随着复杂和高效的神经网络架构的出现,卷积神经网络(CNN)的性能已经优于传统的数字图像处理方法,如 SIFT 和 SURF。在计算机视觉领域,学者们开始将研究重点转移到 CNN,并相信 CNN 是这一领域的未来趋势。但是,人们对成效卓著的 CNN 背后的机理却缺乏了解。研究 CNN 的运行机理是当今一个热门话题。基本上,有三种主流观点:1>优化、2>近似、3>信号。前两种观点主要集中在纯数学分析,它们试图分析神经网络的统计属性和收敛性,而第三种观点信号尝试解决以下问题:1)为什么非线性激活函数(activation function)对所有中间层的过滤式输出(filter output)是必不可少的?2)双层级联系统(two-layer cascade system)比单层系统的优势在哪里?
球面修正相关性(REctified COrrelations on a Sphere/RECOS)
众所周知,前馈神经网络(FNN)可以被看作是一个万能的近似器,在给定包含有限数量神经元的单个隐藏层的情况下,它能够近似任何连续的函数。FNN 的特殊之处在于神经元的非线性激活函数。有的神经网络庞大且深度,但如果离开非线性激活函数,它们的复杂架构的效果与一个简单的单层线性模型没什么不同,都是将输入映射到另一个输出空间。具体来说,非线性激活函数学习到的输入的表征集合更适合解决实际问题。
CNN 只是 FNN 或 MLP(多层感知器/perceptron)的另一种类型。为了分析 CNN 的非线性,作者提出了一个数学模型来理解 CNN 的行为。在模型中,CNN 被视为由基本操作单元组成的一个网络,它们计算「球面修正相关(RECOS)」。因此,它被称为 RECOS 模型。在 CNN 训练期间,首先初始化核权重,然后通过梯度下降法(gradient descent)和反向传播(back propagation)算法进行调整。在 RECOS 模型中,权重被称为锚向量(anchor vector),以表示它们在聚类输入数据中的作用。也就是说,我们试图计算输入向量和锚向量之间的相关性,然后测量其相似度。
为什么用非线性激活函数?
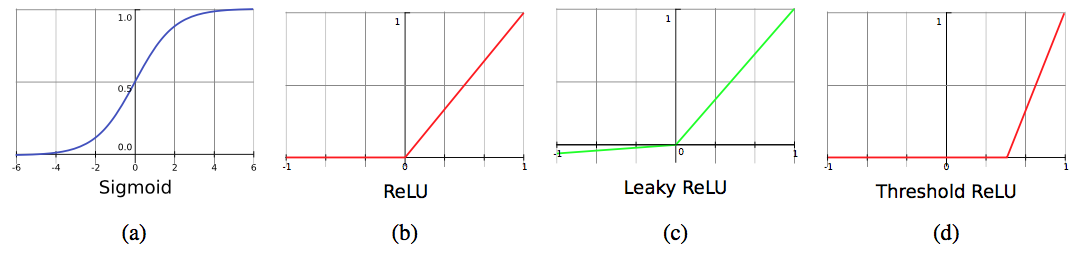
与 MLP 仅用 1 步考虑所有像素的交互作用不同,CNN 将输入图像分解成较小的图像块(patch),在某些层中又被称为节点的感受域(receptive field)。算法逐渐扩大感受域的范围以覆盖更大的图像。神经元计算输入向量与其锚向量之间的相关性,以测量它们的相似度。每个 RECOS 单元中有 K 个神经元。我们将模型表示为 Y = AX,其中 X 是输入向量,Y 是输出向量,A 是我们的锚向量(核过滤器(kernel filter)的权重矩阵)。这个方程表示 CNN 将输入映射到另一个空间。通过研究 RECOS 模型,我们可以立即得出结论:学习到的核权重倾向于将相似的对象映射到同一个区域。例如,如果 x_i 与 x_j 的欧式距离相近,则相应的输出 y_i 和 y_j 在新空间中也必须相近。对于用于捕获猫的特征的过滤器,学习到的锚向量 A 将所有代表猫特征的向量 X_cat 映射为 Y_cat,而其它代表狗特征的向量 X_dog 或代表车特征的向量 X_car 将永远不会出现在这个区域。这就是 CNN 能够有效识别不同对象的原因。

但为什么我们必须使用非线性激活函数?考虑上面两幅图像:(左)原始的猫图像,(右)左图像的负片。从人的角度判断,这两个图像可以是一样的,但也可以是不同的。我们可以得出结论,两幅图中的猫是相同的猫,并且它们是负相关的。因为黑猫只是通过从白猫图像的像素值减去 255 来获得。那么 CNN 如何理解这两只猫呢?
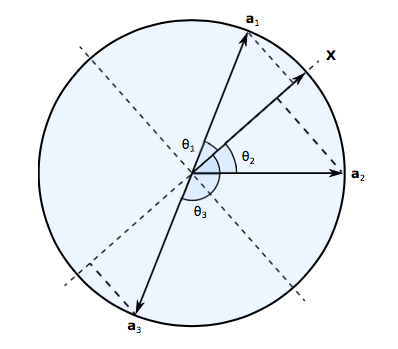
从上图中,我们可以看到使用非线性激活函数的必要性。X 是输入向量,a_1、a_2 和 a_3 是学习到的不同的锚向量。在 RECOS 模型中,线性运算 Y = AX 用于测量输入向量和锚向量之间相似度。因此,对于锚向量 a_1 和 a_3,可以看到 x 与两个锚向量之间的相似度在幅度上是相同的,但是符号相反。此时,对于 CNN 来说猫是不同的。但是例如在有两个卷积层的 LeNet5 中,当原始输入 x 通过两层之后,最终的输出结果将会被混淆:以下两种情况不能被没有非线性激活函数的系统正确区分:1)第一层的正响应遇到第二层的负过滤权重;和 2)第一层的负响应遇到第二层的正过滤权重。然而,通过使用非线性激活函数,CNN 可以很容易地排除负值的影响,从而得到鲁棒的系统。
此外,作者还进行了一个有趣的实验,结果如下:
我们用 MNIST 训练集训练了 LeNet-5 网络,在 MNIST 测试集上得到了 98.94% 的正确识别率。然后,我们将这个 LeNet-5 网络应用于如图 5 所示的灰度反转的测试图像。准确率下降为 37.36%。接下来,我们将 conv1 中的所有过滤权重改为负值,同时保持网络的其余部分不变。经过微修改的 LeNet-5 网络对灰度反转测试集的正确识别率为 98.94%,而原始测试集的准确率下降为 37.36%。
可以看到,改变第一个卷积层中的所有过滤权重将得到对称的结果。该结果表明,引入激活函数将消除负相关关系,若我们在学习灰度反转图像的特征时不仅保留学习原图像的锚向量同时加入灰度翻转图像的锚向量,则对两个测试集均能够达到高识别效果。
级联层的优势是什么?
通常来讲,随着 CNN 层数的深入,核函数会试图基于所有之前核函数的输出来构建自己的抽象特征。所以相比浅层,深层可以捕捉全局语义和高级特征。在 RECOS 模型中,CNN 利用与测量相似度类似的一系列非线性变换来逐层聚类相似的输入数据。输出层预测所有可能决策(如,对象的类)的似然值。训练样本含有图像与其决策标签之间的关系,并能够帮助 CNN 生成更适合的锚向量(从而形成更好的聚类),最终将聚类数据与决策标签联系起来。

上图显示了深度网络的有效性,实验细节如下:
我们用一个例子来说明这一点。首先,我们通过在 MNIST 数据集的原始手写数字上随机添加 10 个不同的背景来修改 MNIST 的训练集和测试集。对上面的三行图像,每行最左边的列显示 3 个数字图像输入,中间列是分别来自卷积层和 ReLU 层的 6 个谱图像(spectral image)输出,最右边两列是分别来自卷积层和 ReLU 层的 16 个谱图像输出。由于背景的多样性,难以为第一层找到的良好的锚向量矩阵。然而,这些图像的背景在空间域中是不一致的,而它们的前景数字是一致的。
对于不同的变形背景,CNN 成功地捕捉到了代表性模式。值得注意的是,第一层含有很多冗余和无关的信息,通过在级联层运用特征提取,CNN 学习到了全局样式而不是局部细节。也就是说,对于输入向量 x,RECOS 变换产生一组 K 个非负相关值作为 K 维度的输出向量。这种方式实现了逐层重复聚类。最后,训练图像的标签帮助 CNN 在不同背景的图像中找到相同的模式。
从上面的分析可以看出,卷积层模型对于自动选择特征是很有用的。它能在没有人工干预的情况下测量输入数据的相似性并将其聚类到不同区域。
那么完全连接层的作用是什么?
通常 CNN 被分解为两个子网络:特征提取(FE)子网络和决策(DM)子网络。FE 子网络由多个卷积层组成,而 DM 子网络由几个完全连接层组成。简而言之,FE 子网络通过一系列 RECOS 变换以形成用于聚类的新表征。DM 子网络将数据表征与决策标签联系起来,它的作用与 MLP 的分类作用类似。
到这里我们可以得出结论,CNN 比计算机视觉中经典的机器学习算法要好得多。因为 CNN 可以自动提取特征并且基于这些特征学习分类输入数据,而随机森林(RF)和支持向量机(SVM)则非常依赖于特征工程,而这种特征工程往往很难操作。
结论
总而言之,RECOS 模型用信号分析的角度为我们剖析了卷积神经网络。从这个角度来看,我们可以看到激活函数和深度架构的有效性。然而,以下几个方面仍需要重点研究:网络架构设计、弱监督学习、对错误标签的鲁棒性、数据集偏差和过拟合问题等。 
论文:Understanding Convolutional Neural Networks with A Mathematical Model(请点击阅读原文)
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]









