
近年来,Python 在数据科学行业扮演着越来越重要的角色。因此,我根据近来的使用体验,在本文中列出了对数据科学家、工程师们最有用的那些库。
由于这些库都开源了,我们从Github上引入了提交数,贡献者数和其他指标,这可以作为库流行程度的参考指标。
核心库
1. NumPy (提交数: 15980, 贡献者数: 522)
当开始处理Python中的科学任务,Python的SciPy Stack肯定可以提供帮助,它是专门为Python中科学计算而设计的软件集合(不要混淆SciPy库,它是SciPy Stack的一部分,和SciPy Stack的社区)这样我们开始来看一下吧。然而,SciPy Stack相当庞大,其中有十几个库,我们把焦点放在核心包上(特别是最重要的)。
关于建立科学计算栈,最基本的包是Numpy(全称为Numerical Python)。它为Python中的n维数组和矩阵的操作提供了大量有用的功能。该库提供了NumPy数组类型的数学运算向量化,可以改善性能,从而加快执行速度。
2. SciPy (提交数: 17213, 贡献者数: 489)
SciPy是一个工程和科学软件库。雷锋网再次提醒,你需要理解SciPy Stack和SciPy库之间的区别。
SciPy包含线性代数,优化,集成和统计的模块。SciPy库的主要功能是建立在NumPy上,从而它的数组大量的使用了NumPy的。它通过其特定子模块提供有效的数值例程,并作为数字积分、优化和其他例程。SciPy的所有子模块中的功能都有详细的说明 ——又是一个SciPy非常有帮助的点。
3. Pandas (提交数: 15089, 贡献者数:762)
Pandas是一个Python包,旨在通过“标记”和“关系”数据进行工作,简单直观。Pandas是数据整理的完美工具。它设计用于快速简单的数据操作,聚合和可视化。
库中有两个主要的数据结构:
-
“系列”(Series),一维
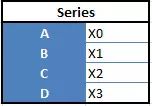
-
“数据帧”(Data Frames),二维
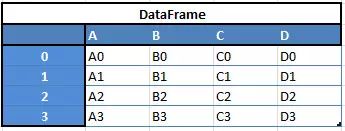
例如,当您要从这两种类型的结构中接收到一个新的Dataframe时,通过传递一个Series,您将收到一个单独的行到DataFrame的DF:
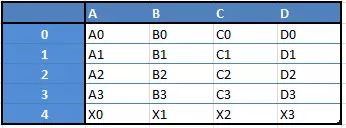
这里稍微列出了你可以用Pandas做的事情:
-
轻松删除并添加数据帧(DataFrame)中的列
-
将数据结构转换为数据帧(DataFrame)对象
-
处理丢失的数据,表示为NaN
-
功能强大的分组
Google趋势记录
trends.google.com
GitHub请求历史记录
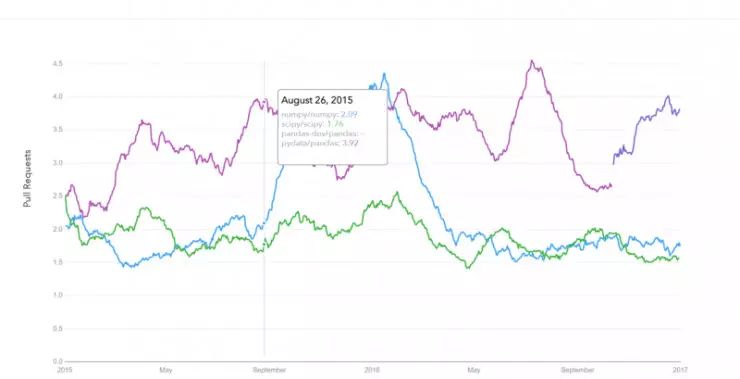
datascience.com/trends
可视化
4.Matplotlib (提交数: 21754, 贡献者数: 588)
又一个SciPy Stack核心软件包以及 Python库,Matplotlib为轻松生成简单而强大的可视化而量身定制。它是一个顶尖的软件(在NumPy,SciPy和Pandas的帮助下),它使Python成为像MatLab或Mathematica这样的科学工具的竞争对手。
然而,这个库是低层级的,这意味着你需要编写更多的代码才能达到高级的可视化效果,而且通常会比使用更多的高级工具付出更多的努力,但总体上这些努力是值得的。
只要付出一点你就可以做任何可视化:
-
线图
-
散点图
-
条形图和直方图
-
饼状图;
-
茎图
-
轮廓图
-
场图
-
频谱图
还有使用Matplotlib创建标签,网格,图例和许多其他格式化实体的功能。基本上,一切都是可定制的。
该库由不同的平台支持,并使用不同的GUI套件来描述所得到的可视化。不同的IDE(如IPython)都支持Matplotlib的功能。
还有一些额外的库可以使可视化变得更加容易。
5. Seaborn (提交数: 1699, 贡献者数: 71)
Seaborn主要关注统计模型的可视化;这种可视化包括热图,这些热图(heat map)总结数据但仍描绘整体分布。Seaborn基于Matplotlib,并高度依赖于此。
6. Bokeh (提交数: 15724, 贡献者数: 223)
另一个很不错的可视化库是Bokeh,它针对交互式可视化。与以前的库相比,它独立于Matplotlib。正如我们提到的,Bokeh的主要焦点是交互性,它通过现代浏览器以数据驱动文档(d3.js)的风格呈现。
7. Plotly (提交数: 2486, 贡献者数: 33)
最后,关于Plotly的话。它是一个基于Web用于构建可视化的工具箱,提供API给一些编程语言(Python在内)。在plot.ly网站上有一些强大的、上手即用的图形。为了使用Plotly,你将需要设置API密钥。图形将在服务器端处理,并发布到互联网,但有一种方法可以避免。
Google趋势记录
trends.google.com
GitHub请求历史记录
datascience.com/trends
机器学习
8. SciKit-Learn (提交数:21793, 贡献者数:842)
Scikits是Scikits Stack额外的软件包,专为像图像处理和机器学习辅助等特定功能而设计。对于机器学习辅助,scikit-learn是所有软件包里最突出的一个。它建立在SciPy之上,并大量利用它的数学运算。
scikit-learn给常见的机器学习算法公开了一个简洁、一致的接口,可简单地将机器学习带入生产系统中。该库中集成了有质量的代码和良好的文档、简单易用并且十分高效,是使用Python进行机器学习的实际行业标准。
深度学习—— Keras / TensorFlow / Theano
在深度学习方面,Python中最着名和最便的库之一是Keras,它可以在TensorFlow或Theano框架上运行。让我们来看一下它们的一些细节。
9.Theano. (提交数:25870, 贡献者数:300)
首先让我们谈谈Theano。
Theano是一个Python软件包,它定义了与NumPy类似的多维数组,以及数学运算和表达式。此库是被编译的,可实现在所有架构上的高效运行。最初由蒙特利尔大学机器学习组开发,它主要用于满足机器学习的需求。
值得注意的是,Theano紧密结合了NumPy在低层次上的运算 。另外,该库还优化了GPU和CPU的使用,使数据密集型的计算平台性能更佳。
效率和稳定性微调保证了即使在数值很小的情况下,仍有更精确的结果,例如,即使只给出x的最小值,log(1 + x)仍能计算出合理的结果。
10. TensorFlow. (提交数: 16785,贡献者数: 795)
TensorFlow来自Google的开发人员,它是数据流图计算的开源库,为机器学习不断打磨。它旨在满足谷歌对训练神经网络的高需求,并且是基于神经网络的机器学习系统DistBelief的继任者。然而,TensorFlow并不限制于谷歌的科学应用范围 – 它可以通用于多种多样的现实应用中。
TensorFlow的关键特征是它的多层节点系统,可以在大型数据集上快速训练神经网络。这为谷歌的语音识别和图像对象识别提供了支持。
11. Keras. (提交数: 3519,贡献者数: 428)
最后我们来看看Keras。它是一个用Python编写的开源的库,用于在高层的接口上构建神经网络。它简单易懂,具有高级可扩展性。Keras使用Theano或TensorFlow作为后端,但微软现在正努力整合CNTK(微软的认知工具包)作为新的后端。
设计中的简约方法旨在通过建立紧凑型系统进行快速、简便的实验。
Keras真的容易上手,并在持续完善它的快速原型能力。它完全用Python编写,可被高度模块化和扩展。尽管它以易上手、简单和以高层次为导向,但是Keras足够有深度并且足够强大,去支持复杂的模型。
谷歌发展趋势历史
trends.google.com
GitHub请求历史记录
datascience.com/trends
自然语言处理
12. NLTK (提交数: 12449,贡献者数: 196)
这个库的名称“Natural Language Toolkit”,代表自然语言工具包,顾名思义,它用于符号学和统计学自然语言处理(NLP) 的常见任务。 NLTK旨在促进NLP及相关领域(语言学,认知科学人工智能等)的教学和研究,目前受到重点关注。
NLTK的功能允许很多操作,例如文本标记,分类和标记,实体名称识别,建立语料库,可以显示语言内部和各句子间的依赖性、词根、语义推理等。所有的构建模块都可以为不同的任务构建复杂的研究系统,例如情绪分析,自动总结。
13. Gensim (提交数: 2878,贡献者数: 179)






