

内容来源:2017年6月25日,美团云架构师滕传永在“美团云技术沙龙——千万日订单背后的电商运维实战·上海站”进行《如何做troubleshooting》演讲分享。IT大咖说作为独家视频合作方,经主办方和讲者审阅授权发布。
阅读字数:2533 | 5分钟阅读
摘要
troubleshooting是找到问题发生的根源并将其解决更正的过程,目标就是使设备或系统回到正常的工作状态。很多系统都是24 小时不间断运行的,一旦发生故障,就要求运维人员很快发现故障,并用快速经济的办法解决故障。所以troubleshooting对于运维人员来说是一项非常重要的技能。
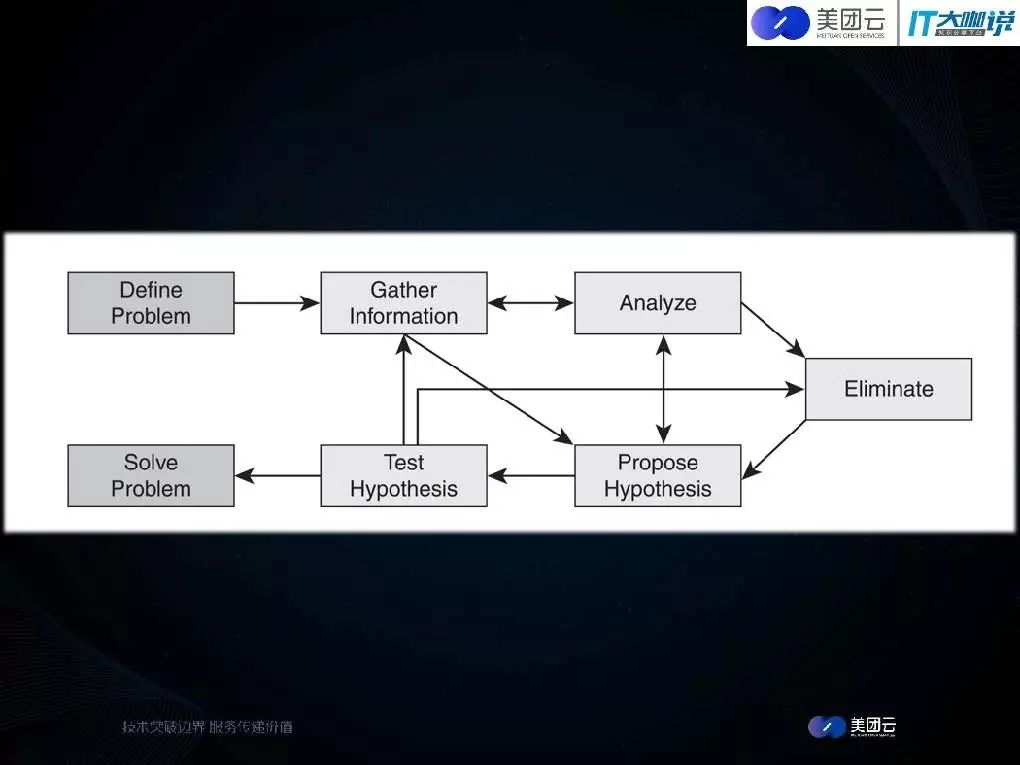
把troubleshooting的过程抽象成七个步骤,每个步骤有一定的前后依赖关系。首先定义遇到的故障问题,确定是否发生故障。确定后从故障的表现或系统内外部依赖的系统和日志等各方面收集更多的信息。通过这些信息去做下一步归纳整理和分析,然后逐步定位到故障发生在哪个子系统或模块。经过前面几个步骤分析后做一些推断,排除一些可能发生故障的部件,并在此基础上做做假设。例如假设系统有A、B、C三个模块组成。可能A和这个case关系比较大,B和C的关系不是那么大可以排除,故障就能逐步定位到A,并在此基础上对A进行进一步分析或替换去进行测试,看系统是否恢复到正常的状态。如果系统恢复到正常状态那么这个case就得到了完美的解决,如果没有恢复则说明之前的推断是有问题的,就要回到前面的步骤做更多的信息收集来判断分析,重新进行推断和测试。理论上来说,无论多复杂的系统都可以用这个标准的流程去做troubleshooting。
可能这个case大家都有遇到过,就是电脑或电灯开不了,检查后发现是电源没有插好。这个case提醒我们如果系统出现了异常,在系统排查的过程中要去查一下系统运行的时候依赖于哪些外部条件,或外部上下游的依赖。我们用的系统、商用软件往往会提供非常完善的用户手册,用户手册里会列出系统依赖需要哪些条件,如果缺少这些条件系统运行就会不正常。
在工作中我们可能会接触到一些公司自研的或第三方提供的系统。这些工具和系统因为是定制化开发,往往没有那么成熟,这种情况下如果发生了问题,排查会相对困难一些。所以我们需要和软件提供方根据软件的工作流程挖掘一下在系统运行中有哪些条件需要满足。
在系统异常的过程中,首先要排查一下先决条件是否被满足。
第二个case在我工作过程中遇到过好多次,就是故障发生的时候往往是这个系统运行了很长时间、做过多次变更,和初次上线的时候已经有了巨大的差别。利用troubleshooting的方法去排查会花费很多时间,这时我们可以尝试把所有配置进行初始化,看它能否正常运行,就能排除相关因素。

很多复杂的路由协议其实都是做了一些平时用不上或者不是决定性的功能。把这些功能都排除后再看网络本身的连通性好不好,以此判断系统是否处于正常状态。
在我之前的公司有一个规定,运维的系统经过一段时间如果没有重启的话,就需要做一个计划性的重启。通过重启可以排除很多外部的影响性因素,让系统恢复到原始状态。
在使用这个方法的时候要先评估系统重启会不会发生其它问题产生额外的影响,我们对这些影响是否有充足的解决方法去应对。
在一个复杂的系统下可能会同时发生多个问题,很难判断哪个问题起到了关键性作用。这个时候重装也许是一个更有效率的方式。
在座很多程序员应该都有装电脑的经历。一台完整的PC电脑有很多组件,专业装电脑的高手一开始并不是把整个电脑的所有组件按顺序完完全全地组装起来,再测试电脑是否能正常工作。而是在装电脑的过程中只需要把主板、CPU和内存这个最经典的系统装上电源尝试点亮。如果能顺利点亮,就说明电脑整体上是没有太大问题的,再把它们其它的外设装到机箱里。
从装电脑的例子中可以发现一个方法,在troubleshooting一个很复杂的系统的时候,可以先屏蔽一些除核心功能之外的附加组件,检查核心系统是否出现问题。如果核心系统正常,再检查其余的附加组件。
有一些故障是显而易见的。

例如上图中车的右后轮是有问题的,那么在troubleshooting过程中会针对性地将这个故障进行替换。
但有一些系统故障发生的时候是很隐蔽的,通过外部故障难以判断是哪个系统导致的。这时即使是按照子系统一步步排查也只能替换一个部件,而不是把所有部件全部替换。如果还是没有效果,对于这个部件所做的操作和变更都要回复到故障之前的状态,再重新进行下一步的诊断。
在操作过程中,顺序非常重要。不同的操作顺序会带来不同的结果。

如图可见,这个系统分为三部分。最前面是Web Server用于接收用户的请求并做一些基本的处理。处理完之后真正的应用和业务逻辑通过Web Server转发到App Server,App Server进行请求和业务处理。用户相关数据和业务数据都是在后端的DB Server里。
在这个case过程中突然发现这种系统是不正常的,我们的运维人员就对这组系统进行了重启。重启时发现系统无法正常启动,当时用了更换顺序的方法,把三个逻辑的业务单元分别做了重启,每次重启都会使用不同的顺序。最终得到了图中的结果。
根据这个结果我们后来又做了进一步调查发现,是因为App Server的启动要依赖于它后端的数据库,如果数据库没有正常启动的话,App Server的启动就失败了,不会再接着进行下一个初始化。
正常的启动顺序是先启动DB Server,再启动Web Server或App Server。









