散点图
散点图在生物信息分析中是应用比较广的一个图,常见的差异基因火山图、功能富集分析泡泡图、相关性分析散点图、抖动图、PCA样品分类图(后续推出)等。凡是想展示分布状态的都可以用散点图。
横纵轴都为数字的散点图解析
绘制散点图的输入一般都是规规矩矩的矩阵,可以让不同的列分别代表X轴、Y轴、点的大小、颜色、形状、名称等。
输入数据格式 (使用火山图的输入数据为例)
火山图需要的数据格式如下
id: 不是必须的,但一般的软件输出结果中都会包含,表示基因名字。
log2FoldChange: 差异倍数的对数,一般的差异分析输出结果中也会给出对数处理的值, 因此程序没有提供这一步的计算操作。
padj: 多重假设检验矫正过的差异显著性P值;一般的差异分析输出结果为原始值,程序提供一个参数对其求取负对数。
significant: 可选列,标记哪些基因是上调、下调、无差异;若无此列或未在参数中指定此列,默认程序会根据padj列和log2FoldChange列根据给定的阈值自动计算差异基因,并作出不同颜色的标记。
label: 可选列,一般用于在图中标记出感兴趣的基因的名字。非-行的字符串都会标记在图上。
volcano = "id;log2FoldChange;padj;significant;label
E00007;4.28238;0;EHBIO_UP;A
E00008;-1.1036;0.476466843393901;Unchanged;-
E00009;-0.274368;1;Unchanged;-
E00010;4.62347;7.37606076333335e-103;EHBIO_UP;-
E00012;0.973987;0.482982440163204;Unchanged;-
E00017;-1.30205;0.000555693857439792;Baodian_UP;B
E00024;0.617636;2.78047837287061e-13;Unchanged;-
E00033;1.48669;2.56000581595275e-60;EHBIO_UP;-
E00034;-0.783716;0.00341521725291801;Unchanged;-
E00036;2.01592;6.03136656016401e-06;EHBIO_UP;C
E00040;-1.89657;4.73663890849056e-21;Baodian_UP;-
E00041;-0.268168;0.563429434558031;Unchanged;-
E00042;0.0861048;0.367700939634328;Unchanged;-
E00043;-1.19328;1.42673872027352e-153;Baodian_UP;-
E00044;-0.887981;2.43067804654905e-26;Unchanged;-
E00047;-0.610941;5.51696648645932e-57;Unchanged;-"
volcanoData ";", header=T, quote="", check.names=F)
head(volcanoData)
id log2FoldChange padj significant label
1 E00007 4.282380 0.000000e+00 EHBIO_UP A
2 E00008 -1.103600 4.764668e-01 Unchanged -
3 E00009 -0.274368 1.000000e+00 Unchanged -
4 E00010 4.623470 7.376061e-103 EHBIO_UP -
5 E00012 0.973987 4.829824e-01 Unchanged -
6 E00017 -1.302050 5.556939e-04 Baodian_UP B
绘制散点图,只需要指定X轴和Y轴,再加上geom_point即可。
library(ggplot2)
p p
p
说好的火山图的例子,但怎么也看不出喷发的态势。
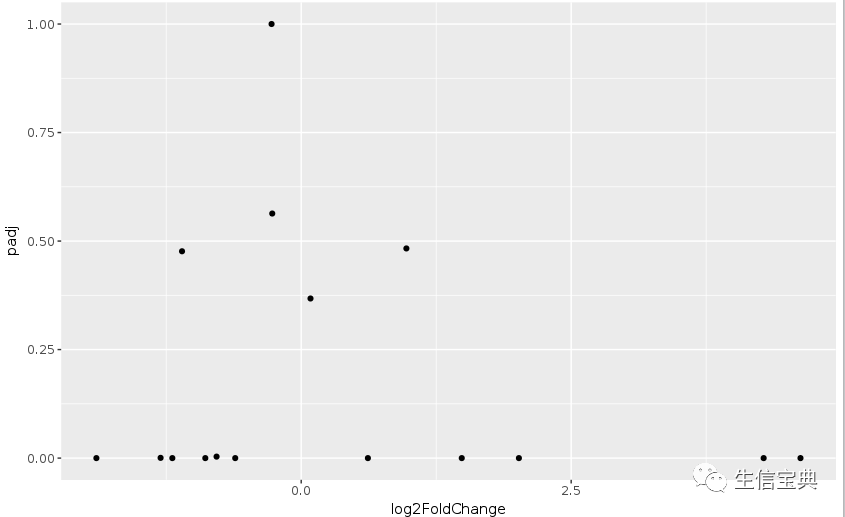
对数据坐下预处理,差异大的基因padj小,先对其求取负对数,所谓负负得正,差异大的基因就会处于图的上方了。
volcanoData[volcanoData$padj<1e-6, "padj"] 1e-6
volcanoData$padj 1)* log10(volcanoData$padj)
数据中基因的上调倍数远高于下调倍数,使得出来的图是偏的,这次画图时调整下X轴的区间使图对称。
p geom_point() +
xlim(-4.7, 4.7)
p
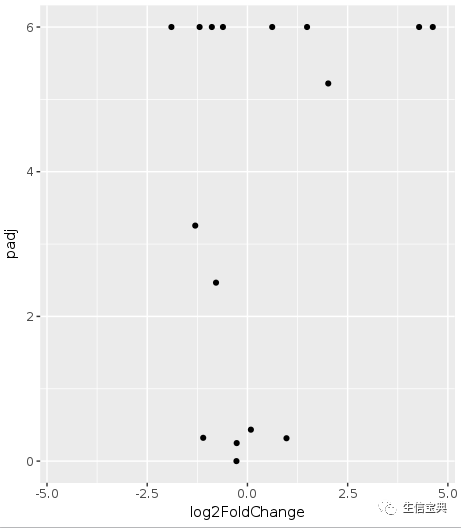
有点意思了,数据太少不明显,下一步加上颜色看看。
p geom_point(color=significant) +
xlim(-4.7, 4.7)
p
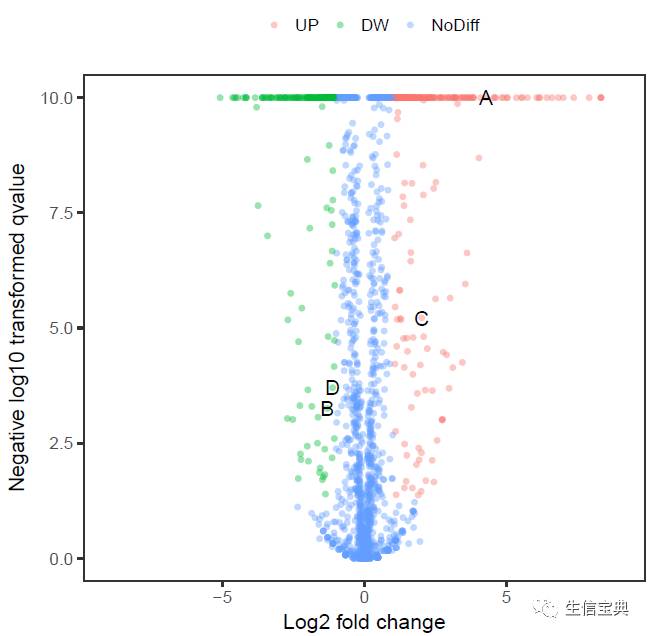
利用现有的数据,基本上就是这个样子了。虽然还不太像,原理都已经都点到了。
盗取火山图绘制一文中的图来显示个真正的火山图吧。这样一步步绘制很麻烦,去看一步法吧。
横纵轴都为字符串的散点图展示
输入数据格式如下
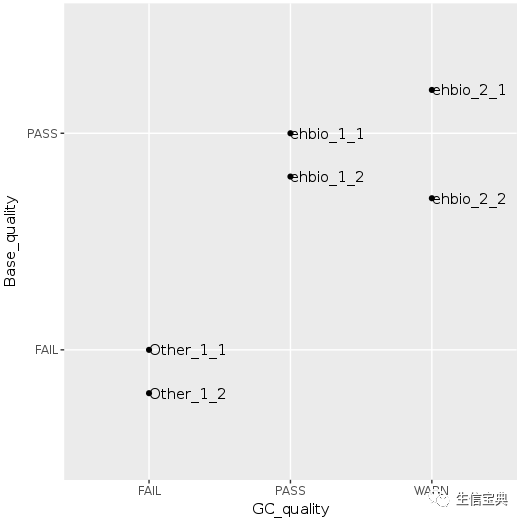
这个数据是前面讲到的FASTQC结果总结中的直观的查看所有样品测序碱基质量和GC含量的散点图的示例数据。
fastqc"ID;GC_quality;Base_quality
ehbio_1_1;PASS;PASS
ehbio_1_2;PASS;PASS
ehbio_2_1;WARN;PASS
ehbio_2_2;WARN;PASS
Other_1_1;FAIL;FAIL
Other_1_2;FAIL;FAIL"
fastqc_data ";", header=T)
p p
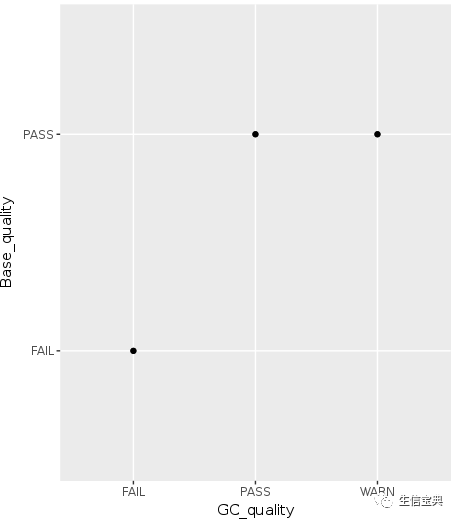
六个点少了只剩下了3个,重叠在一起了,而且也不知道哪个点代表什么样品。这时需要把点抖动下,用到一个包ggbeeswarm,抖动图的神器。
library(ggbeeswarm)
p
p 0, check_overlap=T)
p
一网打进散点图绘制
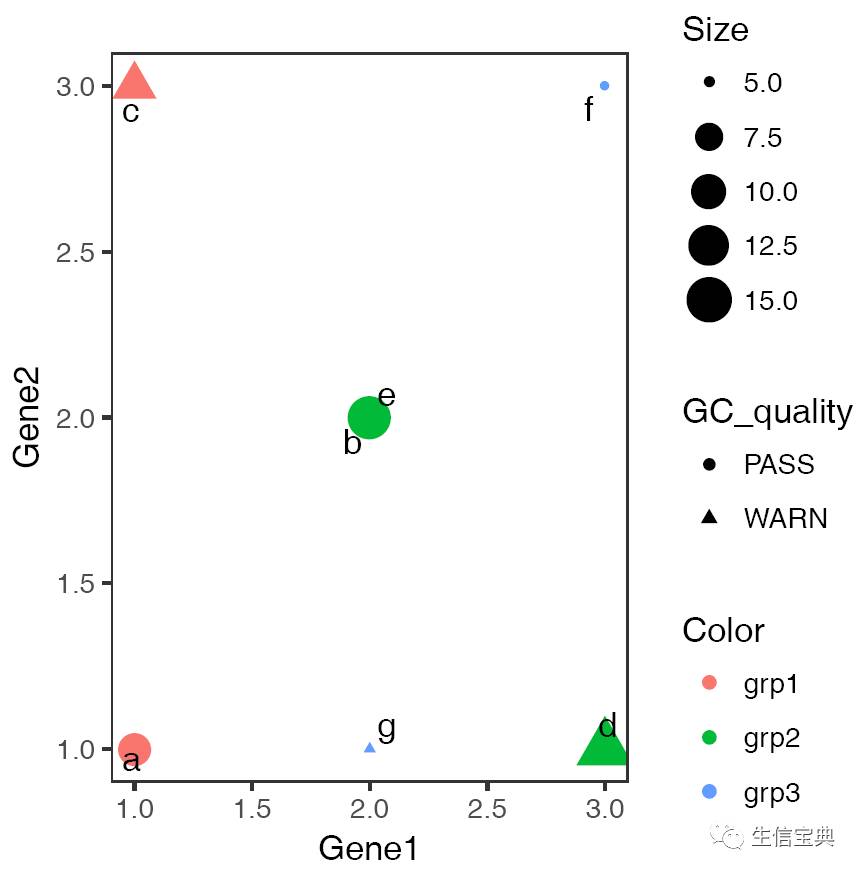
假如有一个输入数据如下所示(存储于文件scatterplot.xls中)
Samp Gene1 Gene2 Color Size GC_quality Base_quality
a 1 1 grp1 10 PASS PASS
b 2 2 grp1 10 PASS PASS
c 1 3 grp1 10 WARN PASS
d 3 1 grp2 15 WARN WARN
e 2 2 grp2 15 PASS WARN
f 3 3 grp3 5 PASS PASS
g 2 1 grp3 5 WARN PASS
想绘制样品在这两个Gene为轴的空间的分布,并标记样品的属性,只需要运行如下命令
sp_scatterplot2.sh -f scatterplot.xls -X Gene1 -Y Gene2 -c Color -s Size -S GC_quality -L Samp -w 10 -u 10
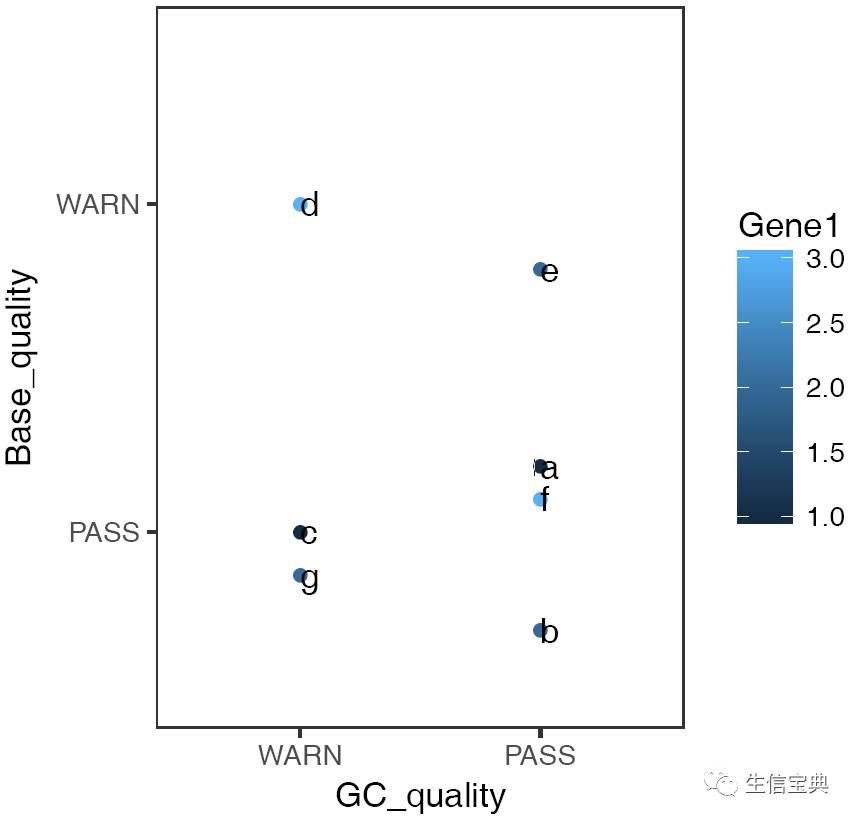
如果横纵轴为字符串,且有重复, 则需指定参数-J TRUE以错开重叠的点,具体如下
sp_scatterplot2.sh -f scatterplot.xls -X GC_quality -Y Base_quality -O "'WARN', 'PASS'" -c Gene1 -w 10 -u 10 -J TRUE -L Samp -Z FALSE
 只有想不到,没有做不到,
只有想不到,没有做不到,sp_scatterplot2.sh还可以完成更多你想做的散点图,而且只需调参数,无需改代码,简单可重用。
+ 转发获取,不用再重复了
R绘图学习
R语言学习 - 入门环境Rstudio
R语言学习 - 热图绘制 (heatmap)
R语言学习 - 基础概念和矩阵操作
R语言学习 - 热图美化
R语言学习 - 热图简化
R语言学习 - 线图绘制
R语言学习 - 线图一步法
R语言学习 - 箱线图(小提琴图、抖动图、区域散点图)
R语言学习 - 箱线图一步法
R语言学习 - 富集分析泡泡图 (文末有彩蛋)
R语言学习 - 火山图
程序学习心得
生物信息之程序学习
如何优雅的提问
文章集锦
Linux学习 R统计绘图 Python教程 Perl学习
生信傻瓜 NGS持续更新中
(链接失效,点击菜单知识库查看)
加入易汉博,人生不白活

关注生信宝典,换个角度学生信

关注宏基因组,再专业一点

Reference










