转自订阅号「AIOps智能运维」,已授权运维帮转发
作者简介:运小贝,百度高级研发工程师
负责百度内网质量监测平台(NetRadar)的业务端设计及开发工作。在系统和网络监控、时序指标异常检测、智能客服机器人等方向有广泛实践经验。
本系列文章的上篇:
《
百度网络监控实战:NetRadar横空出世(上)
》
对百度内网质量监测做了初步介绍。作为该系列文章的下篇,本文将从核心功能、设计框架、异常检测策略以及可视化视图四个方面进一步介绍百度内网质量监测平台—
NetRadar
。
在上一篇文章中我们提到,为了回答关于内网质量的问题,监测平台需要能够执行按需监测以及持续监测两种类型的测量任务。此外,为了实现主动告警以及故障可视化,还要求监测平台能够对测量结果进行分析,并明确告知是否有网络故障。因此,
NetRadar
平台包含两大核心功能:
监测任务的可定制与持续执行
以及
测量结果的智能分析
。
监测任务要求
NetRadar
架构具备两个特性:
持续监测和按需监测要求每一台服务器都必须能够参与测量。
Controller负责统一协调控制Agent执行各种监测任务。
那么,
NetRadar
的系统架构具体是怎样设计的呢?
NetRadar
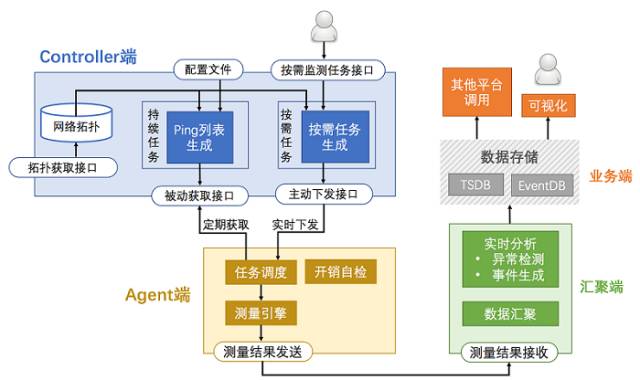
整体系统结构如图1所示,主要包括Controller端、Agent端 、汇聚端及业务端四个部分。其中Controller和Agent负责执行监测任务并获取测量数据,汇聚端负责数据的汇总和分析,业务端则展示分析结果并向其它平台提供数据。
图
1
NetRadar
系统结构图
Controller 是测量子系统的核心,负责持续测量任务和按需测量任务的管理和调度。
Controller 根据任务配置和网络拓扑结构生成每个 Agent 的探测目标,即每个 Agent 的 ping 列表。Agent采用
pull
模式定期获取该列表的内容。
用户提交任务后,Controller 根据网络拓扑信息将任务拆解为每个Agent需要执行的测量任务,并采用
push
模式
将任务内容推送
给对应的Agent。
Agent 根据Controller下发的测量任务执行测量操作,并把测量结果发送给汇聚服务器。测量操作包括
ICMP ping
,
TCP ping
,
traceroute
等。
另外,由于 Agent 部署在线上服务器,需要避免干扰线上业务的正常执行,所以Agent 需要不断检查自己消耗的系统资源,当资源使用超标时停止执行新的探测任务。我们对
CPU
、
内存
、
磁盘
等资源消耗进行限制。
汇聚端的功能主要有以下两点:
由于QoS队列、协议以及统计方式的不同,每对服务器之间的网络测量可以生成
27
种网络性能指标(如图2所示)。另一方面,我们还需要将服务器之间的测量数据按照网络拓扑结构汇聚为反映
ToR
之间、
机房内集群
之间、
机房
之间的网络质量指标。最终,整个系统会产生达
百万
级别的质量指标。
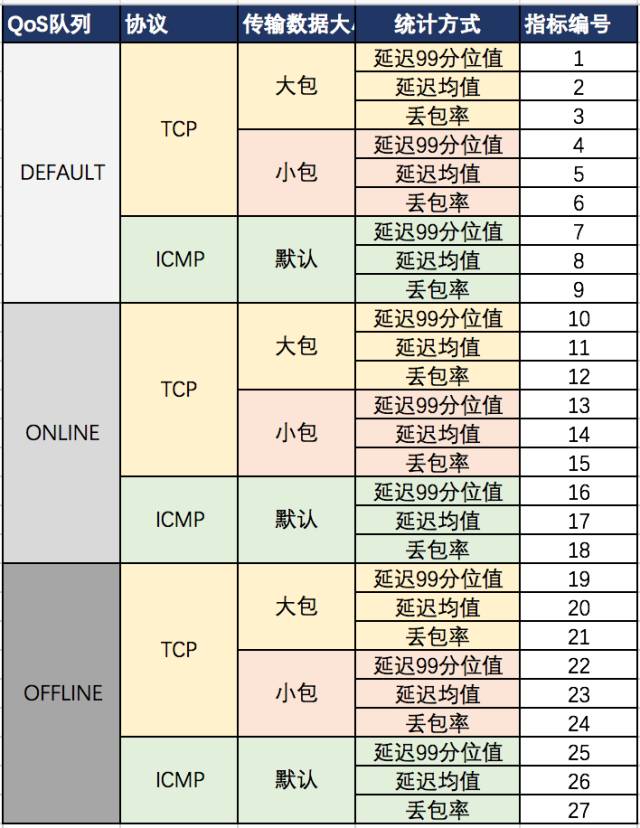
图2 27种监控指标
为了降低资源消耗,并提高可用性,采用“
Adaptor-Aggregator多个实例、两层汇聚
”的方式进行汇聚,如图3所示。

图3 Adaptor-Aggregator两层汇聚设计图
Agent优先(随机)选择本地域内的一个Adaptor来发送数据,并在本地域以及其他地域各选择一个Adaptor作为备选,当主Adaptor失效时依次选择备选Adaptor。另外,Adaptor收到数据后,采用一致性哈希的方式根据数据的“汇聚key”进行汇聚,并将汇聚结果发送给Aggregator,由Aggregator进行最终的汇聚。
这样做的好处是可以将汇聚计算的压力分散在Adaptor和Aggregator模块,同时降低了汇聚数据到Aggregator的资源消耗。
在完成指标数据汇聚后,汇聚端直接进行异常检测,并判断是否有故障发生。如果确定网络故障发生,则向相关人员和系统发送警报。
业务端将汇聚端生成的指标数据和监测到的故障时间分别保存在
TSDB
和
EventDB
中,用于可视化展示或提供给其他平台使用。
TSDB
和
EventDB
是百度运维内部成熟的数据存储平台。其中,
TSDB
主要用于存储时间序列数据,适合存储指标数据;
EventDB
主要用于存储事件类型数据,适合存储故障事件数据。
另外,业务端还通过分析不同业务线所部署服务在网络拓扑中的位置,得到业务线网络拓扑,从而实现按业务线定制化展示以及进行网络故障通告的功能。
测量子系统所生成网络质量指标多达
百万
级别,不可能通过人工监视的方式发现网络故障,因此需要能够自动运行的异常检测策略。指标的数量巨大,表现也有很大的差异,这就要求异常检测策略是通用的、低开销的、高鲁棒性的。
NetRadar





