基于神经网络的人工智能近年取得了突破性进展,正在深刻改变人类的生产和生活方式,是世界各国争相发展的战略制高点。
神经网络作为实现人工智能任务的有效算法之一,已经在各种应用场景获得广泛的应用。从云端到移动端,不同应用场景也对神经网络的计算能力提出了不同的需求。
神经网络的广泛应用离不开核心计算芯片。目前的主流通用计算平台包括CPU和GPU,存在着能效较低的问题(能效即能量效率,是性能与功耗的比值)。为了获得更高的能效,我们需要设计一种专用的神经网络计算芯片来满足要求。国际IT巨头,如英特尔、谷歌、IBM,都在竞相研发神经网络计算芯片。
然而,神经网络的结构多样、数据量大、计算量大的特点,给硬件设计带来了巨大挑战。因此,在设计面向神经网络的高性能、高能效硬件架构时,我们需要思考清楚以下三个问题:
雷锋网本期公开课特邀请到清华大学微纳电子系四年级博士生涂锋斌,为我们分享神经网络硬件架构的设计经验。他将通过介绍其设计的可重构神经网络计算架构 DNA (Deep Neural Architecture),与大家分享在设计神经网络硬件架构时需要思考的问题。他在完成设计的同时,解决了这些问题,并对现有的硬件优化技术做出了总结。
本文根据雷锋网硬创公开课演讲原文整理,并邀请了涂锋斌进行确认,在此感谢。由于全文篇幅过长,分(上)(下)两部分,敬请期待。

各位观众晚上好,我是来自清华大学的涂锋斌,今天非常荣幸收到雷锋网 AI 科技评论的邀请,在此给大家做一节硬创公开课,主题是《设计神经网络硬件架构时,我们在思考什么?》
首先做一个自我介绍。我是清华大学微纳电子系的博士生涂锋斌,今年直博四年级,我的导师是魏少军教授和尹首一副教授,博士课题是高能效神经网络加速芯片设计,研究兴趣包括深度学习,计算机体结构及集成电路设计。

我作为核心架构设计者,完成了可重构神经计算芯片 Thinker 的设计。该芯片作为清华大学代表性成果,参加了 2016 年全国双创成果展,获得李克强总理的高度赞许。相关研究成果已经发表数篇国际顶级会议和权威期刊论文。

本次公开课将从以下五个方面展开。
-
研究背景
我将介绍神经网络的一些背景知识及特点,它们给硬件设计带来哪些挑战?
-
计算模式
从算法和调度的角度分析神经网络需要怎样的计算模式;而基于优化的计算模式,我们需要怎样的架构支持神经网络的计算?
-
架构设计
针对计算模式的需求,如何设计高性能、高能效的神经网络计算架构?可重构神经网络计算架构 DNA(Deep Neural Architecture)具有哪些特点?
-
实验结果
DNA 的性能与能效表现如何?与顶尖工作相比的情况如何?
-
总结思考
针对神经网络硬件架构的设计展开一些思考和讨论。
在经过前面的学术风暴后,我将打开摄像头与大家互动,进入提问环节。
一、研究背景

无处不在的神经网络
随着人工智能时代的到来,图像识别、语音识别、自然语言处理等智能任务在生活中无处不在。而神经网络作为当前实现这类智能任务最有效的算法之一,已经获得广泛的应用。

比方说:
-
百度图片搜索;
-
微软语音识别;
-
谷歌在线翻译;
-
……
可以说,神经网络在我们的生活中真是无处不在。
那么什么是神经网络?我们不妨从神经元开始理解。如图所示,这是一个生物上的神经元。它由树突、细胞体、轴突和神经末梢这四个部分构成。
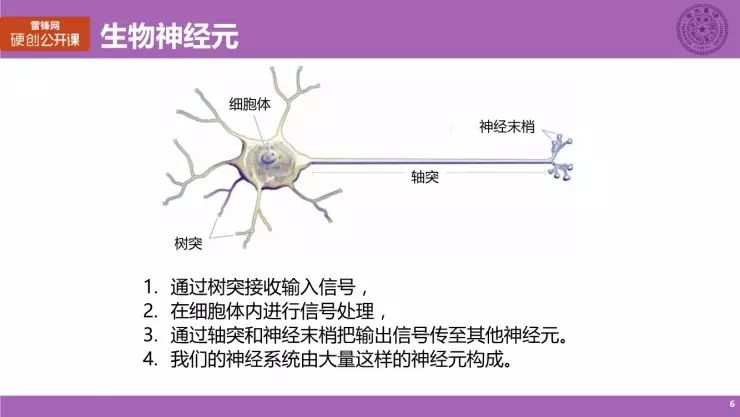
而这就启发了人工神经元模型的诞生。我们可以看到,它的示意图其实与神经元是十分相似的。它仍然由左边的多个输入,经过加权求和与非线性运算得到输出。
一个简单的神经元能做些什么?
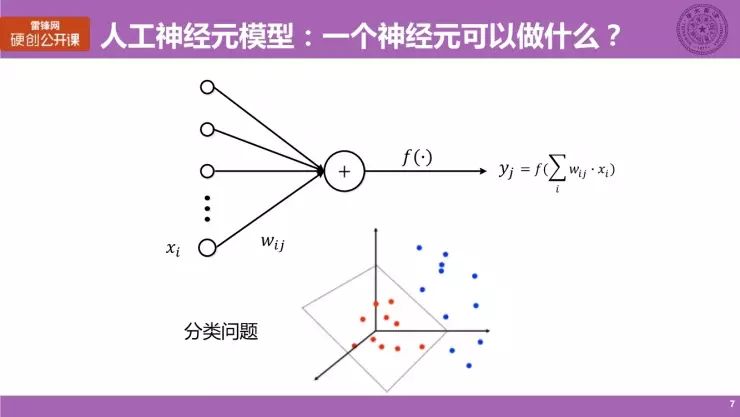
举个简单的例子。在空间中有红色和蓝色两类点。用简单的神经元,我们可以在空间中做一套曲面,将这两类点分开。这就是一个非常简单的分类问题。神经网络/神经元非常擅长用于做分类问题。
那么,当我们有很多神经元后,我们可以得到一个神经网络,它又能用来做什么?
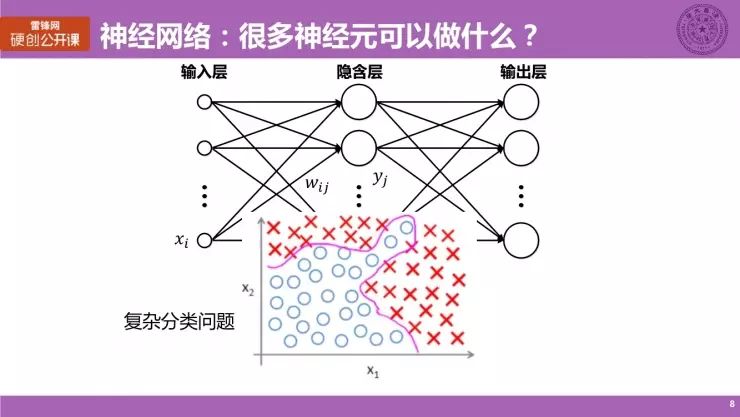
这幅图给出了一个非常简单的典型单层神经网络。其中的每一个圆圈代表一个神经元,它们相互连接,就构成了一个神经网络。一个相对复杂的结构可以做些什么?
如图所示,空间中仍然有红蓝两种颜色的点,我们采用了相对复杂的神经网络,可以在空间中画一条分类的曲面,我们可以看到,问题比刚才的问题难度更大,图中的这条粉色线勾勒出的这条曲面,才能对复杂问题进行分类。
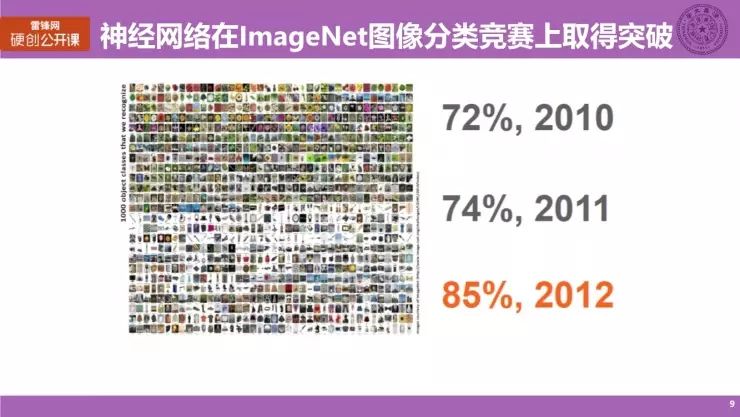
在 2012 年,神经网络 AlexNet 在 ImageNet 图像分类竞赛上取得突破,获得了 85% 的准确率,相较于之前最好的识别率提升了 10% 以上。这是一个非常大的突破,在当时引起了非常广泛的关注。而现在,每年举办的 ImageNet 的识别精确度已经超过了 95%,已经超过人类识别图片的能力。这是一个非常惊人的结果。直至今年,每年拔得头筹的团队都是采用神经网络。
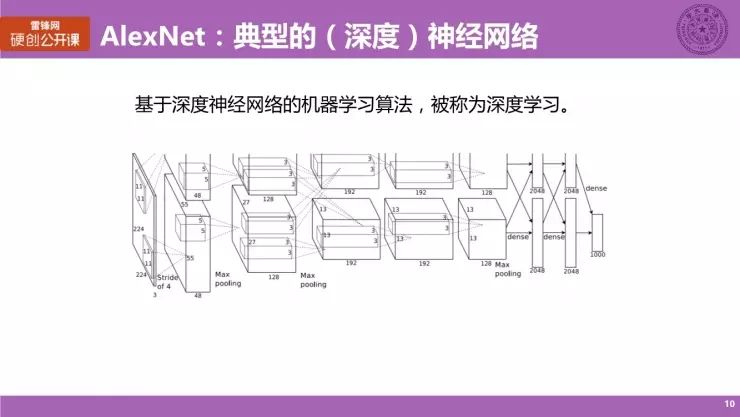
AlexNet 是一个非常典型的、被大家广泛研究的神经网络,因为它的层次很深,共有 8 个层次,人们也称之为深度神经网络,而基于深度神经网络的机器学习算法,我们也给它取了一个非常好听的名字叫「深度学习」。大家经常会在媒体上听到词,其实它的本质依然是神经网络。
各种应用场景对神经网络的需求
而正是因为神经网络如此强大的能力,目前广泛地应用于各种应用场景,例如:

而不同应用场景对神经网络也提出了不一样的计算需求,比如:
现有通用计算平台的不足
然而,现有通用计算平台(CPU、GPU)具有一些不足。

以 CPU 为例,它的性能差,能效低。
能效是能量效率的简称,是性能与功耗的比值。我们通常用 GOPS/W (千兆操作数每秒每瓦) 的单位来描述能效,它是一个非常好地衡量计算效率的指标。
我们这里讨论的能效是考虑了片外存储的系统级能效。后面提及的能效也是指的同一概念。
我们在服务器上做了一个实验,在 CPU 上计算 AlexNet 需要 254.5 ms,相当于处理 4-5 张图片,而功耗需要 80 W,总能效为 0.2 GOPS/W。而同样的情况在 GPU 上计算,总能效为 1.7 GOPS/W,我们希望能效能达到 100 GOPS/W 甚至更高。
神经网络的三大特点
但是,神经网络的三大特点给硬件加速带来巨大挑战。

我们列举了四个非常经典的神经网络,分别是 AlexNet(11 层)、VGG(19 层)、GoogLeNet(22 层)与 ResNet(152 层),我们可以看到,因为识别精度的不同,我们往往会设计更深更复杂的神经网络,会导致网络层次变多,给硬件加速带来很大挑战。

同样以 AlexNet 为例子,神经网络由三种主要层类型组成,包括卷积层(CONV)、池化层(POOL)与全连接层(FC)。图中红框部分即为卷积层,而蓝框部分属于池化层,绿框部分为全连接层。每一层的计算都有些许不同。
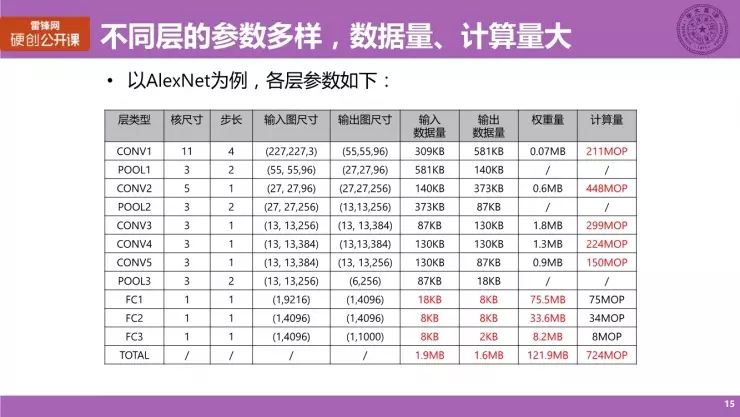
以 AlexNet 为例,最左列呈现了所有层的类型和名字,后面的一系列参数表示它的核尺寸、步长、输入输出图尺寸等。因为参数不同,它们的数据量与计算量都不同,且非常大。
在卷积层上,它的计算量非常大;而全连接层中,计算量相比卷积层稍小,但数据量尤其是权重量则非常大。

这三大特点仍然使硬件加速的实现带来一些挑战。
总体而言,我们需要一个灵活高效的硬件架构支持我们的神经网络。
我们的设计目标和实现

这样一来,我们的设计目标就确定了,即设计一个面向神经网络的高能效计算架构,它需要具备以下三个特点:
在本次公开课里面,我们会以我实现的一个计算架构为设计实例,展开我的一些讨论和思考。
设计实例是一款面向卷积神经网络(CNN)的计算架构,架构的代号叫做「DNA」,它主要具有三大特点:
这就是这款架构的三大特点。
我们设计时思考的问题

在展开我们的讨论之前,也是我们在设计这款架构之前一直在思考的三个问题。要设计好一个架构必须解决这三大问题:
-
问题一:对于神经网络来说,一个好的计算模式究竟是怎么样的?
-
问题二:为了支持的一个计算模式,我们的硬件架构需要怎样去设计?
-
问题三:当我们已经实现了一款硬件架构,在针对具体的算法应用的需求时,我们如何对架构进行配置,使其配置成一个最优的计算模式,满足我们的计算需求?
我们总结的设计理念,也是我们在一直贯彻于设计过程当中的一个理念:
我们认为计算模式与架构的设计是相辅相成的;在设计计算模式的过程中,实际上也是在设计硬件架构,二者是不能完全分开的。
刚刚讲完了研究的一些背景,还有我们一些基础的思考,那么现在,我们会从算法和调度的角度,从算法的硬件用计算模式的角度来进行分析和优化,来看看怎样才是一个好的计算模式。
二、计算模式

研究对象
首先我们要先明确一下我们的研究对象。
在本次公开课里面,我们主要以卷积层的计算为主要的研究对象。有两大原因:
我们详细地来看看卷积层计算。如图所示,是一个卷积层的计算示意图,它的输入是一个 3D 的特征图(Input Map),经过一个 3D 的卷积核(kernel)的扫描,在对应点做一些运算后,就会得到一张输出的 Output Map。我们可以看到,3D 的输入特征图,它总共有 N 个 channel,也就是 N 张特征图。
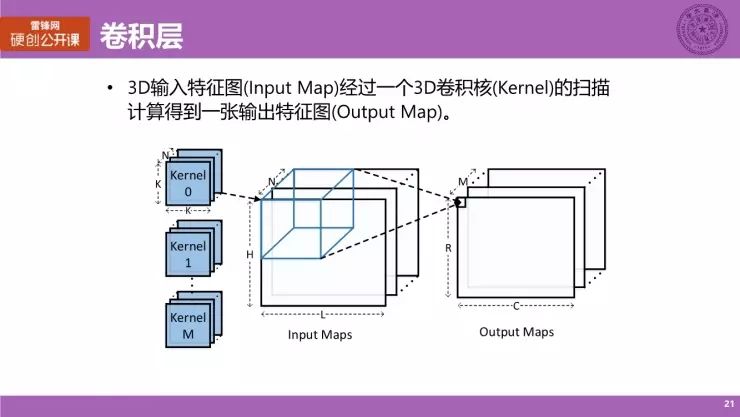
我们总共有 M 个 kernel,经过输入特征图进行计算之后就可以得到 M 张,或者说有 M 个 channel 的 Output Map,就是卷积层的计算。
卷积运算
我们再进一步看下卷积运算又是怎么一回事。
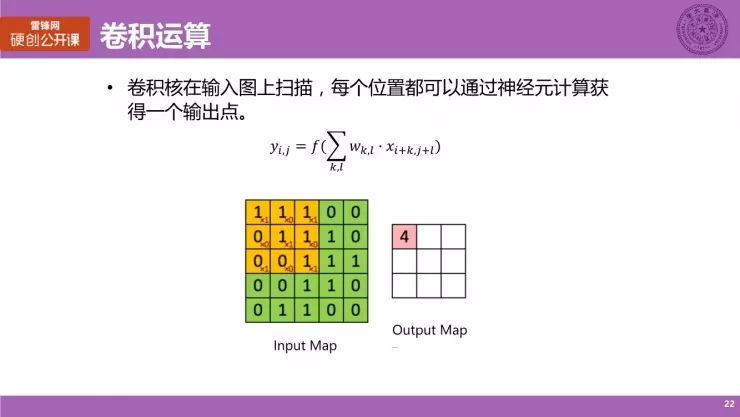
刚刚讲到的卷积核(kernel)会在左边 5×5 的 Input Map 上进行扫描,黄色的方框是一个 3×3 的卷积核。我们可以看到,每一个黄色小框的右下角会有一个权重分析,也就是具体的权重值。卷积核进行扫描的每个位置都会进行神经元的计算,并得到右边 3×3 的 Output Map 上的每一个点。可以看到,随着卷积核在 Input Map 的扫描,就可以得到 Output Map 上的每一个点,而具体的神经元计算其实和我们之前提及的人工神经元模型计算是完全一致的,这就是一个卷积运算的过程。
架构模型
在讲完研究对象之后,我们还要再讲一下架构模型。
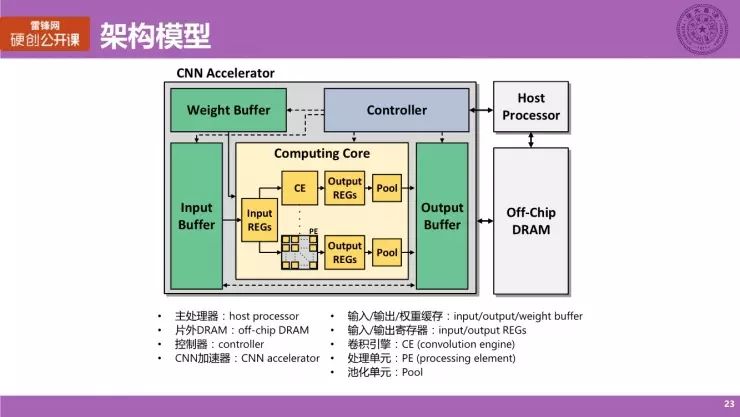
如图所示,这是我们归纳出来的一个神经网络的硬件架构模型,它主要由片上和片外两部分构成。
左边的大矩形就是我们要设计的神经网络硬件架构,而右边架构的外部有一个主处理器和一个片外存储叫做 Off-Chip DRAM,这两个东西是挂载在芯片外部的,而我们主要设计的,就是左边大矩形内部的结构。
在架构里面有一个核心控制器 controller,然后片上通常会有三块 buffer,即 Input Buffer、Output Buffer 及 Weight Buffer,分别存储神经网络的输入数据、输出数据和权重。而中间的黄色部分为 Computing Core 也就是计算核心。
在核心的内部会有一些计算器,比如 Input REGs 与 Output REGs(输入输出寄存器),而最最核心的计算单元就是这里的「CE」它的全称叫做 convolution engine,即卷积引擎或者说计算引擎。输入的数据会经过局部的计算器传输到计算引擎上,而计算机内部再继续剖开,就是一个一个的计算单元,我们称之为 PE,英文叫做 processing element(处理单元),做的是最基本的运算。
神经网络内部最基本的运算是乘加运算,这就是我们最基础的一个硬件架构模型,后面我们的所有讨论都会基于的一个模型来展开。
优化目标
在讲完了我们的硬件架构模型以及研究对象以后,我们还要再讲一讲优化目标。刚刚也提到了两个优化目标,
一个是能效(energy efficiency),另一个是性能。

优化目标 1:能效
刚刚我们也提过,能效的单位是 GOPS/W,表示的是每单位的功耗可以获得怎样的性能,它表征的是一个计算效率的问题。
在公开课里面,我会尽量少用公式做过多的讨论,为了方便大家理解,我经常会用一些例子来解释,但是因为这两个公式非常重要,后面的讨论都是基于它们,所以我必须花一点篇幅来解释。
首先,energy efficiency 是性能与功耗的比值,而性能我们通常用每秒做多少操作数来衡量,即 Operation/T(操作数除以计算的总时间),而 Power 是 Energy/T (总能耗除以时间) 的一个结果,我们可以看到 T 就被约掉了。
而另外我们注意到的一点是,对于神经网络固定的一个算法来说,它的总操作数也是一个固定的值,所以我们首先得到一个结论:
能效值与能耗值是成反比的。那么如果要优化能效,其实我们只需要优化能耗就好了。
我们的能耗越低,那能效也会越高。因此,我们把问题转化成了能耗问题。
我们继续分析能耗。能耗主要由两部分构成。
那么它们分别可以用怎样的形式来建模?我们也分别对这两个式子做一个细致的分析。
访存能耗有片上的存储也有片外的存储,另外就是 MA
DRAM
,也就是 DRAM 的访问次数, 而 E
DRAM
则是单位 DRAM 的访问能耗。二者相乘就得到了 DRAM 的总访问能耗,另外一部分就是访问 buffer 的能耗。
这里的表达式与 DRAM 是类似的,也是由访问次数乘以单位访问能耗构成的,而对于计算的能耗,它是由两个因子来相乘得到的,一个是总的计算操作数 Operation,另外一个就是单位操作能耗 E
operation
,
对于一个给定的 CNN 模型,它的总操作数是固定的,那么我们可以认为总的计算能耗,在单位操作能耗不变的情况下,它也可以认为是一个固定的值,因此,影响能耗的关键因素,就是说对 DRAM 的访问次数以及 buffer 的访问次数。
我们可以看到,能效的优化问题,其实最后就转化为对 DRAM 以及 buffer(注意 buffer 就是片上缓存)的访问次数的优化。如果我们的访问次数很少的话,那么它的能耗就会比较低,能效就会比较高,此后我们就集中对这两个关键因素进行讨论就可以了。
优化目标 2:性能

第二个优化目标是性能。我仍然要具体介绍一个公式。
前面我们提及性能(Performance)的单位是 GOPS,即每秒的操作数,而我们定义了 Performance 的一个公式,由几个因子相乘。
-
第一项是硬件乘加单元数 MAC,我们这里定义为就是硬件上的总的乘加单元的个数或者说基本计算单元的个数。硬件有一个总的计算单元的个数,相当于是一个常量。
-
第二项是计算单元的利用率,简称 PE Utilization,指的是在整个计算的过程当中,硬件计算单元的实际利用率是多高;
-
第三项是计算核心的频率(Frequency),硬件在工作的时候会有一个计算的频率,频率的高低会直接影响到总的性能高低。如果硬件乘加单元数越高,利用率高,计算核心频率高,那么我的总性能肯定是越好的;而对于一个给定的一个硬件架构,影响它的性能的关键因素就是计算单元,在整体的计算工作过程当中,它的利用率是高还是低,PE 越高,它的性能就会越高,这是我们的一个观点。
由此,
我们也同样把性能关键的优化目标转换成能够具体分析甚至可以优化的一个对象,叫做 PE Utilization,也就是我们计算资源的利用率。
我们简单总结一下,刚刚分别讨论了两个重要的优化目标,分别是能效和性能。通过对能效和性能的表达式的分析,我们将分别从访存次数 MA 以及计算单元的利用率 PE Utilization 这两个角度,对计算模式进行优化。
到此为止,我们对研究对象、目标的架构以及优化目标都做了非常细致的分析,那我们就可以展开讨论了。

在设计里面,我们采用一种逐层加速的策略来针对层数不同的神经网络,因为刚刚也提到,神经网络本身的计算量非常大,特别是在现在网络层次越来越深的情况下,基本上不太可能在硬件上直接把一个神经网络直接映射到一个硬件上去做计算,所以我们采用一种大家现在惯常使用的计算方法,叫做逐层加速,即一层一层的来计算神经网络,最终得到输出结果。
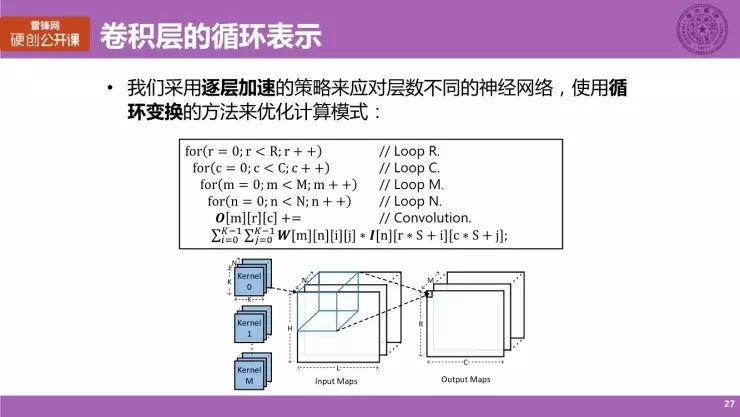
我们的核心方法是使用循环变换的方法来优化其计算模式,图中的代码其实表示的就是一个卷积层的计算,它是由四层循环来表示的,其中 R、C、M、N 还有 K,这些参量都是和之前提到的基本卷积层计算参量是一一对应的。
我们通过对循环进行优化,实际上就可以把它转换成对神经网络特别是卷积层的计算模式优化,并采用循环变换一个很好的方法,对计算模式进行优化。
那么什么叫做计算模式?我们仍然是结合之前的架构图来介绍。
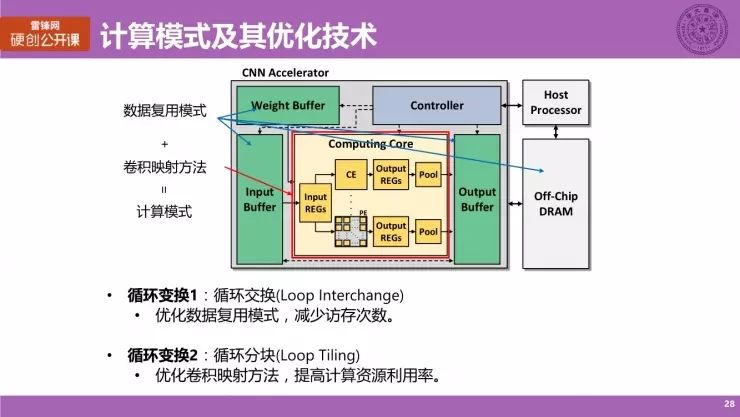
计算模式主要由两部分来构成。
二者构成的就是数据传输及计算映射,或者构成了一个整体,也就是计算模式,而我们的分析都会针对这两个部分分别展开。
我们在这里主要采用两类循环变换方法。
值得注意的是,访问次数以及计算资源利用率,就是我们刚刚提炼出来的、需要主动优化的两类主要参量,它们会直接对应到性能和能耗这两个优化目标。
数据复用模式
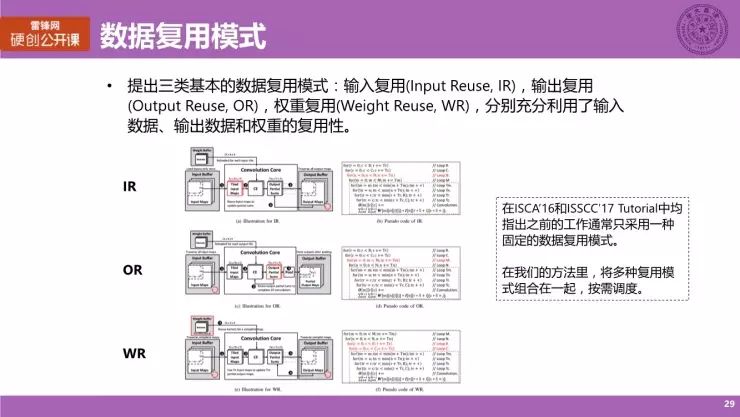
首先我们来讲讲数数据的复用模式。
在我们的工作当中,我们提出了三类基本的数据的复用模式,分别是:输入复用(Input Reuse,IR)、输出复用(Output Reuse,OR)、权重复用(Weight Reuse,WR),他们分别充分地利用了输入数据、输出数据及权重的复用性,我们给出了三种基本复用模式的示意图以及对应的伪代码,这里就不做特别细致地展开了。
需要值得一提的是,在我们领域的两个顶级会议上,即 ISCA 16 以及 ISSCC 17 的 Tutorial 上均指出之前的工作都只采用一种固定的数据复用模式。我们在后面的分析会告诉大家,采用固定的服务模式并不是一种特别好的策略。
在我们的方法里面,我们将多种数据复用模式组合在一起,按照具体的计算以及算法的需求来进行调度,这是我们的一个核心想法。
这里会结合输入复用(Input Reuse)来做稍微细致一点的分享,但不会涉及到过多的数学或者说特别细致的代码讲解。
对于输入复用来说,我们这里有一个简单的示意图,中间还是一个计算核心,而围绕在旁边的还是片上的 buffer,所谓的输入复用表示的是,,我们读取一部分存储在 Input Buffer 里面的数据,放到计算核心内部,再对这些输入的数据进行充分的复用。具体来说,我们会读入 T
N
个小的 map,在核心内部会做充分的计算,将这一层对应的 M 个 map,即所有和它相关的输出数据都遍历一遍,把对应的计算都完成。在这个过程中计算核心需要与片上的 Output Buffer 进行频繁的交互,与此同时,权重 Buffer 也需要有频繁的访问。但是因为在过程中我对输入数据进行了充分的复用,所以我们在这种模式下面对于输入数据,它仅仅需要从 Input Buffer 里面导入一次,导入到 Core 内部就好了。
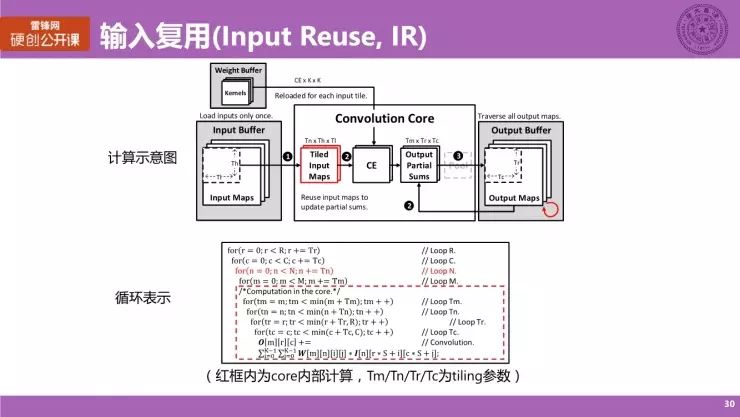
这个过程叫做输入复用,所对应的循环表达就是下面一个式子,不做具体的展开。我们可以看到,红色虚线框的这部分就是核心内部完成的计算,而输入复用对应的一种循环表达,其实是对外部的四层循环做一个次序的调整,就是我之前提到的循环次序调换,而其中涉及到的 T
m
、T
n
、T
r
、T
c
,分别对应的是之前提到的 M、N、R、C。我们这里称为 Tiling 参数,因为核心内部的局部存储非常有限,所以我们将 Input Buffer 内部的这些数据和权重导入到核心内部的时候就要做一个分块,也就是说我计算任务是一部分一部分来完成的,采用这样一种方式完成整个的计算任务。而刚提到的 Output Reuse 与 Weight Reuse,它其实所改变的就是外部存储循环的计算次序,也就是 Loop Interchange。
针对这样的数据复用方式,我们会展开一些分析。
访存分析模型
我们之前有提到,我们需要分析的是它的访存的总能耗是怎么样的,其中的一个关键因素就是访问次数(Memory Access)如何,简称 MA,是由这样一个公式来得到的。

至于公式 TI、TO、TW 只是当前层的输入、输出和权重的总量,TPO 表示的是当前层的最终输出数据总量,它是一个常数;α
i
、α
o
、α
w
对应的就是输入输出权重的复用因子,我就不过多解释了。
这里我们直接上结论,对于片上 buffer 的访问来说,因为是输出复用,所以 αi 是 1,但是输出和权重需要多次的访问,所以它们会乘上一个大于 1 的一个因子,是由 Tiling 参数和计算参数决定的;而对于低端的访问,它是一个相对复杂一点的公式,主要体现在 αo 和 αw 上,它是一个与片上缓存容量相关的一个表达形式,但因为是输入复用,所以其复用次数仍然是 1(用红色表示)。对于输入复用来说,访问是 1,我们可以很容易地推测出来。
对于输出数据还有权重来说,它的访问次数也应该是最小的,这里我就不做过多的展开了。
能耗分析模型
那我们有了一个能效访问次数的分析模型之后,就能以此做一个能耗的分析模型,公式也很简单,我们之前已经详细的讨论过了。而我们也提到,计算能耗是一个固定的值,因此会着重对访存能耗进行分析,而用刚刚的访存分析模型,我们已经得到了最低端访问次数的模型(红色部分)和 buffer 的访问次数模型,那么单位的 DRAM 的访存和 buffer 的访存分别是怎样一个值?其实这和具体的设计有关,我们也会做一些实验。

在我们的设计中,对于 DDR3 的,因为每个 Dram 的单位访存能耗是 70pj/bit,而片上 buffer 的单位访存能耗是 0.42pj/bit。我们其实对访存能耗式子中的每一个项都做了非常精确的一个刻画,那么,我们通过一个能效的分析模型就可以评估出不同的计算模式,在不同的参数上面它的能耗是多大,这样就能我们的优化目标挂钩了。
AlexNet CONV3 的访存分析
我们这里做一个简单的分析,用 AlexNet 的 CONV3 做一个访存次数的分析。我直接给了一个分析的图,这里简单解释一下,横坐标是 Tiling 的参数,左边纵坐标是片上 buffer 的总次数,而三个颜色的柱子分别对应的是 IR、OR 与 WR,表示它们在不同的 Tiling 参数的访存次数,为了方便我们直接来看比较结果。
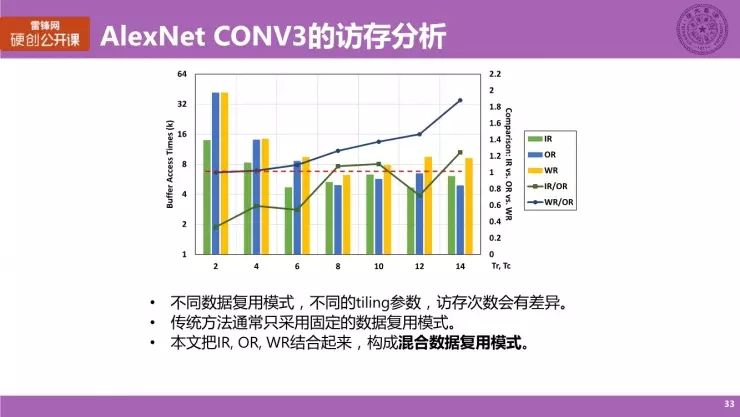
这三种基本的计算模式,它们两两作比得到的比值如图。这里红色的曲线表示是已知唯一的一个基准线,
首先,对于不同的数据复用模式以及不同的 Tiling 参数来说,访存次数是有差异的,而在不同的情况下,最好的数据复用模式也会有所不同。
其次,传统的或者是当下的工作通常采用一种相对固定的数据复用模式,
而在我们的工作里,我们将三种基本的数据复用模式结合起来,构成一种混合的数据复用模式,根据具体情况来选择最优的一种模式。
刚刚讲完的数据复用模式,是计算模式很重要的一个部分,那么现在我们来简单讲讲卷积映射方法。我们仍然以一个实际例子来简明地给大家解释一下。
卷积映射方法
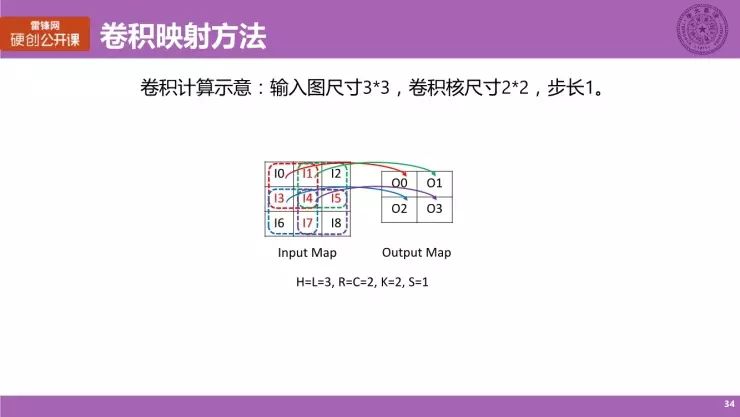
这是卷积计算的一个示意图,有一个 3×3 的一个 Input Map,kernel 的大小是 2×2,然而卷积的步长是 1,那么就经过一个卷积之后得到结果它是一个 2×
2 的 Output Map,而这里彩色的箭头表示就是说对于每一个 Output Map 上的点,它所对应的输入数据来自哪一个区域,具体来说就是说对于 Output Map 的 O0 点,它所需要的数据是 I0、I1、I3 和 I4,而对于 O1 点来说,他的数据是 I1、I2、I4 和 I5 这四个点。
我们可以看到,这四个输出点,它们所对应的输入数据的范围是相互覆盖的,我们看到是 I1、I3、I4、I5 和 I7 这五个点,它们是处于重叠部分的一个区域。就是说,实际上这些点在计算的过程中是存在数据复用的。数据复用就是说数据可以重复利用。比如说,用于 O0 点的计算的数据是可以给到 O1 点进行计算的,即 I1 和 I4,其他的也是类似原理,也就是它存在数据复用的一个机会。
这里我们就给出大家经常使用的一种卷积映射方法,仍然以刚刚卷积的例子为例,但我们会结合具体的一个硬件结构,CE(计算引擎)的尺寸是 2×2,意味着它内部有 2×2 总共四个 PE(最基本的计算单元)构成,而这幅图给出来的是一个卷积映射方法的具体过程。
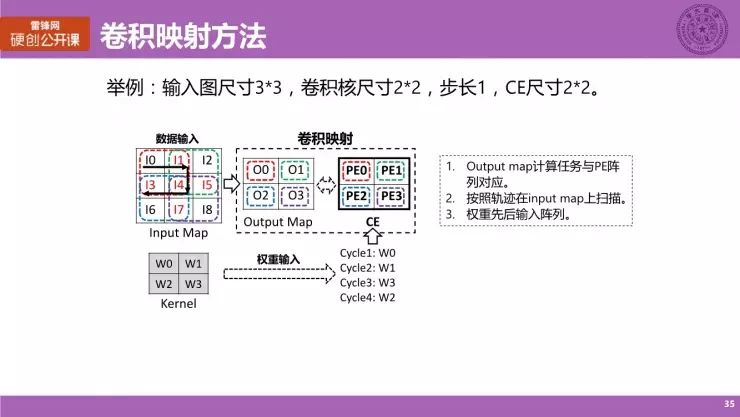
首先,对于 Output Map 上的四个点,计算任务与 PE 2×2 的阵列是对应的,我们这里就是你看就是 O0 点的计算任务会映射到 PE0 的计算单元上,其他三个点也以此类推,意味着对于某一个 PE 来说,所需要承担的计算就是对应点所需要进行的计算。特别强调一点,所谓的计算任务(乘加计算过程)也就是在上面完成。
第二个要点,输入输入数据会按照如图所示的一个轨迹(一个 S 形的折线轨迹)进行扫描,最开始输入的是左上角的四个点(I0、I1、I3 和 I4),通过扫描 PE0 上的数据,比如 I1 和 I4,会传递到 PE1 上,然后通过扫描将外部数据送入到 PE 内部,数据两两之间又会进行一个数据传递,就用到了我们刚刚所提到的数据复用的机会。
第三点,对于权重来说,它紧跟着输入数据的节拍,先后输入阵列,整体的过程就是卷积映射的方法,这个方法是一个非常经典的、大家通常会使用的方法。在现有很多的当前的工作中都采用类似的一些方法,比方说像一些利用阵列形式计算的硬件架构都会通常采取类似的方法,当然在细节上会稍许的不同,不过基本上的原理是类似的。
但刚刚讲的映射方法仍然存在一些问题,主要是因为计算参数的多样性会导致计算资源利用率的问题。我刚才提到,利用计算资源利用率和性能会直接挂钩,具体来说它主要有两方面因素的影响,
具体来说,仍然以实例讲解一下。卷积步长如果大于 1,这里以卷积步长为 2 作为例子,PE 的阵列规模是 8×8,要计算的是 4×4 的一个 Output Map。再用刚刚的方式进行计算,实际发挥有效计算的 PE 其实是 1357 这些点(红色区域)。也就是说,间隔的点会做一些有效计算,而灰色的点虽然实际也在工作,但是它并没有做有效的计算,所计算出来的数据并不是我们所需要的。
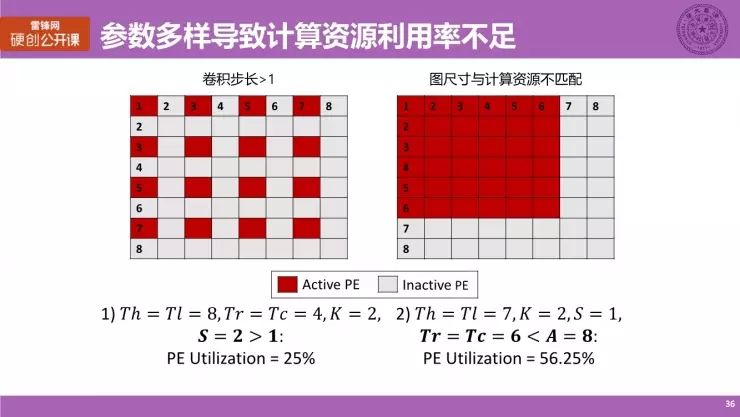
在这个例子里,PE 的利用率仅仅只有 25%,这是比较低的一个数字。
第二点,从我们计算的图的尺寸,特别是 Output Map 的尺寸,它会与计算资源的规模以及形态会不匹配,具体来说,如果要计算一个 6×6 的一个图,但是我的阵列大小是 8×8。显而易见的,只有 6×6 部分他做了有效的计算,而其余的边缘部分并没有做有效的阶段,甚至直接没有用。这样的话,我们计算出来的利用率仅仅只有 56.25,将近一半的计算资源没有用上,实在太可惜了。
因此我们希望在计算过程当中,计算资源可以一直工作,或者说它的利用率尽可能接近百分之百,就能达到很高的一个利用率以及性能,这是我们希望看到的。
并行卷积计算方法
我们提出一种叫做「并行卷积计算方法」的一种映射方式,大家看这个图就很容易明白。因为这个方法本身的概念上其实很容易理解。
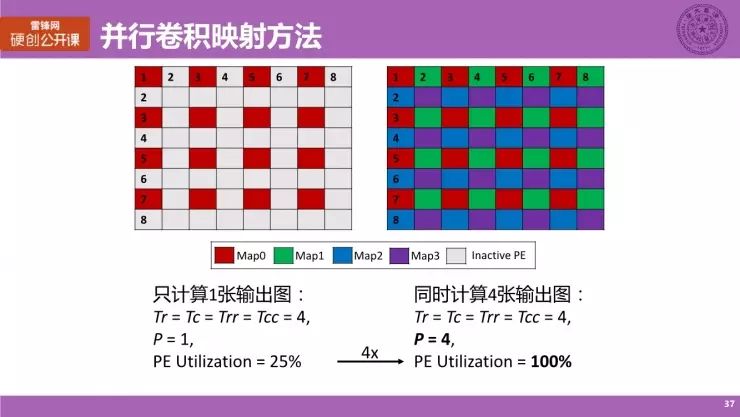
左边是刚刚讲的例子,采用我们方法后,我们试图在阵列上面同时计算四张 Map,利用率能从 25% 提升到将近 100%,这是一个很好的计算结果,它的并行度能提升四倍,那主要是因为我们同时计算四个 Output Map。值得一提的是 Output Map 所需要用到的输入数据其实是一样的,或者说它们的数据是共享的,这也就直接指导了我们后面的硬件架构设计。
第二个例子,我们仍然使用并行卷积映射的方法,虽然处理方式有所不同,但是概念上还是非常接近的,为了解释方便,我们这里换了一种表达的形式。
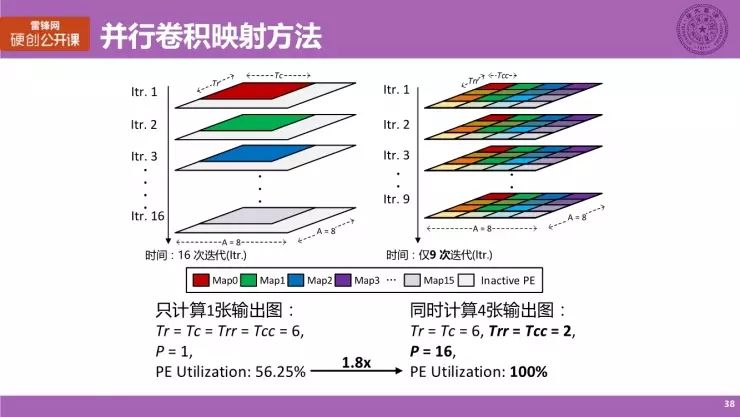
这里我们给出时间轴上的一个展开图,左边是传统的情况,右边就是用我们的方法之后的一种情况,简单来说,传统方法是在 8×8 的阵列上计算 6×6 的输出图,如果要计算 16 张不同的 Map(用不同颜色表示),那我们总共需要 16 次迭代,我们可以认为一次迭代代表一次时钟周期,那么 PE 的利用率只有 56.25%。
我们采取了另一个操作,对每一个 map 做一个更深层次的一个 Tiling,分块地将一个 6×6 的块分割成一个一个 2×2 的小块,把 16 张 Map 的 2×2 小块映射到阵列上面。也就是说,我们同时在一个阵列上计算 16 个运行的 Map,但是每个 Map 尺寸更小,那么我计算完一张 map 的迭代次数只有 9 次,原来是 6×6,现在是 2×2,我只要 9 次迭代就可以完成,但是因为其他的 map 都是并行计算,所以其他的计算也可以同时完成。这样的一种方式将原来的计算的 16 次迭代就缩短为 9 次迭代,PE 利用率接近 100%。
另外值得一提的是,这些不同的 Map 所需要的数据仍然是共享形式,这一点之后我们会提到。

我们提出一种并行卷积映射方法,这个公式与传统卷积映射方法公式有些许的改变,主要体现在引入了一个更深层次的 Tiling 参数 Trr 和 Tcc,在分子上面引入了一个并行的因子 P。
主要的核心思想就是通过并行地计算更多的输出图,以获得更高的计算资源应用率。在核心内部的计算过程,我们另外引入两层 Tiling 来实现并行操作。
以上为硬创公开课上集,下集敬请关注AI科技评论。
AI科技评论招业界记者啦!
在这里,你可以密切关注海外会议的大牛演讲;可以采访国内巨头实验室的技术专家;对人工智能的动态了如指掌;更能深入剖析AI前沿的技术与未来!
如果你:
*对人工智能有一定的兴趣或了解
* 求知欲强,
具备强大的学习能力
* 有AI业界报道或者媒体经验优先
简历投递:
[email protected]






