为什么要做秒杀?这个不难解释,最起码对于互联网电商业务来说很常见,那怎么样才能设计出相对比较完善的秒杀策略呢?我觉得这其中有两个关键点:
下面我来谈谈我们的实践。

Web层,主要是APP、HTML 5、PC端的用户流量,目前是7:1:2 流量占比。
反爬和网关是公司层面的用于反爬虫以及网关路由。
Restful API主要是用于收集搜索、产品详情、秒杀信息,用于后端跟前端模板的一个映射。
SecKill API主要是用于访问产品的库存信息以及产品的秒杀信息,独立出秒杀API对原有的产品API下单服务不影响,减少原有系统的耦合。
Booking和Order API我就不分开来讲,当秒杀成功以后用于生成订单。
关于怎么支持高并发有两种策略可以结合,通过前端限流机制只放10%左右的流量到后端,90%的人直接提示秒杀结束,下面我主要是讲讲后端怎么实现。我想Redis大家都用过,其高并发能力超强,理论峰值是单机每秒能支持10万次读写,Redis还可以支持分布式集群扩展性强。还有一点Redis更新操作是原子性的,更新数据是单线程的安全有保证。锁定库存就用Redis来实现,大致的流程如下:
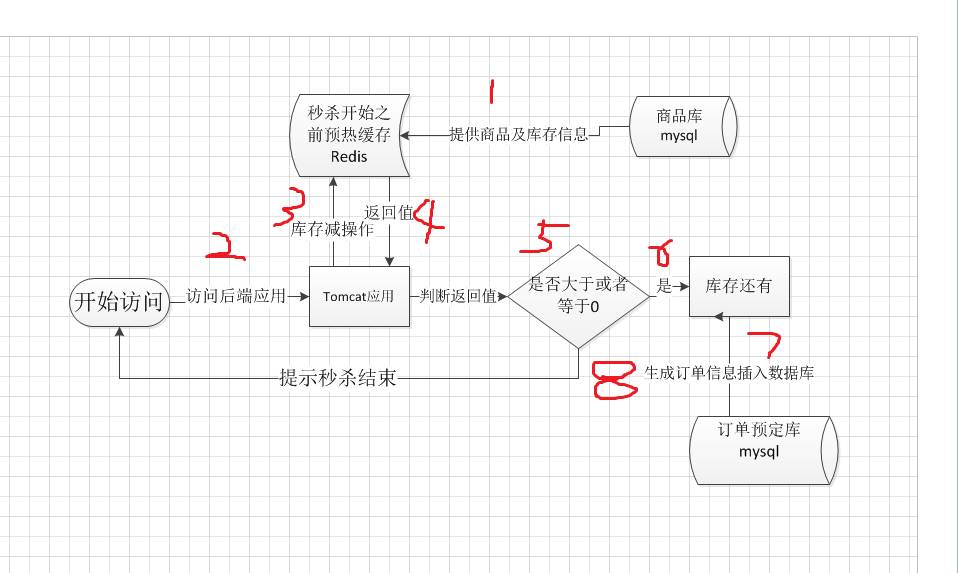
流程梳理
预热缓存,即将产品信息以及库存信息刷新到缓存之中,难道只存这些信息么?这两项是最主要的,其它附加的后面会讲到。
后台应用接收前端的访问,我为什么要明确画出Tomcat容器,这个后续也是也有用的。
通过产品信息为key,去对Redis库存信息执行库存减操作。
有个long型值返回。
判断返回值是否大于或者等于0。
执行到这里说明该用户应该是可以下订单购买的。
直接操作insert DB?没错像订单这么重要的信息,还是应该落库为安。
秒杀商品库存不足,直接返回秒杀结束。
缺陷思考
在缓存预热好,秒杀开始之前有流量进来怎么办?或者秒杀已经库存为0应该结束秒杀怎么办?为了解决这个问题我们应该在步骤1的时候添加秒杀开始和秒杀结束时间,作为操作8开始之前的第一道判断请求。如果在开始之前以及在结束时间之后则直接返回秒杀未开始或者秒杀已经结束。所以更为完善的流程图应该如下:
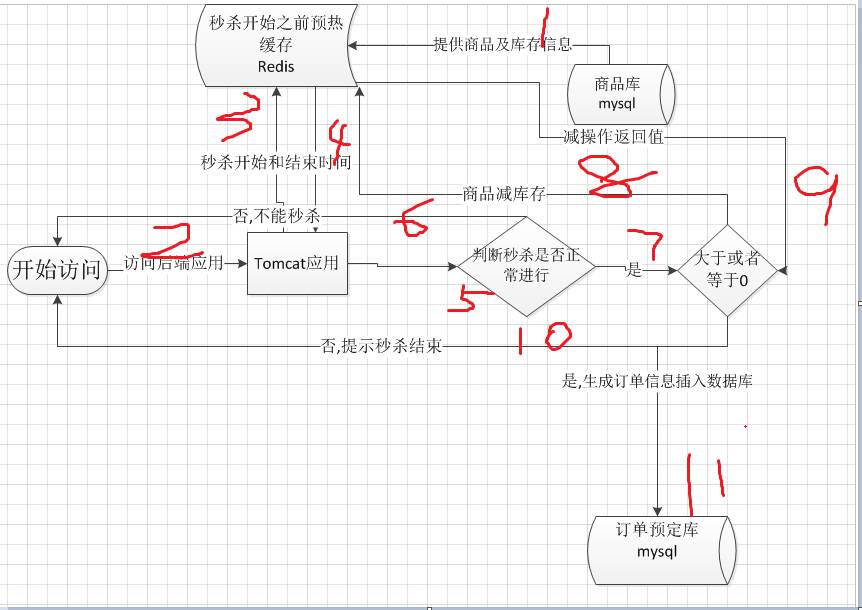
操作11中,得知有库存直接下订单会不会真对数据库造成很大压力呢?肯定会的,所以先期可以减少秒杀的产品数以及库存数量,如果调用订单接口插入订单数据失败,应该释放库存信息,让请求重新可以秒杀产品信息。
如何评估应该部署多少台应用服务器和Redis集群?单台Tomcat容器的每秒访问上限是1000左右,单台Redis机器低估一下每秒也可以抗1万次读写。举例来说,如果秒杀的每秒的访问是1万,部署10台应用服务器,一个Redis集群,2-3台Redis服务器(可写的redis节点)理论就都可以了(这边峰值计算容器级别的Redis级别需要分开来算,因为先需要访问Tomcat应用再去访问Redis,Tomcat也有连接数上限)。当然一个整个流程下来其实是不需要1秒的,大致100毫秒左右,所以理论抗并发峰值应该是可以抗1万 * 10左右。
生产前压力测试
使用JMeter做初期库存数秒杀,看看Redis以及订单接口是否异常或者超时,预估本次活动的访问流量,做上线上的验证。
生产可降级熔断
当瞬间秒杀产品库存太大,造成的Redis写暴增,可能造成线程阻塞最后写超时对于如上的异常,添加一个秒杀开关,大量异常时开关关闭停止一切秒杀活动,以免造成更大的损失。
由于订单还没有做sharding,当每秒写超过单机承受能力甚至影响正常的非秒杀产品下单该怎么办?对于如上的异常添加一个秒杀开关,如果超时或者异常切换到订单临时表中,启用定时任务将订单从临时表数据取出来然后调用下单接口更新到订单库。
监控Redis调用性能,这边主要是看读和写的性能两个指标,看接口日志是否超时或者异常,查看公司埋点框架mertic统计是否有拐点,因为内存消耗很少通过Zabbix查看Redis集群CPU信息。
监控下单接口性能,看是否超时或者异常,统计booking库中失败或者未到order库的订单数,定时预警超过阀值自动发邮件通知相关人员。
观察订单master数据库的性能,目前master机器是32核128g内存,通过Zabbix查看其CPU内存以及IO使用情况,查看slave机器的延迟分发情况,因为订单信息显示都是从slave机器读取的。
鉴于目前数据库还不支持sharding,对于大量的insert只能通过增加CPU、内存和SSD来弥补,不利于横向扩展且代价也比较昂贵,后期还是应该完善订单库sharding,降低单点单库的数据更新压力,是个长远的策略。总之大胆尝试小心验证,多备预案服务做到可切换可降级,减少系统间耦合尽量将风险降到最低。
当业务量爆发增长时,高可用架构是永恒的话题。出行、电商、社交网络、房产,每个看似不同领域的技术架构都承受着相同的高并发冲击。滴滴、京东、Facebook以及链家,四个不同的行业巨头将在这里分享他们自己在对高可用架构的见解。ArchSummit 9折倒计时,点击“阅读原文”了解详情。