
人工智能的发展将会取代人类的哪些工作一直都是备受关注的话题,而我们一直都认为人的思考能力是我们最后的堡垒。正如帕斯卡尔所说, “人只不过是一根会思考的芦苇”,我们是自然界最脆弱的生物,却因为思考变得无比强大。
演讲、写作是我们思考能力的直接表现,赫拉利在《人类简史》中说道,讲故事的能力让智人种变得和其他原始人和动物不一样。要是机器也能表达,也能写作也能讲故事来创造自己的文化,人何以与之对抗呢?
在由中国计算机学会(CCF)主办、雷锋网与香港中文大学(深圳)全程承办的AI盛会「全球人工智能与机器人峰会」的AI+分会场上,北京大学计算机科学技术研究所研究员万小军做了《机器写稿的技术与应用》的演讲报告。以下内容由雷锋网整理自万小军在会上的演讲实录。
机器写稿背景与现状

早在几年前,国外就已经有机器人写稿,最具代表性的是来自美国、欧洲的三家公司:ARRIA、AI、NARRATIVE SCIENCE。据说他们的机器人采用英语或者西方语言为著名的媒体网站写了数千万篇稿件。
国内的写稿机器人在这几年才开始慢慢受到大家的关注。有很多的媒体单位在和一些学术机构进行合作,推出写稿机器人。另外微软、百度、腾讯、今日头条这样互联网巨头也在研发机器写稿技术,因为它自己需要做一些内容的创作。主要是侧重在体育、财经、民生领域,一般政治类的涉及的比较少。涉及到政治稿件如果犯错的话,问题就比较大,所以主要还是在一些不太容易出问题的领域写稿。


机器人写稿的模式与技术
机器写稿有两种方式,一种是原创,一种是二次创作。原创一般是之前没有稿件,只有结构化的数据,我们可以借助结构化的数据去生成新的稿件。比如说我们写一个天气预报的报道,或者写一个年报、财报都直接可以从数据中生成。而关于一个已经有相关报道的事件,我们借助这些报道进行一些拼凑、改写成为新的稿件,这就是二次创作。

原创和二次创作所依赖的技术也是不太一样的。原创采用的是自然语言生成技术,是从结构化数据/意义表达生成自然语言语句。二次创作采用的是自动摘要技术,我们从已有的文字素材去给它摘要,把它生成一个新的稿件。这是两类非常关键的技术。
还有其它的一些相关技术:文本信息推荐技术和文本复述技术。比如说我们在写一个稿件的时候,有时候会想引用一句名人的话或者引用一个唐诗宋词,机器会自动给你推荐。第二个是文本复述技术,我们基于一个个稿件做创作的时候,如果我们直接把原文原始的内容拷贝过来,这个有点抄袭的嫌疑。所以这时候我们就需要做一些复述,会用不同的语言去表达同样的语义。这里有一个例子是说“梅西获得了5座金球奖”,你可以改为“梅西是五届金球奖得主”,也可以改写为“金球奖5次颁给了梅西”,这样就可以避免版权的问题,也可以让我们的改写更加生动。
机器人写稿应用广泛

机器人写稿的应用十分广泛。首先是新闻资讯的自动生成。我们输入结构化的数据,以及已经有的稿件,可以生成长度可控的几十个字到几千字的稿件。例如,一个体育的简讯的生成需要我们从网上抓取关于体育赛事的一些基本的数据,借助这个数据做一些数据分析,文档规划、语句的实现,就可以生成右边的这样一个比较简单的体育的赛事报道。 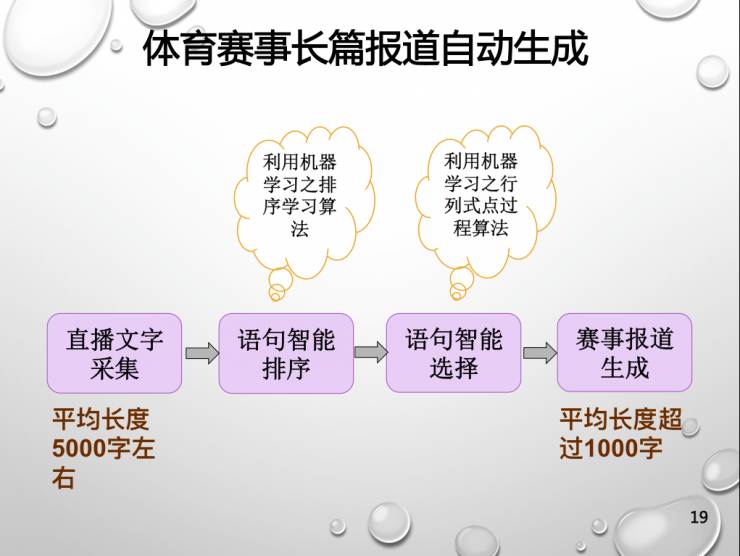
另一个是体育赛事的长篇报道的自动生成。简讯包含的信息量很少,我们想生成一个长篇的报道来介绍整个比赛的过程。我们经常发现著名的体育比赛下面都有文字直播,通常包含主持人对这样一个比赛的精彩细节的描述,我们通过机器学习的手段,能够把这些精彩的描述挑选出来,放到我们最终的报道中,这个报道就写得比较长,可以达到上千字以上。首先借助机器学习的手段,对直播文字进行语句的智能排序,再进行智能选择,最后生成一个平均长度超过1000字的赛事的报道。我们看到直播文字一般会达到数千字,一般是5000字以上,所以要从5000字中选择和拼凑出1000字以上的长篇报道。

还有一个是娱乐新闻的自动生成,娱乐新闻有很多不同的生成方式。比如说你可以根据明星的数据库,直接对这个明星做一个简单的描述。我们做的是可以借助明星的微博生成娱乐新闻。明星通常会发一些微博,有些微博会吸引大家的眼球,构成热新闻。我们有一个机器学习的手段,能自动判别明星发的哪一条微博具有新闻价值,再判断这个微博下面的哪些评论,具有新闻价值。把这个微博和它的评论以及相关的背景信息组合在一块,就可以形成一个比较短的新闻。 
我们也做了新闻综述的自动生成的尝试。我们对于某一个事件已经有比较多的新闻报道,需要思考怎样基于这些报道去自动生成一个篇幅较长的事件的综述。我们所使用的对象是用Wikinews,它的内容基本都是比较客观、比较中立的综述。它会对已有的报道做一些分析,做一些无偏袒的综合,然后得到一篇长的综述。我们拿这样的数据做了一个实验,去做一些语句的筛选和组合。因为要构成一个综述,所以不是以句子为单位,而是以一个子话题为单位。我们首先划分子话题,每个话题对应一个段落。然后对它进行一个重要性的排序,最后做一个段落的选择,也就是子话题的选择并且把相关的子话题合并,得到一个更完备的子话题最终形成完整的事件的综述。

除了生成事实型的新闻之外,我们也尝试让机器人去生成用户的评论。我们输入对于产品的某一个特征或者某几个特征上的评分,比如我输入给这个软件的是我对这个汽车的操控性是5分评价,对它的外观是3分评价,根据这个评价会自动生成一个自然语言的评论。我们采用的是一个深度学习的模型,右边是这样一个模型的架构。我们提前可以看我们最终生成的这样一个例子。
这个汽车有空间、动力、控制等等一系列的特征,用户要做的就是针对每个特征输入一个分数值,这个分数值越高代表你越满意,分数值越低就越不满意。我们看到这个例子,比如我们输入的空间是3分,动力是4分,舒适性是3分,3分代表一般,我们看到右侧生成的中文的评论,得到的表达是“舒适性一般,毕竟是运动型的车”,它很准确的对这个分数进行了描述。然后把舒适性从3分改成5分,5分是非常满意,最终生成的对应的文字的部分就是“舒适性很好,座椅的包裹性很好,坐着很舒服”。我们的模型能够很好将这个分数的细微改动直接反应到最终的自然语言的结果上。能够根据用户对我们的产品的特征的分数的输入,自动生成一个比较完整的一大段的用户的评论。这是基于深度学习模型来做的。
写稿机器人小明小南和阿同
我们目前有三个合作的机器人写稿项目,一个是今日头条的“Xiaomingbot”小明机器人,南方都市报的“小南”,广州日报的“阿同”机器人。小明主要服务于奥运会,小南、阿同当时是给2017年的全国两会做了一些报道的工作。
跟今日头条合作推出的小明写稿机器人,主要是针对体育赛事进行赛事的简讯和长篇报道的生成,既可以生成几十字的短讯,又可以生成上千字的长篇报道,它包括足球联赛,也包括NBA的比赛,在奥运会期间写了456篇,单篇最高的阅读量是11万次。到上个月底,共撰写新闻5000多篇,总计阅读量1800万次,这是因为今日头条的用户量很多,所以阅读量也是很多的。

这是Xiaomingbot头条号的界面。这个欧冠决赛,尤文图斯以1:4完败皇家马德里的比赛的结果的新闻是完全靠机器写出来的,这个稿件的文字很长,有1121个汉字,它比较准确地把这个比赛的主要信息都做了一个描述,还是比较完整的一篇新闻报道。
 小南写稿机器人现在是在南方都市报的APP上撰写一些民生新闻,去年年底做过春运火车票的新闻撰写,侧重广州到其它大城市的新闻,最近写的是天气预报的新闻,在两会期间还写过两会的小南读报的新闻。
小南写稿机器人现在是在南方都市报的APP上撰写一些民生新闻,去年年底做过春运火车票的新闻撰写,侧重广州到其它大城市的新闻,最近写的是天气预报的新闻,在两会期间还写过两会的小南读报的新闻。
小南写的春运火车票的新闻中采用了不少卖萌的句子。当然这也是把我们的新闻记者的语言表达做了很好的总结,最后使我们的机器人也能这样表达出来。 最近小南机器人也做了一些天气预报的写作。小南读报主要是在两会期间统计南方都市报跟两会相关报道都分别属于哪些领域,做了一个统计和盘点,然后把这个盘点的结果用自然语言的形式表达出来。另外对其中一些爆款的新闻做了摘要和总结,也放在这个稿件中,所以这个稿件的信息量是比较丰富的,对多篇新闻进行了盘点。

阿同主要是在两会期间做了一些工作,主要是对政府的工作报告做一些热词和关键数据的解读,解读完了之后进行自然语言的表达。这是阿同对政协工作报告做一个热词的分析,今年的政协工作报告有哪些热词,这些热词跟去年相比有哪些变化,把这个变化的情况用自然语言表述,最终形成在报纸上印出来的报道。因为广州日报要在报纸上印出来,所以对错误是零容忍,所以必须经过人工的审核。
传统媒体VS新媒体

对于不同的应用单位,对稿件的质量要求是不一样的,对于一些传统的媒体单位,它对稿件的错误是零容忍。要发布到报纸上需要通过人工的审核,而一些自媒体可能就直接发在网上,个别的错别字或者个别的语句不通顺不影响网友的阅读,网友可能在下面写一个评论,说这个稿件怎么还有错别字,但是这个也不影响网友的阅读和点击。所以自媒体对稿件的质量容忍度比较高一点。所在两种不同的场合下应用的要求是不太一样的,所以我们在机器写稿发稿的时候也会有所不同。
机器人VS记者

目前为止,机器人跟记者之间的关系是一种分工协作的关系。机器人现在不具有逻辑思维的能力,也不具有深度总结的能力,它只能去把一个基本的新闻事实描述清楚,但是我们记者就可以写深度报道,比如说中国足球,他可以经过自己的分析,写中国足球这几十年来落后的原因,它可以总结出几条观点,但是机器人总结就很难了,所以我们的记者应该是从事有创造性的、高智商的稿件的创作,而把一些重复的、低层次的稿件创作的活动交给机器人完成,所以是一种分工协作的关系。
另外一个不同点就是,记者在写一个稿件的时候,他是很清楚地知道我在写什么,他知道自己要表达的语义。但实际上机器人在写这个稿件的时候,虽然他把每一个句子都写出来了,但实际上他不知道自己要写什么,这是最大的一个不同,就是说它没有理解自己的稿件,虽然它写出来了,包括机器人写诗,或者写各种歌词的时候,它也把那个语言写出来了,但是它并没有真正理解那个语言,所以这是一个比较大的不同。
未来展望
最后是一个未来的展望。我们看到现在机器写稿不光是在媒体行业,我们现在也在跟一些游戏行业和情报行业合作,他们也有机器写稿的需求,只要什么时候你需要写这样一些报告,比如写一些行业报告,或者写一些稿件,都可能会利用到机器写稿的技术,不光是媒体行业写新闻会用到,其它的行业也会用到。
第二个方向,我们现在写的稿件还主要侧重对客观事实的描写,还没有加入太多的态度和立场,因此显得人性化方面不太理想,下一步会让我们的稿件自己具有一定的立场,比如我们在报道中国队对韩国队的比赛的时候,我们如果站在韩国队的立场,如果中国队输了的话,我们就应该是很高兴的,标题可能会说“韩国队大胜中国队”,如果是站在中国队的立场,可能标题写会“中国队憾负韩国队”,这个立场就不一样,我们的稿件具有这样的态度和立场,它就会更加人性化。
第三点也是最难的一点,就是让机器学会推理和归纳,写出真正的深度报道。比如说我们报道一场足球比赛以后,我们要分析一下为什么是这样的结果,把这个原因进行推理总结出来。这样的报道就是真正的智能的,像之前写的稿件是一个弱人工智能时代,如果我们要写一个强人工智能的稿件,就必须让机器具有这样的态度和立场,也具有这样的推理、归纳能力,这是下一步要研究的目标,也是有可能去实现的一些目标。尤其是具有态度和立场,我觉得应该在未来两三年是可以去实现的。然后推理跟归纳,可能两三年的时间都不一定够,我觉得需要更长的时间才有可能取得一些突破。
(万小军老师的演讲很细腻精彩,会后雷锋网对万小军老师进行了专访,更多关于写稿机器人的问题的探讨请点击:《专访北大计算机所万小军:写稿机器人是新媒体时代的产物| CCF-GAIR 2017》)
更多大牛的精彩演讲,请继续关注雷锋网后续报道。










