暑期Stata培训班招生啦!!!
接力线上的网课培训,我们在今夏又开始新一轮的线下培训啦!
8月4日至12日
,爬虫俱乐部期待与您的相遇!培训具体内容详见推文《
暑期Stata编程技术定制培训班
》。
有问题,不要怕!点击推文底部“
阅读原文
”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱[email protected],我们会及时为您解答哟~
喜大普奔~爬虫俱乐部的github主站正式上线了!我们的网站地址是:
https://stata-club.github.io
,粉丝们可以通过该网站访问过去的推文哟~
好消息
:爬虫俱乐部隆重推出数据定制及处理业务啦,您有任何网页数据获取及处理方面的难题,请发邮件至我们邮箱
[email protected]
,届时会有俱乐部资深高级会员为您排忧解难!

最近武汉的天气“不负众望”,气象台连续发布高温橙色预警,还发短信提醒笔者注意防范,感动感动!但是,在这样“
温暖
”的日子里,笔者防不胜防啊,竟然因为吹空调感冒了!!!(
此处省略一百字的复杂心情描述
)妈妈提醒自己要赶紧喝药,喝药?!拿起药的第一反应竟然是看生产药品的厂家,不求
长生
、但求
多福
啊!炎炎夏日,笔者还要跟着大家一起好好学习python呐~
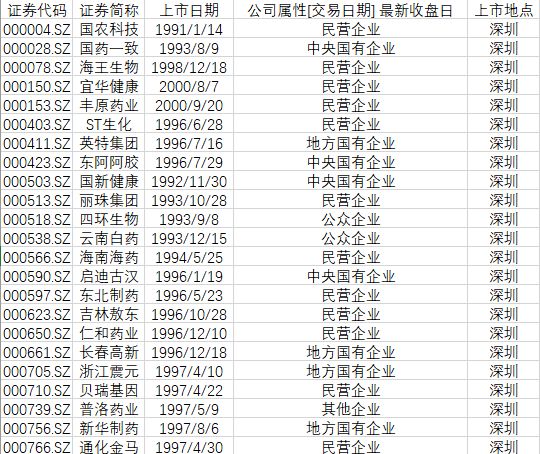
笔者这里有一份申银万国的行业分类下的医药生物行业的
287
家上市公司的相关信息,包括
证券代码
、
证券简称
、
上市日期
、
公司属性
和
上市地点
。笔者想要将这份Excel文件导入到Python中并进行判断处理和输出。
若要实现将Excel文件导入到Python中,也就是在Python中读取Excel文件,这需要借助于
第三方模块
。今天笔者跟大家分享的是
xlrd
和
openpyx
l模块。
在介绍两个模块前,笔者先来问大家一个常识问题:Excel的后缀.xls与.xlsx有什么区别?(此处没有答案,有需要找度娘)在了解了
.xls
与
.xlsx
的区别后,让我们继续往下看吧。
1.xlrd
xlrd
模块下的
open_workbook (filename)
函数可以实现Excel文件的读取,其中Excel文件的版本包括
.xls
和.
xlsx。
在进行文件读取之前,首先需要在Python中安装
xlrd
模块,命令如下:
pip install xlrd
安装完成后,接着在Python中导入
xlrd
模块:
import xlrd
之后我们就可以读取Excel文件了。通过下图我们可以看到这份包含287家医药生物行业上市公司信息的Excel文件的后缀是.xlsx。
现在开始读取这份文件,命令如下:
workbook = xlrd.open_workbook('F:\爬虫俱乐部\爬虫俱乐部微信运营\推文\推文9\SW医药生物.xlsx')

通过控制台界面我们可以看到文件读取正常。我们将文件的后缀名改为
.xls
后文件的读取依然正常。
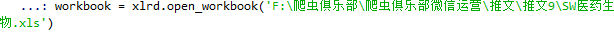
2. openpyxl
openpyxl
模块的功能较多,可实现Excel文件的读取和编写,但不能处理.xls文件。
openpyxl
模块下的
load_work book(filename)
函数可以实现文件的读取。同样,首先我们需要安装
openpyxl
模块,然后在Python中导入模块,接着读取文件。最后的控制台显示读取文件结果正常。
pip install openpyxl(命令提示符环境下)
import openpyxl
workbook = openpyxl.load_workbook('F:\爬虫俱乐部\爬虫俱乐部微信运营\推文\推文9\SW医药生物.xlsx')
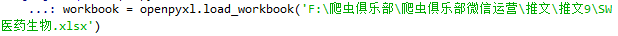
在成功读取Excel文件后,我们就可以进行处理了,比如笔者想实现输入某一股票名称就可以知道它的相关信息的功能应该怎么做呢?
在这里,笔者定义了一个函数
stock_details()
,当运行这个函数时,我们只需要输入相应的证券简称就可以输出股票的相关信息。
首先
,在
输入证券简称
后,这个函数会将证券简称这一列信息转为列表数据,并
遍历所有的证券简称
;
其次
,遍历证券简称这一列列表的元素个数,当证券简称与我们寻找的股票名称
相匹配
时,就
输出
这一行相应的
股票信息
,如果
没有
这只股票的信息,则
没有输出结果
。
def stock_details():
stock = input('Stock:')
for col in list(sheet.columns)[1:2]:
for i in range(len(col)):
if col[i].value == stock :
for row in list(sheet.rows)[i]:
print(row.value,end=" ")
stock_details()
以长生生物为例,我们输入“
ST长生
”,结果如下图所示:
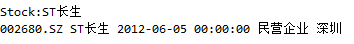
关于Excel文件在Python中修改及输出,我们将在
下一篇
推文中继续探讨。
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~

往期推文推荐:
1.爬虫俱乐部新版块--和我们一起学习Python
2.hello,MySQL--Stata连接MySQL数据库
3.hello,MySQL--odbcload读取MySQL数据
4.再爬俱乐部网站,推文目录大放送!
5.用Stata生成二维码—我的心思你来扫
6.
Mata中的数据导出至Excel
7.
谈谈图形中坐标设置的技巧
8.
如何输出某个关键词在字符串中的所有位置?
9.
想看什么书?Stata君帮你寻!——爬取中南财大图书馆书目信息









