸缩小到尺寸较小的张量的前端,以使其长度相等。
•然后,对于每个维度大小,生成的维度大小是沿该维度的x和y的大小的最大值。
例如:
# can line up trailing dimensions to make reading easier
>>> x=torch.FloatTensor(5,1,4,1)
>>> y=torch.FloatTensor( 3,1,1)
>>> (x+y).size()
torch.Size([5, 3, 4, 1])
# error case
>>> x=torch.FloatTensor(5,2,4,1)
>>> y=torch.FloatTensor( 3,1,1)
>>> (x+y).size()
RuntimeError: The size of tensor a (2) must match the size of tensor b (3) at non-singleton dimension 1
更多细节可以在
PyTorch文档网站上
找到。此外,每个torch函数列出了其文档中的广播语义。
张量和变量的高级索引
PyTorch现在支持NumPy样式的高级索引的子集。这允许用户使用相同的[]-样式操作在Tensor的每个维度上选择任意索引,包括不相邻的索引和重复的索引。这使得索引策略更灵活,而不需要调用PyTorch的索引[Select, Add, ...]函数。
我们来看一些例子:
x = torch.Tensor(5, 5, 5)
纯整数组索引—在每个维度上指定任意索引
x[[1, 2], [3, 2], [1, 0]]
--> yields a 2-element Tensor (x[1][3][1], x[2][2][0])
也支持广播、副本
x[[2, 3, 2], [0], [1]]
--> yields a 3-element Tensor (x[2][0][1], x[3][0][1], x[2][0][1])
允许任意索引器形状
x[[[1, 0], [0, 1]], [0], [1]].shape
--> yields a 2x2 Tensor [[x[1][0][1], x[0][0][1]],
[x[0][0][1], x[1][0][1]]]
可以使用冒号、省略号
x[[0, 3], :, :]
x[[0, 3], ...]
--> both yield a 2x5x5 Tensor [x[0], x[3]]
也可以使用张量来索引!
y = torch.LongTensor([0, 2, 4])
x[y, :, :]
--> yields a 3x5x5 Tensor [x[0], x[2], x[4]]
如果选择小于ndim,请注意使用逗号
x[[1, 3], ]
--> yields a 2x5x5 Tensor [x[1], x[3]]
高阶梯度
现在你可以评估PyTorch中的高阶微分。例如,你可以计算Hessian-Vector,惩罚你的模型的梯度梯度的范数,实施unrolled GAN和改良WGAN等。
在0.2版本中,我们已经能够为torch.XXX函数和最流行的nn层计算更高阶的梯度。其余的将出现在下一个版本中。
这是一个简短的例子,惩罚了Resnet-18模型的权重梯度的范数,使权重的数量变化缓慢。

我们在这里看到两个新概念:
•
torch.autograd.grad
是一个输入[输出,输入列表(你需要梯度)]的函数,并返回梯度wrt。这些输入作为元组,而不是将梯度累加到.grad属性中。如果你想进一步操作梯度,这对你会很有用。
•你可以对梯度进行操作,并向后调用()。
支持更高阶梯度的nn层的列表有:
•
AvgPool*d, BatchNorm*d, Conv*d, MaxPool1d,2d, Linear, Bilinear。
•
pad, ConstantPad2d, ZeroPad2d, LPPool2d, PixelShuffle。
•
ReLU6, LeakyReLU, PReLU, Tanh, Tanhshrink, Threshold, Sigmoid, HardTanh, ELU,Softsign, SeLU。
•
L1Loss, NLLLoss, PoissonNLLLoss, LogSoftmax, Softmax2d。
其余的将在下一个版本中启用。
为了实现更高阶的梯度,我们引入了一种新的autograd.Function写入格式。(写入函数的当前/旧样式完全向后兼容)。你可以点击
此处链接
阅读更多关于新样式的函数。
大多数人不写自己的autograd.Function,它们是低级基元使得autograd引擎完成新操作,你可以指定正向和反向调用。
分布式PyTorch
我们介绍
torch.distributed包
,允许你在多台机器之间交换张量。使用此软件包,你可以通过多台机器和更大的小批量扩展网络训练。例如,你将能够实现
《Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour》
这篇论文。
distributed软件包遵循MPI风格的编程模型。这意味着你可以得到很多函数,如send,recv,all_reduce,它将在节点(机器)之间交换张量。
对于每个机器,首先识别彼此并分配唯一的数字(等级),我们提供简单的初始化方法:
•共享文件系统(要求所有进程可以访问单个文件系统)
•IP组播(要求所有进程都在同一个网络中)
•环境变量(需要你手动分配等级并知道所有进程可访问节点的地址)
我们的包文档中包含有关初始化和可用后端的更多详细信息,但以下是使用多播地址进行初始化的示例:
mport torch.distributed as dist
dist.init_process_group(backend='tcp',
init_method='tcp://[ff15:1e18:5d4c:4cf0:d02d:b659:53ba:b0a7]:23456',
world_size=4)
print('Hello from process {} (out of {})!'.format(
dist.get_rank(), dist.get_world_size()))
这将在第3台机器上打印Hello from process 2 (out of 4)。
world大小是参与工作的过程的数量。每个将被分配一个等级,它是0和world_size-1之间的数字,在此作业中是唯一的。它将用作进程标识符,并且将被代替地址使用,例如,指定张量应被发送到哪个进程。
这是一个代码段,显示如何执行简单的点对点通信:
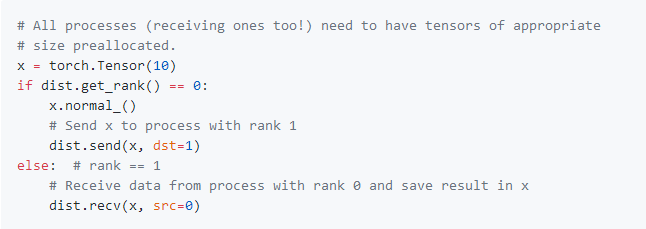
异步p2p函数(isend,irecv)也可用。
然而,一些通信模式出现频繁,导致已经开发出更有效的集体调用。他们通常参与整个过程组,并且比使用send / recv的单纯算法要快得多。一个例子是all_reduce:

分布式软件包是相当低级别的,因此它允许实现更先进的算法,并将代码定制到特定的目的,但数据并行训练是我们为此创建高级辅助工具的常见方法。
因此,我们引入了DistributedDataParallel,这意味着几乎可以替代nn.DataParallel。
以下是一个代码段,展示了将其添加到现有训练代码中所需的更改:
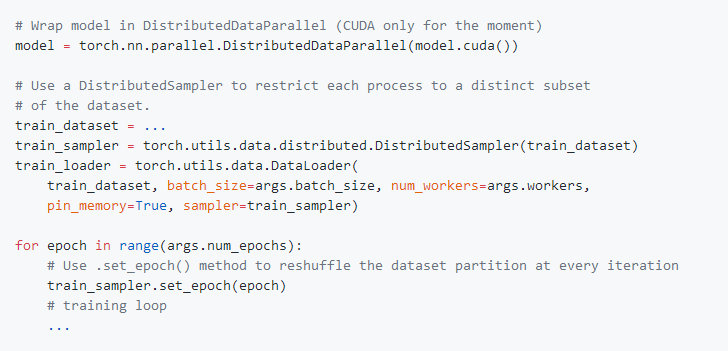
你可以在这里看到更完整的
Imagenet训练示例
新的nn层:SpatialTransformers,WeightNorm,EmbeddingBag等
新功能
•引入forward_pre_hook来在调用forward函数之前执行用户指定的闭包。
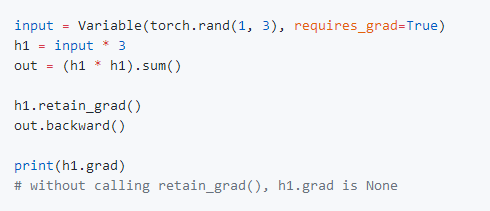
•方便访问非叶梯度(non-leaf gradients):
目前,要访问并检查中间值的梯度,我们必须使用钩(hooks)。这不方便进行简单的检查,因此,我们引入retain_grad。最好通过一个例子来解释:
•DataParallel现在支持dicts作为输入
新图层
•空间变换神经网络通过F.grid_sample和F.affine_grid。
•nn.SeLU和nn.AlphaDropout被引入,论文:
《自标准化神经网络》
。
•nn.GLU(门控线性单元)被引入,论文:
《卷积序列到序列学习》
。
•
权重归一化
现在通过
torch.utils.weight_norm
来实现。
•
现在可以使用ignore_index参数计算cross_entropy_loss和nll_loss来忽略特定的目标索引。这是实现掩码的廉价实用方式,你可以在其中使用在计算损失时忽略的掩码索引。
•F.normalize 实现了按维度的重归一化。
•F.upsample和nn.Upsample将多个Upsampling层合并成一个函数。它实现了2d和3d双线性/三线性/最近的上采样。
•nn.EmbeddingBag:当构建词袋模型时,执行一个Embedding 跟Sum或Mean是很常见的。对于可变长度序列,计算降维包涉及掩码。我们提供了一个单一的nn.EmbeddingBag,它能高效和快速地计算降维包,特别是对于可变长度序列。
•通过bce_with_logits数值稳定的二进制交叉熵损失。
•通过PoissonNLLLoss进行目标泊松分布的负对数似然损失。
•cosine_similarity:返回x1和x2之间的余弦相似度,沿着dim计算。
训练效用
学习率调度程序:
torch.optim.lr_scheduler
提供了几种无声和智能的方法来调整当前的学习率。它们在训练中相当方便,为用户想要做的事情提供方便。
提供各种策略,可以根据适当情况使用,更多可以在
文档包
中阅读:
•ReduceLROnPlateau,LambdaLR,StepLR,MultiStepLR,ExponentialLR
ConcatDataset是一个方便的数据集元类,可以合并和连接两个单独的数据集。
torch 和 autograd的新应用
•所有reduce函数如sum和mean,现在默认压缩缩小的维度。例如,torch.sum(torch.randn(10,20))返回1D Tensor。
•x.shape,类似于numpy。 一个方便的属性,相当于x.size()。
•torch.matmul,类似于np.matmul。
•按位和,或,xor,lshift,rshift。
•autograd支持反向,gesv,cumprod,atan2。
•无偏差的var和std现在可以通过关键字参数选项。
•torch.scatter_add - torch.scatter,除了遇到重复索引时,这些值被求和。
•当没有给出参数时,torch.median的行为类似于torch.sum,即它减小所有尺寸,并返回扁平化Tensor的单个中值。
•masked_copy_已重命名为masked_scatter_(在masked_copy_上已弃用)。
•torch.manual_seed现在也seed所有的CUDA设备。
•你现在可以通过关键字参数torch.rand(1000,generator = gen)指定随机数生成器对象。
错误修复和小改进
现在,当将变量转换为bool时,我们会发出错误。例如:
b = Variable(torch.zeros(1))
if b[0]: # errors now
•在CUDA中解决qr分解中的正确性错误。
•支持IBM PowerPC64平台。
•检查编译时的CuDNN版本是否在运行时是相同的版本。
•改进CUDA分叉子进程中的错误消息。
•在CPU上更快的转置拷贝。
•改进InstanceNorm中的错误消息。
•为各种例程添加更多的参数检查,特别是BatchNorm和Convolution例程。




