
在即将召开的 ACL 2017 大会的录取论文中,有一篇做对话系统研究的论文定义了一个新的小问题:chat detection。这篇论文和近期的一些相关论文一样,都试图去探讨更宽泛的对话场景下的用户意图识别。今天会涉及到的一些相关论文有:
《Chat Detection in an Intelligent Assistant: Combining Task-oriented and Non-task-oriented Spoken Dialogue Systems》. ACL 2017.
《DeepProbe: Information Directed Sequence Understanding and Chatbot Design via Recurrent Neural Networks》. arXiv preprint.
以第一篇[1] chat detection 切入。在 chat detection 中,详细探讨了对话系统研究领域的几类场景:specific domain task-oriented 和 open domain non-task-oriented。其中前者又分为 single domain 和 multi domain task-oriented。过去的研究工作,多数集中于 intent and domain determination,而这两种主要都是关于 task-oriented 也就是任务导向型的对话系统的研究问题。而这篇论文[1] 想要探讨的问题是集成任务导向型和开放领域非任务导向型的综合对话系统场景下的。
举个例子来说,比如在很多智能家电中,用户既会发出一些指令如“Set an alarm at 8 o'clock.”也会说一些聊天的话如“What is your hobby?”。针对这两种不同的用户输入,作者提出的解决办法是先区分这两种场景,再具体问题具体分析,进行模块化处理。作者将区分这两种场景的任务,叫做 chat detection,并且建模成了二分类问题。
值得一提的是,虽然过去有人把 non task-oriented 的这种输入也“统一”进了 intent determination 中,设为一种新的意图类别,但作者并不认同。这是因为,他们认为,针对 non task-oriented 的用户输入,系统后续并不进行 slot filling 等任务导向型对话系统中的模块处理,故应该单独区分。从最快捷地利用已有研究成果的角度,这种处理方式确实更简单。
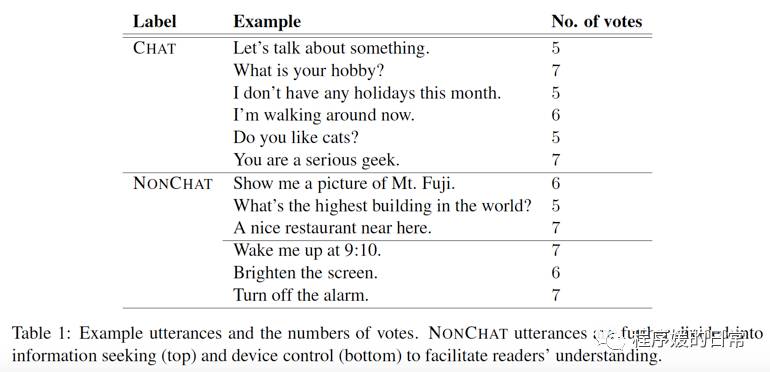
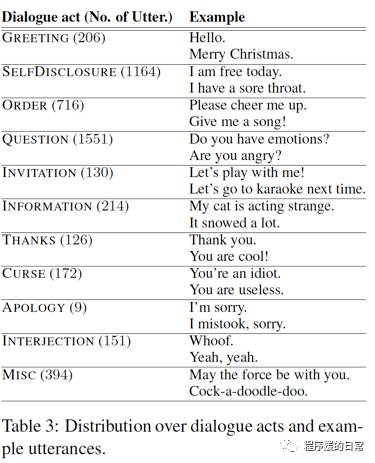
为了进行 chat detection 的实验,他们在 Yahoo! Voice assistant 的用户数据中收集了一万多条数据,并进行了人工标注。标注中,除了有 task-oriented(NonChat) 还是 non task-oriented(Chat) 的标注外,还有针对后者的 dialogue act 的更细粒度的分类。
有了数据,作者构造了两大类分类器进行 chat detection 的二分类任务实验。第一大类分类器只依赖于用户输入(utterance)本身,而第二大类分类器则利用了外部资源(Tweets and Web Search log)。重点来看第二大类分类器:
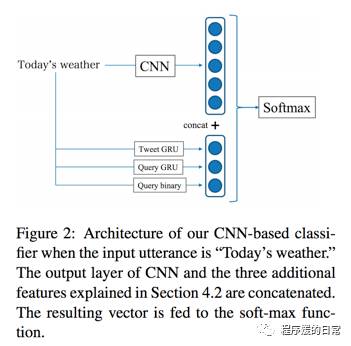
其中,Tweet GRU 和 Query GRU 分别代表用 Tweet 语料和 Query 语料训练的 字符集的 GRU 语言模型得到的特征。第三个 Query binary 则是一种作者考虑到的独特的特征,即,有些用户会只说一个实体名称(entity)来查询这个实体的相关信息。为此,作者将这种只包含一个实体名称的用户输入和 Query log 进行匹配,得到的 binary 信息当做第三种特征。这三种特征要么作为 SVM 分类器的特征,要么和 CNN 的特征进行拼接,最终输出二分类结果。
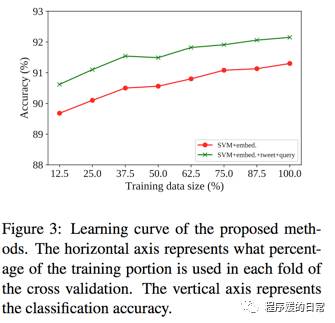
从实验结果可以看到,加入了这三类利用外部资源的特征后,分类器只需要25%的数据就可以达到只用用户输入(utterance)信息训练的分类器,这也就证明了这些外部资源的价值。
刚刚介绍的这篇文章[1] 在未来工作的讨论部分提到了一个小的现象。那就是有时候用户的输入,会很难判别,也就是意图模棱两可。举个例子,当用户说“I'm hungry”的时候,用户既可能是闲聊,也可能是希望得到一些附近餐馆的推荐和订餐。遇到这种情况,一种解决方案就是让对话系统进一步提出问题来确认用户的真正意图(making clarification questions)。近期就有一篇论文[2] 探索了相关问题。
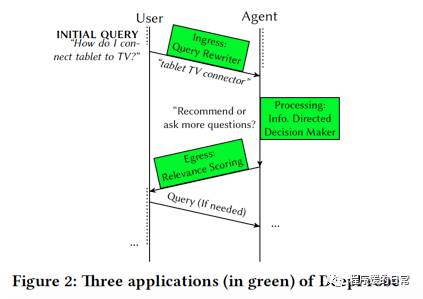
在论文[2] 中,作者举了一个例子,当用户输入“tablet TV connector”时,既可能是想搜索如何连接,也就是使用说明,也可能是想购买。那么这时候到底是给出解决方案(调用搜索引擎),还是给出广告(调用推荐系统)就是一个很有商业价值的场景。可以从上图看到,当系统不能足够确认用户的意图时,这个系统就会询问更多的问题来帮助它自身进行决策。
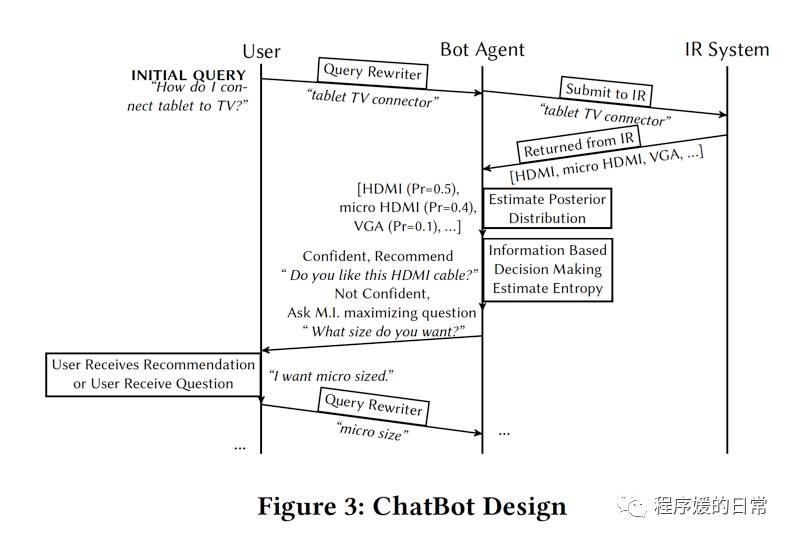
为了让自己的系统鲁棒性更强,作者[2] 提出了一个重要的模块是 Query Rewrite,也就是将用户的不标准的输入改写成更标准、语法更严格的输入,再和系统中的查询库进行匹配和检索。改写后的用户输入(query)会提交给检索系统,检索系统会返回最相关的广告商品的列表。这个系统会进一步进行“检验”,如果对于用户的输入的意图判别不明确,他们会采取继续提问的决策,并通过最大化条件互信息的准则来选取要提的问题。这个过程不断的交替,直到系统可以明确用户的输入(相当于用户已经完成信息的获取)。这里值得一提的是,候选的可能提的问题,都是基于商品的属性(attributes)来构造的。作者同时也给出了自己的 demo 界面:
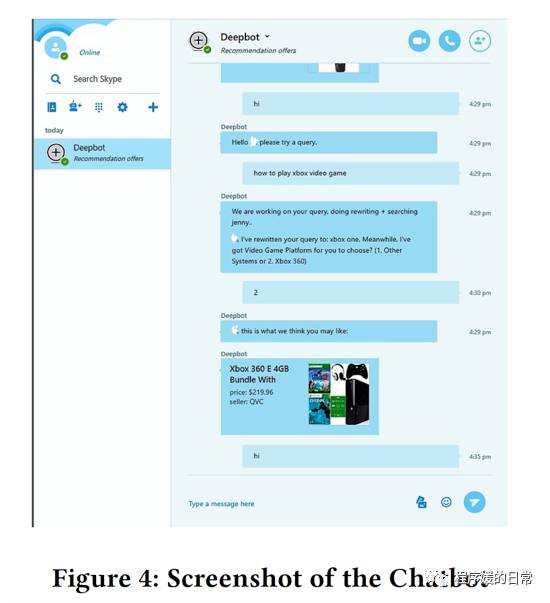
从今天的两篇论文看出,对话系统作为一种交互系统,在真实世界中的使用场景往往更加宽泛,也有越来越多的研究者和公司注意到了这方面的问题。相信未来会有更多有趣的综合的数据开放出来。下一次再分享一些意图识别的新工作吧~










