本文简要介绍
SIGGRAPH 2020
的
论文
“Attribute2Font: Creating Fonts You Want From Attributes”
的主要工作
。
该论文针对字体合成任务提出一种基于深度学习的方法,该方法可以根据字体的属性以及属性值来创建对应的字体。具体来说,对本文的模型进行了训练,可以在以其属性值为条件的任何两种字体之间执行字体样式转换。经过训练后,模型可以根据任意一组字体属性值生成字形图像。此外,设计了一个名为
“属性注意模块”的模块,以使生成的字形图像更好地体现突出的字体属性。考虑到获得字体属性值的注释非常昂贵,还引入了一种半监督学习方案来利用大量未标记的字体。实验结果表明,本文的模型在许多任务上均取得了不错的性能,例如以新的字体样式创建字形图像,编辑现有字体,在不同字体之间进行插值等。

图1(
a
)模型概述,给定任意一组预定义的字体属性值,可以合成相应样式的字形图像。(
b
)在不同属性集中合成的英文和中文字形图像的示例。
传统字体设计工作流程为普通用户设置了较高的壁垒,这需要该领域的创造力和专业知识。因此,字体设计仍被认为是专业设计师的专有特权,而他们的创造力是现有软件系统所不具备的
。在计算机图形学(
CG
),计算机视觉(
CV
)和人工智能(AI)领域,自动字体设计仍然是一个充满挑战的问题。不过实际上大多数商业字体产品都是根据某些字形属性(例如斜体,衬线,草书,宽度,角度等)的
特定要求手动设计的。受这一事实的启发,作者提出
Attribute2Font
模型,通过根据用户指定的属性及其对应的值合成视觉上令人愉悦的字形图像来自动创建字体,提出的模型大大降低了普通用户创建字体的难度。
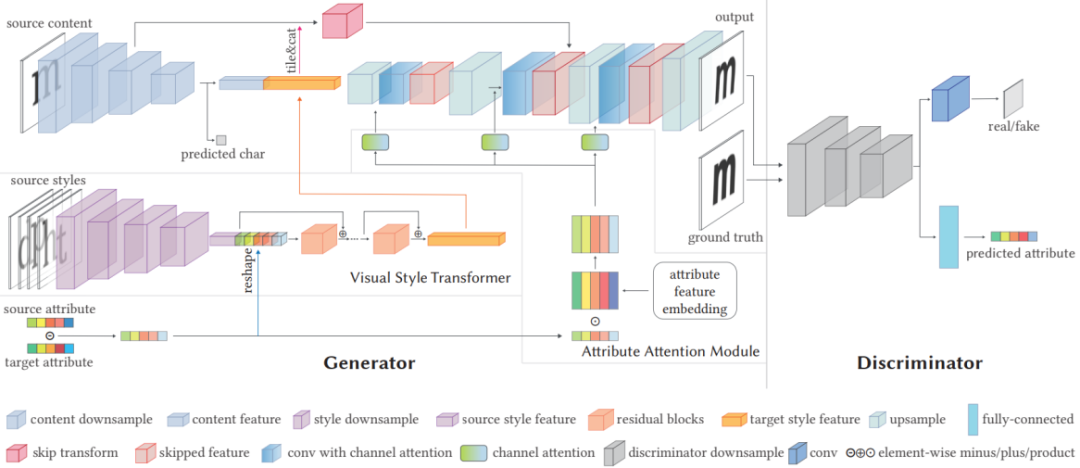
图
2
Attribute2Font
的整体网络结构
图
2
是
Attribute2Font
的整体网络结构,主要由分层的编码
-
解码器组成的生成器、视觉样式转换器(
Visual Style Transformer, VST
),属性注意力模块(
Attribute Attention Module
,
AAM
)和判别器四个部分构成。网络的输入有:字体
F
的一张图作为源内容图,字体
F
的
m
张图作为源风格图,另外还有源字体和目标字体的属性值。
视觉样式转换器(VST)旨在根据字体
a
的字形图像和这两种字体之间的属性差异来估计字体
b
的样式特征。首先使用基于
CNN
的样式编码器将选定的字体
a
的字形图像转换为其样式特征,根据经验,单个字形无法充分体现其所属的字体样式,因此这里将输入的字形图像数量
m
设置为
m> 1
来更精确地估计样式特征。然后,将编码特征和源字体和目标字体的属性差值进行拼接,之后再经过
N
个残差块,并最终获得了估计的目标样式特征。
属性注意模块(
AAM
)旨在进一步完善属性,以便它们可以在字形图像生成阶段更好地使用。如图
3
所示是
AAM
的详细结构,首先将字体
a
和字体
b
的属性差值通过复制从大小
(Na, 1)
变成
(
Na, Ne)
,其中
Na
是属性的类别数,
N
e
是属性嵌入矩阵的维度,然后按照图中左下角的操作,将这个属性与它的转置相乘,得到一个三维特征,然后经过通道注意力机制(
Channel Attention
)
[
2,3]
,通过利用特征的通道间关系生成通道注意图。具体来说,首先通过平均池化层对特征图进行聚合,然后将其发送到两个卷积层中,并进行通道压缩和拉伸来输出通道注意图。
生成器部分采用分层编码器
-
解码器框架,其中编码器用来提取输入源图像的内容特征。解码器利用来自内容编码器的多尺度特征来更准确地重构字形的形状,如图
2
的跳跃连接所示。并且将
Softmax
分类器附加到编码器输出的内容特征上以预测源图像输入的的字符类别,使用的是分类中常用的
Cross-entropy
损失函数。在解码器的各个阶段中,除了上采样操作外,还会整合编码器的多尺度特征和
AAM
输出的多尺度特征,以此来更好的生成想要的图像。生成器部分除了
GAN
的通用损失函数外,也利用
L
1
来计算输出与
GT
的损失和高维空间上的损失,另外还对生成图像进行属性预测,使用
Smooth
L1
函数进行监督。
遵循
GAN
的对抗训练方案,这里使用字形鉴别器来区分生成的图像和
GT
。通过生成器和鉴别器之间的对抗博弈,可以不断提高生成的字形的质量。采用的损失函数一个是原始
GAN
的损失函数,另一个是对真实图像的属性值进行预测,同样使用
Smooth
L1
函数作为损失函数。
为了解决有标记的训练数据的不足的问题,作者采用半监督学习的方案。首先对未标记的字体设置一个伪属性值,将所有属性值根据高斯分布归一化到0-1之间。然后在训练过程中,将标记的字体属性值固定,而未标记的字体属性值会用梯度下降法进行优化,不断修改未标记的字体的属性值。
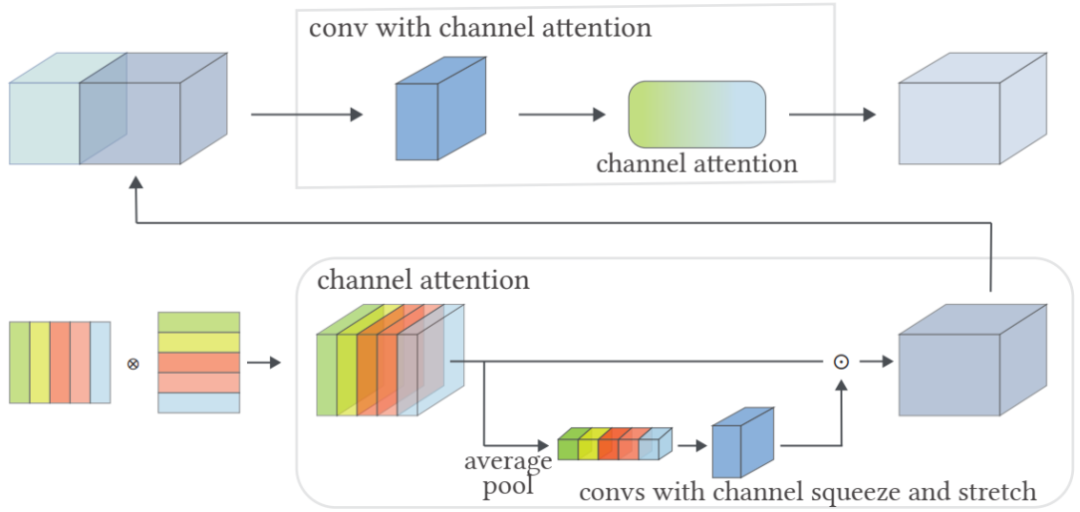
图
3
属性注意模块的结构以及如何将其整合到解码器的特征图
AttrFont-ENG
数据集:使用
[1]
中提出的
字体数据集
,包含
1
48
个有属性标注的字体和
9
68
个没有属性标注的字体,每种字体包含
5
2
个字符(
a-z
, A-Z
)。其中,每种字体有
3
7
类属性,既包含
“细”和“角度”之类的具体属性,又包含“友好”和“草率”的模糊概念。作者将前
1
20
种字体划分为有监督的训练集,剩下
2
8
种字体作为验证集。
作者对源字体的选择对结果的影响进行探究,直观上生成的字形的样式会受模型中源字体的选择影响。令人惊讶的是,如图5的实验结果,在不同的源字体输入下,输出具有几乎相同的形状和细微的差别,发现当选择常规字体作为源字体时,影响很小。这种现象表明,本文的模型设法根据其属性值将不同的字体样式映射到固定的字体样式。

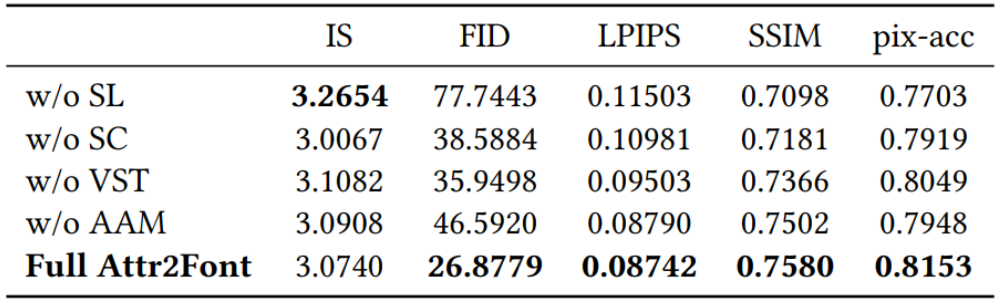
作者对不同模块进行了消融实验,如表
1
定量结果比较发现,通过利用未标记的字体,提出的半监督学习方案带来了显着的改进,
AAM
模块也极大地提高了模型的性能。如图
5
定量结果比较发现,如果没有半监督学习方案或各种跳跃连接或
VST
模块,模型往往会在合成结果上带来更多的假象;如果没有
AMM
模块,模型往往会错过一些重要的特征。
表
1
消融实验的定量结果,
w / o
表示没有,“
SC
”表示跳跃连接,“
SL
”表示半监督学习。

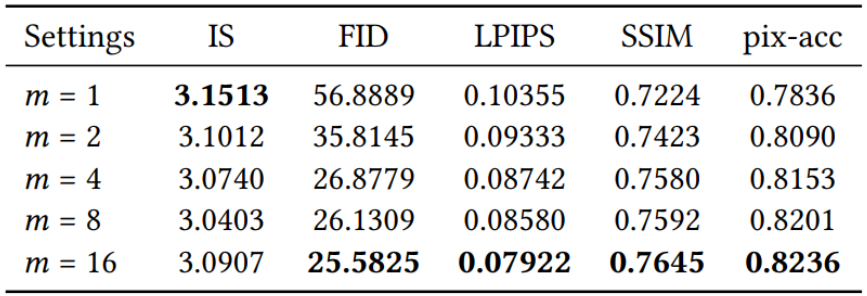
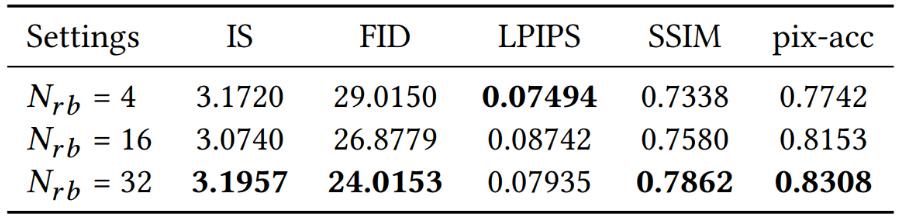
作者进行实验研究输入到样式编码器中的字形图像数量m和
VST
模块中的残存块数量
Nrb
对模型性能的影响。结果显示在表
2
和
3
中,从各项评价指标可以观察到,通常更大的
m
和
Nrb
会取得更好的性能。但是,较大的
m
和
Nrb
值会增加模型的计算成本。为了在模型尺寸和性能之间取得平衡,本文选择
m = 4
和
Nrb = 16
作为模型的默认设置。
图
6
对不同的两种字体之间进行了插值实验,其中
λ
是插值系数,结果显示了本文的模型在不同字体之间实现了平滑插值,并生成了视觉上令人愉悦的字形图像,并且,从插值属性值合成的字形图像更易于解释。图
7
显示了通过修改单个字体属性(例如衬线,草书,斜体,粗,细和宽)的值来合成的字形图像的一些示例,可以看到,当属性值从
0.0
变为
1.0
时,模型可以实现平滑且渐变的过渡。图
8
展示了从几个属性值的随机集合中生成的模型字形图像。在此实验中,第一行中显示的源字体是固定的,然后随机分配每一行每个字符的属性值。如图所示,合成字形图像的字体样式变化很大,并且大多数在视觉上令人愉悦。

图
6
在两种不同字体的属性值之间进行插值来生成字形图像。依次介绍三个插值过程(字体
1
至字体
2、
字体
2
至字体
3、
字体
3
至字体
4
)。


该实验通过演示不同字体(包括标记字体和未标记字体)的属性值的分布来说明半监督学习方案是如何工作的。
首先通过
PCA
(主成分分析)将每种字体的属性值缩小为两个维度,如图
9
中,绿点对应于未标记的字体,蓝点对应于带有标签的字体。训练开始时(
Epoch
10
),绿点几乎完全与蓝点分开。在后期,绿点会根据特定分布混入蓝点中,此时未标记字体的属性值从随机状态演变为有意义状态,这验证了半监督学习方案的有效性。在
Epoch 400
中将某些字体的字符标签添加到它们的对应点。可以观察到,相似的字体位置更近,而属性值相差较大的字体位置更远。因此,半监督学习方案对未标记字体的预测属性是合理的。
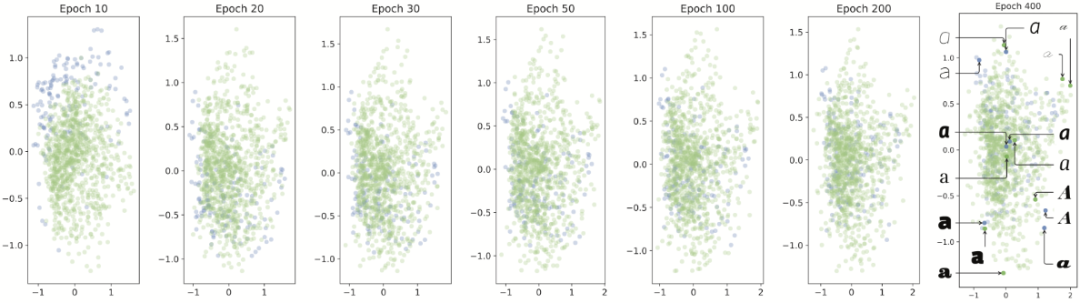
图
9
属性值的分布随训练时期而变化,绿色和蓝色点分别表示未标记和标记的字体。
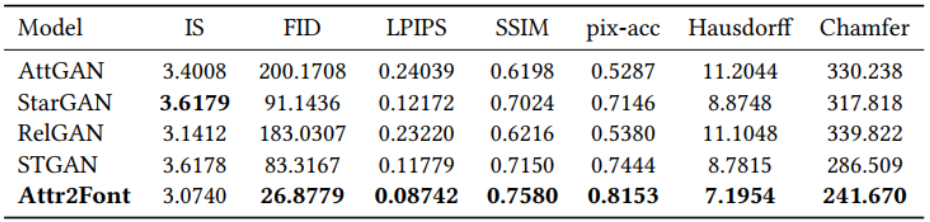
将本文的方法与现有的属性可控图像合成方法进行比较,包括
AttGAN
[4]
,
StarGAN
[5]
,
RelGAN
[6]
和
STGAN
[7]
。在图
10
中,从验证数据集中选择四种字体,这些字体的属性值设置为模型中的目标属性。因为这些现有的
GAN
只能接受二进制属性值,所以如果它们接收的属性值小于或大于
0.5
,则将它们设置为
0
或
1
。从结果可以看到,
AttGAN
和
RelGAN
倾向于生成非常模糊和低质量的字形,而
STGAN
所生成的字形要比
AttGAN
和
RelGAN
的质量更高,但
STGAN
仍会在字形图像中带来许多假纹理。表
4
给出了整个验证数据集上的定量结果,这表明本文模型明显优于其他模型,表
5
是不同方法的模型大小,本文的模型的参数比
STGAN
少,但性能却比
STGAN
好得多。

图
10
与现有属性可控图像合成方法的定性结果比较