
数据挖掘入门与实战 公众号: datadw
二元决策树就是基于属性做一系列的二元(是/否)决策。每次决策对应于从两种可能性中选择一个。每次决策后,要么引出另外一个决策,要么生成最终的结果。一个实际训练决策树的例子有助于加强对这个概念的理解。了解了训练后的决策树是什么样的,就学会了决策树的训练过程。
代码清单6-1为使用Scikitlearn的DecisionTreeRegressor工具包针对红酒口感数据构建二元决策树的代码。图6-1为代码清单6-1生成的决策树。
代码清单6-1 构建一个决策树预测红酒口感-winTree.py
import urllib2
import numpy
from sklearn import tree
from sklearn.tree import DecisionTreeRegressor
from sklearn.externals.six import StringIO
from math import sqrt
import matplotlib.pyplot as plot
#read data into iterable
target_url = ("http://archive.ics.uci.edu/ml/machine-learning-"
"databases/wine-quality/winequality-red.csv")
data = urllib2.urlopen(target_url)
xList = []
labels = []
names = []
firstLine = True
for line in data:
if firstLine:
names = line.strip().split(";")
firstLine = False
else:
#split on semi-colon
row = line.strip().split(";")
#put labels in separate array
labels.append(float(row[-1]))
#remove label from row
row.pop()
#convert row to floats
floatRow = [float(num) for num in row]
xList.append(floatRow)
nrows = len(xList)
ncols = len(xList[0])
wineTree = DecisionTreeRegressor(max_depth=3)
wineTree.fit(xList, labels)
with open("wineTree.dot", 'w') as f:
f = tree.export_graphviz(wineTree, out_file=f)
#Note: The code above exports the trained tree info to a
#Graphviz "dot" file.
#Drawing the graph requires installing GraphViz and the running the
#following on the command line
#dot -Tpng wineTree.dot -o wineTree.png
# In Windows, you can also open the .dot file in the GraphViz
#gui (GVedit.exe)]
图6-1为针对红酒数据的训练结果,即一系列的决策。决策树框图显示了一系列的方框,这些方框称作节点(nodes)。有两类节点,一种针对问题输出“是”或者“否”,另外一种是终止节点,输出针对样本的预测结果,并终止整个决策的过程。终止节点也叫作叶子节点(leaf)。在图6-1中,终止节点处在框图底部,它们下面没有分支或者进一步的决策节点。
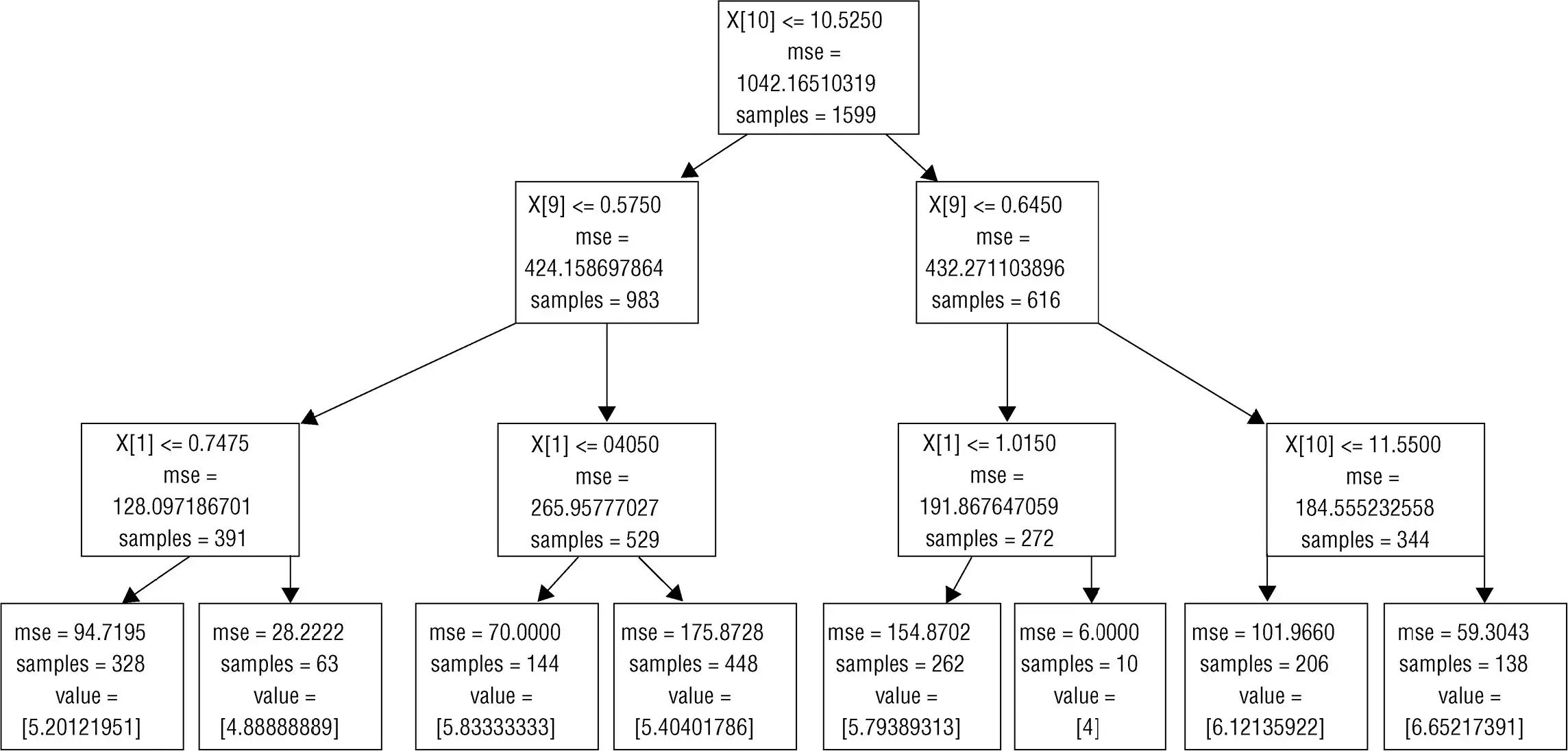
图6-1 确定红酒口感的决策树
1.1 如何利用二元决策树进行预测
当一个观察(或一行数据)被传送到一个非终止节点时,此行数据要回答此节点的问题。如果回答“是”,则该行数据进入节点下面的左侧节点。如果回答”否“,则此行数据进入节点下面的右侧节点。该过程持续进行,直到到达一个终止节点(即叶子节点),叶子节点给该行数据分配预测值。叶子节点分配的预测值是所有到达此节点的训练数据结果的均值。
尽管此决策树的第二个决策层在两个分支中都考虑了变量X[9],这两个决策也可以是针对不同属性所做的判断(可以参看第三个决策层的例子)。
最上面的节点又叫根节点(root
node)。这个节点提出的问题是“X[10]<=10.525”。在二元决策树中,越是重要的变量越早用来分割数据(越接近决策树的顶端),因此决策树认为变量X[10],也就是酒精含量属性很重要。这点决策树与第5章的惩罚线性回归是一致的。第5章“用惩罚线性方法构建预测模型”也认为酒精含量是决定红酒口感最重要的属性。
图6-1所示决策树的深度为3。决策树的深度定义为从上到下遍历树的最长路径(所经过的决策的数目)。在“决策树的训练等价于分割点的选择”小节的关于训练的讨论中,可以看到没有理由要求到达终止节点的所有路径具有相同的长度(见图6-1)。
现在已经知道一个训练好的决策树是什么样的,也看到了如何使用一个决策树来进行预测。下面介绍如何训练决策树。
1.2 如何训练一个二元决策树
了解如何训练决策树最简单的方法就是通过一个具体的例子。代码清单6-2为给定一个实数属性如何预测一个实数标签的例子。数据集在代码中产生(也叫作合成数据)。生成过程是把−0.5~+0.5等分成100份,单一实数属性x就是这些等分数。标签y等于x加上随机噪声。
代码清单6-2 简单回归问题的决策树训练-simpleTree.py
import numpy
import matplotlib.pyplot as plot
from sklearn import tree
from sklearn.tree import DecisionTreeRegressor
from sklearn.externals.six import StringIO
#Build a simple data set with y = x + random
nPoints = 100
#x values for plotting
xPlot = [(float(i)/float(nPoints) - 0.5) for i in range(nPoints + 1)]
#x needs to be list of lists.
x = [[s] for s in xPlot]
#y (labels) has random noise added to x-value
#set seed
numpy.random.seed(1)
y = [s + numpy.random.normal(scale=0.1) for s in xPlot]
plot.plot(xPlot,y)
plot.axis('tight')
plot.xlabel('x')
plot.ylabel('y')
plot.show()
simpleTree = DecisionTreeRegressor(max_depth=1)
simpleTree.fit(x, y)
#draw the tree
with open("simpleTree.dot", 'w') as f:
f = tree.export_graphviz(simpleTree, out_file=f)
#compare prediction from tree with true values
yHat = simpleTree.predict(x)
plot.figure()
plot.plot(xPlot, y, label='True y')
plot.plot(xPlot, yHat, label='Tree Prediction ', linestyle='--')
plot.legend(bbox_to_anchor=(1,0.2))
plot.axis('tight')
plot.xlabel('x')
plot.ylabel('y')
plot.show()
simpleTree2 = DecisionTreeRegressor(max_depth=2)
simpleTree2.fit(x, y)
#draw the tree
with open("simpleTree2.dot", 'w') as f:
f = tree.export_graphviz(simpleTree2, out_file=f)
#compare prediction from tree with true values
yHat = simpleTree2.predict(x)
plot.figure()
plot.plot(xPlot, y, label='True y')
plot.plot(xPlot, yHat, label='Tree Prediction ', linestyle='--')
plot.legend(bbox_to_anchor=(1,0.2))
plot.axis('tight')
plot.xlabel('x')
plot.ylabel('y')
plot.show()
#split point calculations - try every possible split point to
#find the best one
sse = []
xMin = []
for i in range(1, len(xPlot)):
#divide list into points on left and right of split point
lhList = list(xPlot[0:i])
rhList = list(xPlot[i:len(xPlot)])
#calculate averages on each side
lhAvg = sum(lhList) / len(lhList)
rhAvg = sum(rhList) / len(rhList)
#calculate sum square error on left, right and total
lhSse = sum([(s - lhAvg) * (s - lhAvg) for s in lhList])
rhSse = sum([(s - rhAvg) * (s - rhAvg) for s in rhList])
#add sum of left and right to list of errors
sse.append(lhSse + rhSse)
xMin.append(max(lhList))
plot.plot(range(1, len(xPlot)), sse)
plot.xlabel('Split Point Index')
plot.ylabel('Sum Squared Error')
plot.show()
minSse = min(sse)
idxMin = sse.index(minSse)
print(xMin[idxMin])
#what happens if the depth is really high?
simpleTree6 = DecisionTreeRegressor(max_depth=6)
simpleTree6.fit(x, y)
#too many nodes to draw the tree
#with open("simpleTree2.dot", 'w') as f:
# f = tree.export_graphviz(simpleTree6, out_file=f)
#compare prediction from tree with true values
yHat = simpleTree6.predict(x)
plot.figure()
plot.plot(xPlot, y, label='True y')
plot.plot(xPlot, yHat, label='Tree Prediction ', linestyle='–')
plot.legend(bbox_to_anchor=(1,0.2))
plot.axis('tight')
plot.xlabel('x')
plot.ylabel('y')
plot.show()
图6-2为属性x和标签y的关系图。正如预期,y值大致上一直跟随x值变化,但是有些随机的小扰动。
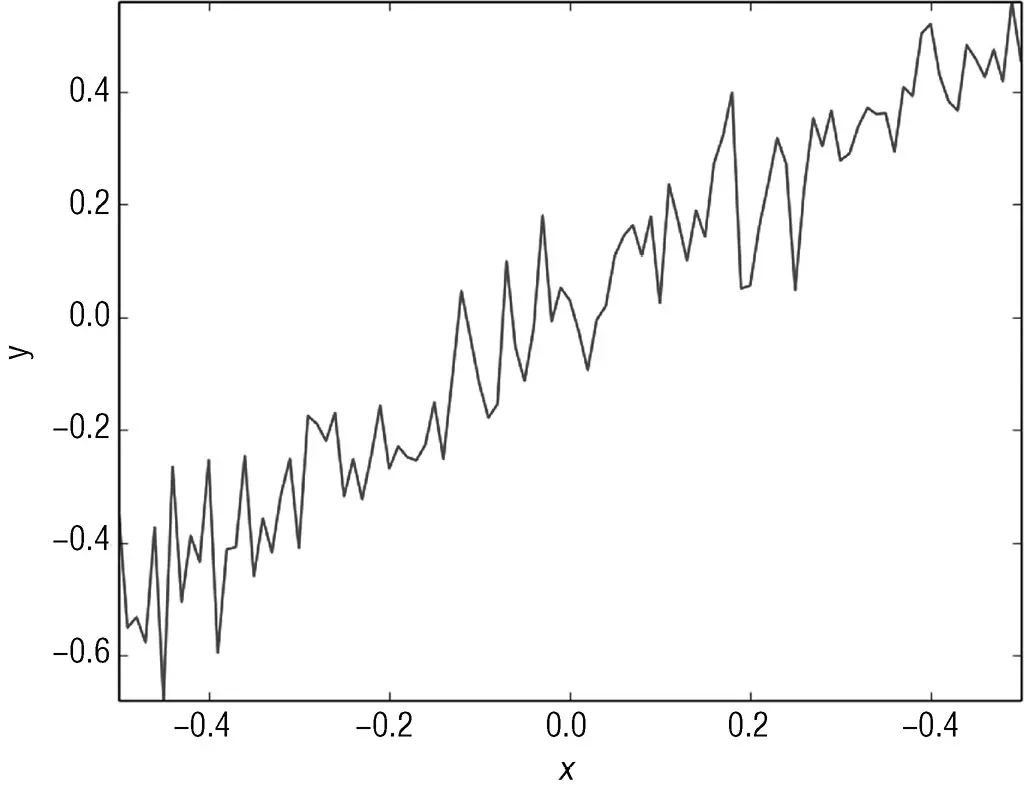
图6-2 标签与属性的关系图
1.3 决策树的训练等同于分割点的选择
代码清单6-2的第一步是运行scikitlearn的regression
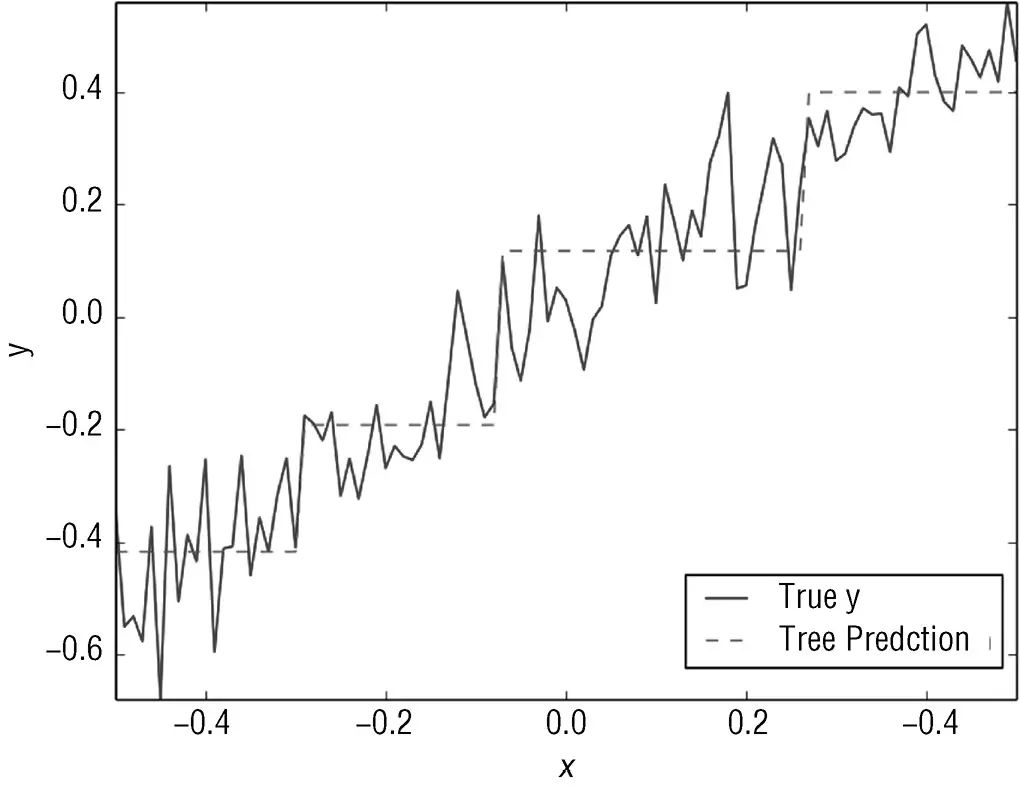
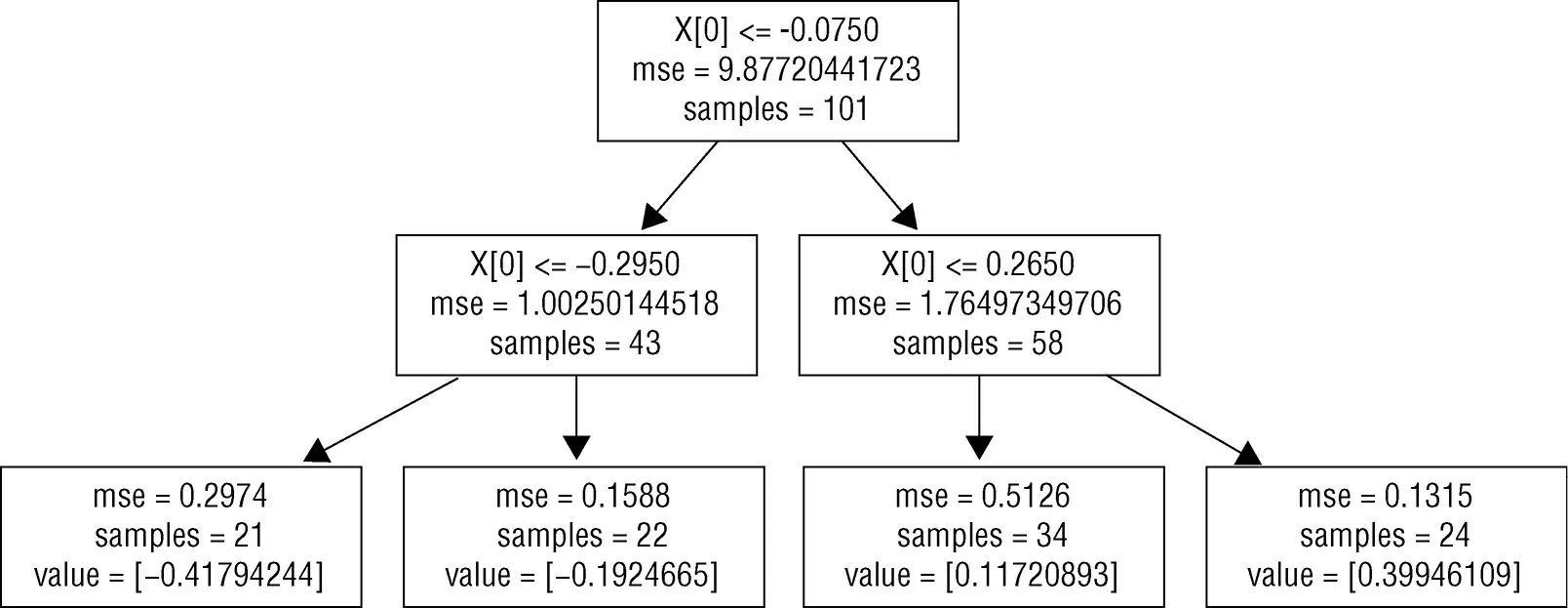
tree包,并指定决策树的深度为1。此处理过程的结果如图6-3所示。图6-3为深度为1的决策树的框图。深度为1的树又叫作桩(stumps)。在根节点的决策就是将属性值与−0.075比较。这个值叫作分割点(split
point),因为它把数据分割成两部分。由根节点发散出去的两个方框可知,101个实例中有43个到了根节点的左分支,剩下的58个实例到了根节点的右分支。如果属性值小于分割点,则此决策树的预测值就是方框里指明的值,大约就是−0.302。
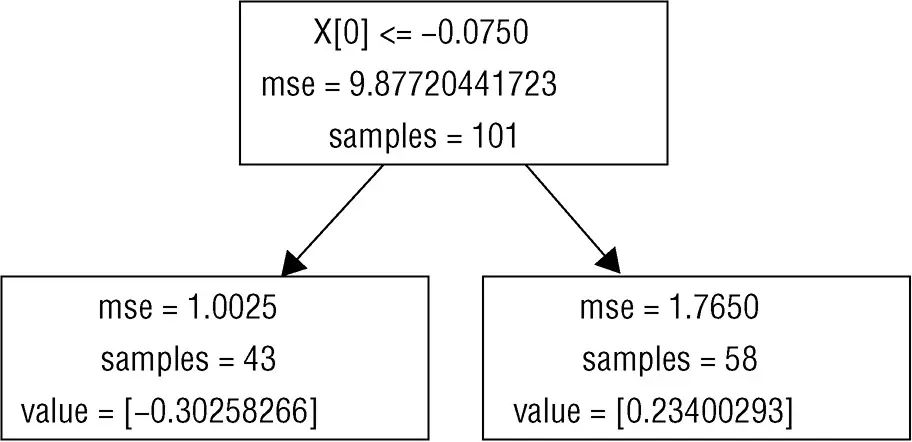
图片 15{61%}
图6-3 一个简单问题的解:深度为1的决策树的框图
分割点的选择如何影响预测效果
审视决策树的另一个方法就是将预测值与真实的标签值进行对比。这个简单的合成数据只有一个属性,由决策树产生的预测值一直跟随着实际的标签值,从中也能看出这个简单的决策树的训练是如何完成的。如图6-4所示,预测的值是基于一个简单的判断方法。预测值实际上是属性值的阶梯函数。这个“阶梯”就发生在分割点。
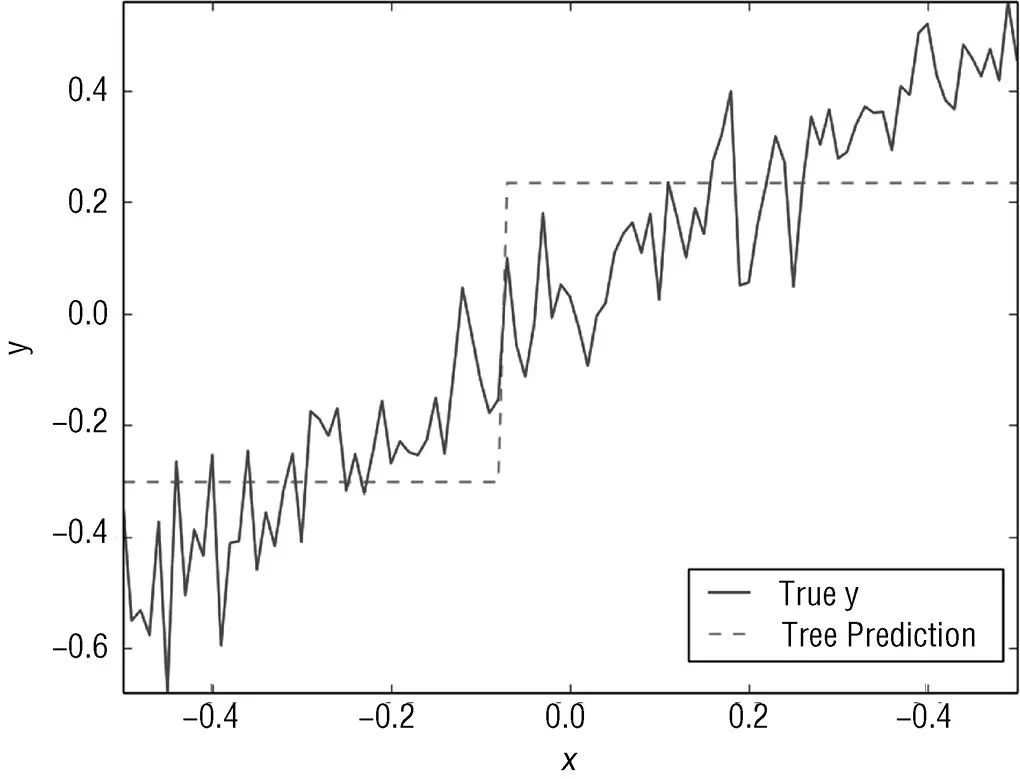
图6-4 预测值与实际值的比较
分割点选择算法
这个简单的决策树需要确定3个变量:分割点的值、分割后生成的两组数据的预测值。决策树的训练过程就是要完成这个任务。下面介绍上述目标如何达到。训练此决策树的目标是使预测值的误差平方最小。首先假设分割点已经确认。一旦给定分割点,分配给两个组的预测值就可以确定下来。分配的值就是使均方误差最小的那个值。那么剩下的问题就是如何确定分割点的值。代码清单6-2有一小段代码用来确定分割点。这个过程是尝试每一个可能的分割点,然后把数据分成2组,取每组数值的均值作为分配的预测值,然后计算相应的误差平方和。
图6-5展示了误差平方和作为分割点的函数是如何变化的。大概在数据的中心,可以明确地取到最小的误差平方。训练一个决策树需要穷尽地搜索所有可能的分割点来确定哪个值可以使误差平方和最小化。这是这个简单的例子需要注意的地方。
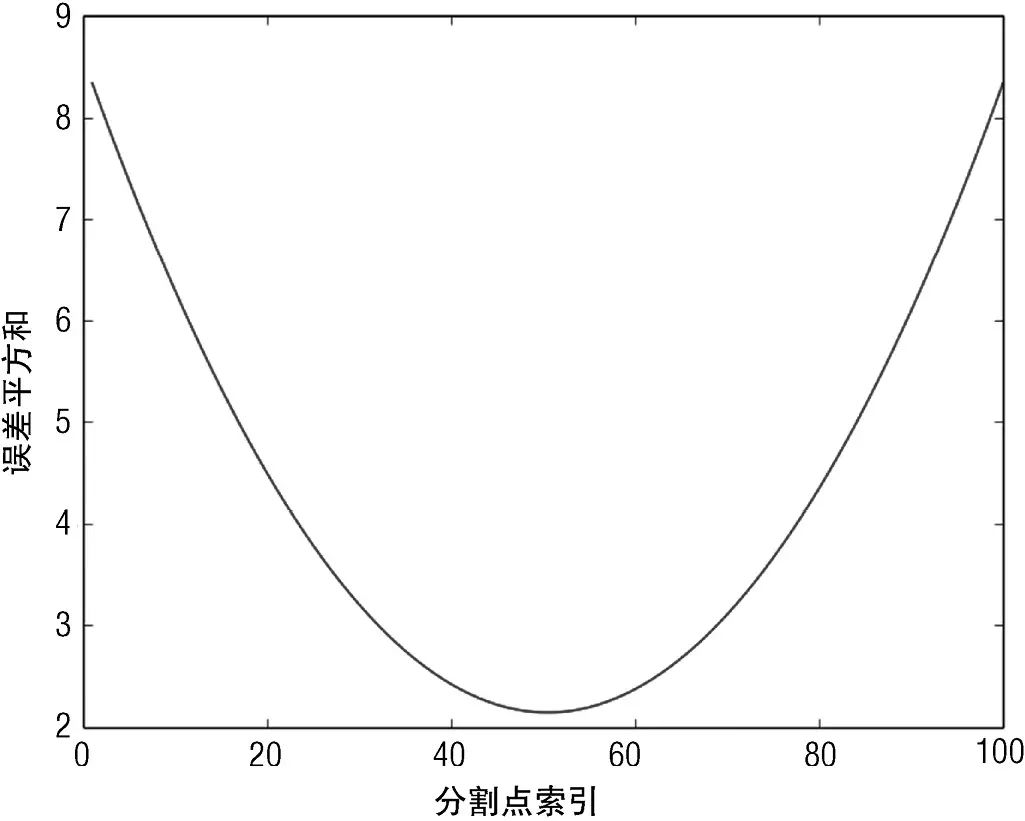
图6-5 每个可能的分割点对应的误差平方和
多变量决策树的训练-选择哪个属性进行分割
如果问题含有多个属性该怎么办?算法会对所有的属性检查所有可能的分割点,对每个属性找到误差平方和最小的分割点,然后找到哪个属性对应的误差平方和最小。
在训练决策树的过程中,每个计算周期都要对分割点进行计算。同样地,训练基于决策树的集成算法时,每个周期也要对分割点进行计算。如果属性没有重复值,每个数据点对应的属性值都要作为分割点进行测试(则分割点的测试次数等于数据点数目减1)。
随着数据规模的增大,分割点的计算量也成比例增加。测试的分割点彼此可能非常近。因此设计针对大规模数据的算法时,分割点的检测通常要比原始数据的粒度粗糙得多。论文“PLANET:Massively
Parallel Learning of Tree Ensembles with MapReduce”
提出一种方法,是谷歌工程师针对大规模数据集构建决策树时采用的方法,他们使用决策树来实现梯度提升(gradient boosting)
算法(本章将会学到该集成方法)。
通过递归分割获得更深的决策树
代码清单6-2展示了当决策树深度从1增加到2时,预测曲线会发生什么变化。预测曲线如图6-6所示。决策树的框图如图6-7所示。深度为1的决策树只有一步,这个预测曲线有3步。第2决策层分割点的确定与第1个分割点的方法完全一样。决策树的每个节点处理基于上个分割点生成的数据子集。每个节点中分割点的选择是使下面2个节点的误差平方和最小。图6-6的曲线非常接近一个实际的阶梯函数曲线。决策树深度的增加意味着更细小的步长、更高的保真度(准确性)。但是如果这个过程无限地继续下去会怎样?
图片 18{67%}
图6-6 深度为2的决策树的预测曲线
图片 19{514}
图6-7 深度为2的决策树的框图
随着分割的继续,决策树深度增加,最深节点包含的数据(实例数)会减少。这将导致在达到特定的深度之前,这种分割就终止了。如果决策树的节点只有一个数据实例,就不需要分割了。决策树训练算法通常有一个参数来控制节点包含的数据实例最小到什么规模就不再分割。节点包含的数据实例太少会导致预测结果发生剧烈震荡。
1.4 二元决策树的过拟合
上节介绍了如何训练任意深度的二元决策树。那么有没有可能过拟合一个二元决策树?本节介绍如何度量和控制二元决策树的过拟合。二元决策树的过拟合原因与第4章和第5章的有所不同。但是过拟合的表现以及如何度量过拟合过程还是比较相似的。二元决策树的参数(树的深度、最小叶节点规模等等)可以用来控制模型的复杂度,类似过程已经在第4章和第5章看到。
二元决策树过拟合的度量
图6-8展示了决策树的深度增加到6会发生什么。在图6-8中,很难看出真实值与预测值之间的差别。预测值几乎完全跟随每一个观察值的变化。这就开始暗示此模型已经过拟合了。数据产生方式表明最佳预测就是让预测值等于对应的属性值。添加到属性上的噪音是不可预测的,然而过拟合的预测结果是实际值加上噪声产生的偏差。合成数据的好处就是可以事先知道正确答案。
另外一个检查过拟合的方法是比较决策树中终止节点的数目与数据的规模。生成图6-8所示的预测曲线的决策树的深度是6。这意味着它有64个终止节点(2^6)。数据集中共有100个数据点。这意味着大量的数据单独占据一个终止节点,因此它们的预测值与观察值完全匹配。这就不奇怪预测曲线完全跟随着噪声的“扭动”。
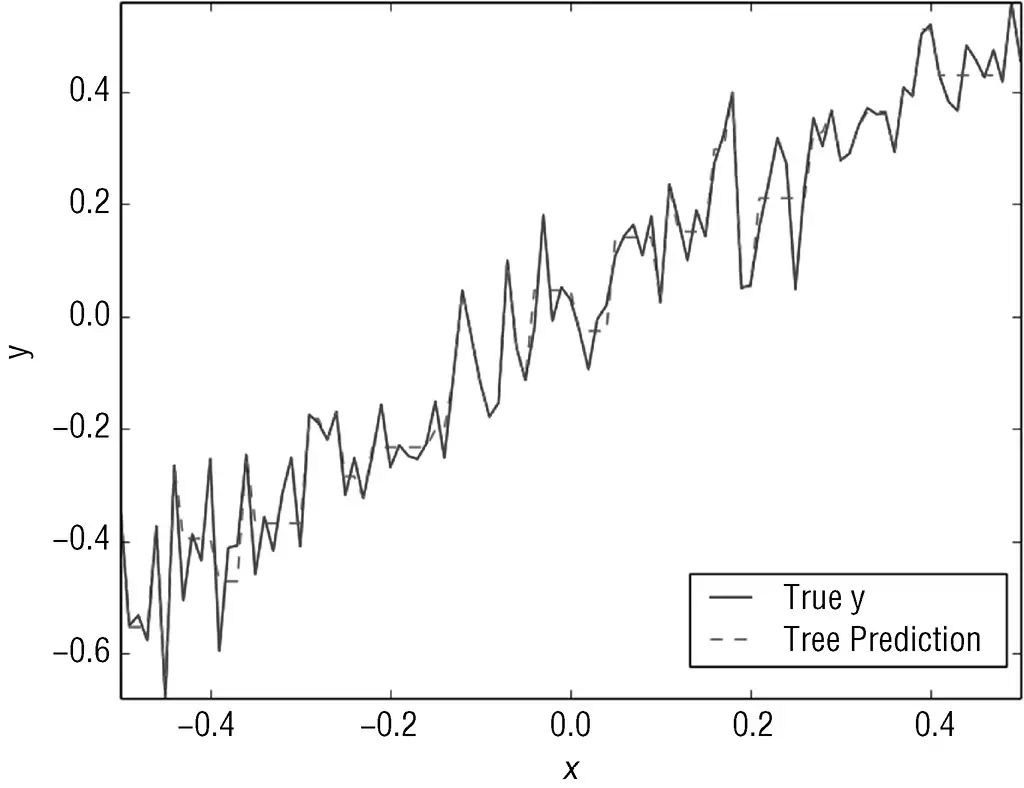
图6-8 深度为6的决策树的预测曲线
权衡二元决策树复杂度以获得最佳性能
在实际问题中,使用交叉验证(cross-validation)来控制过拟合。代码清单6-3展示了针对此问题使用不同深度的决策树运行10折交叉验证。代码显示了2层循环,外层循环定义了内层交叉验证的决策树深度,内层循环将数据分割为训练数据和测试数据后计算10轮测试误差。不同深度的决策树对应的均方误差(MSE,
mean squared error)如图6-9所示。
代码清单6-3 不同深度决策树的交叉验证-simpleTreeCV.py
import numpy
import matplotlib.pyplot as plot
from sklearn import tree
from sklearn.tree import DecisionTreeRegressor
from sklearn.externals.six import StringIO
#Build a simple data set with y = x + random
nPoints = 100
#x values for plotting
xPlot = [(float(i)/float(nPoints) - 0.5) for i in range(nPoints + 1)]
#x needs to be list of lists.
x = [[s] for s in xPlot]
#y (labels) has random noise added to x-value
#set seed
numpy.random.seed(1)
y = [s + numpy.random.normal(scale=0.1) for s in xPlot]
nrow = len(x)
#fit trees with several different values for depth and use
#x-validation to see which works best.
depthList = [1, 2, 3, 4, 5, 6, 7]
xvalMSE = []
nxval = 10
for iDepth in depthList:
#build cross-validation loop to fit tree and evaluate on
#out of sample data
for ixval in range(nxval):
#Define test and training index sets
idxTest = [a for a in range(nrow) if a%nxval == ixval%nxval]
idxTrain = [a for a in range(nrow) if a%nxval != ixval%nxval]
#Define test and training attribute and label sets
xTrain = [x[r] for r in idxTrain]
xTest = [x[r] for r in idxTest]
yTrain = [y[r] for r in idxTrain]
yTest = [y[r] for r in idxTest]
#train tree of appropriate depth and accumulate
#out of sample (oos) errors
treeModel = DecisionTreeRegressor(max_depth=iDepth)
treeModel.fit(xTrain, yTrain)
treePrediction = treeModel.predict(xTest)
error = [yTest[r] - treePrediction[r] \
for r in range(len(yTest))]
#accumulate squared errors
if ixval == 0:
oosErrors = sum([e * e for e in error])
else:
#accumulate predictions
oosErrors += sum([e * e for e in error])
#average the squared errors and accumulate by tree depth
mse = oosErrors/nrow
xvalMSE.append(mse)
plot.plot(depthList, xvalMSE)
plot.axis('tight')
plot.xlabel('Tree Depth')
plot.ylabel('Mean Squared Error')
plot.show()
图片 21{69%}
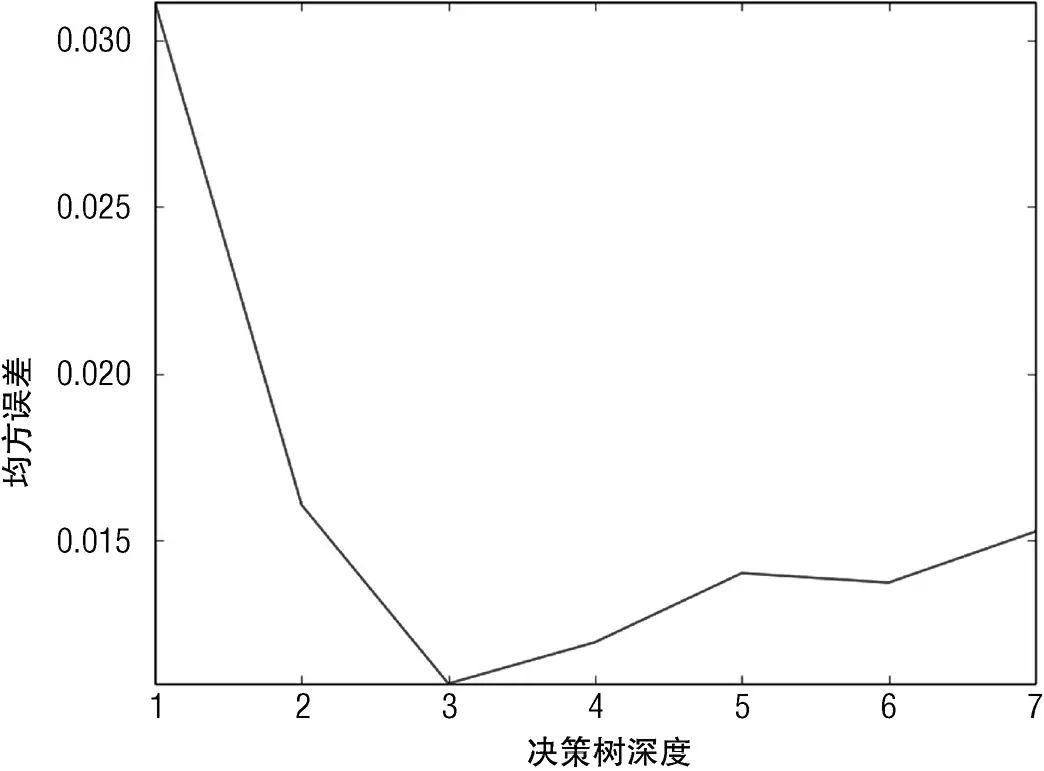
图6-9 简单问题的测试数据均方误差与决策树深度的关系
决策树的深度控制二元决策树模型的复杂度。它的效果类似于第4章和第5章中惩罚回归模型的惩罚系数项。决策树深度的增加意味着在付出额外的复杂度的基础上,可以从数据中提取出更复杂的行为。图6-9说明决策树深度为3时,可以获得基于代码清单6-2生成的数据的最佳均方误差(MSE)。此决策树深度体现了重现属性与标签的内在关系和过拟合风险之间的最佳权衡。
回顾第3章,最佳模型的复杂度是数据集规模的函数。合成数据问题提供了观察这个关系是如何起作用的机会。当数据点增加到1 000时,最佳模型复杂度和性能发生的变化如图6-10所示。
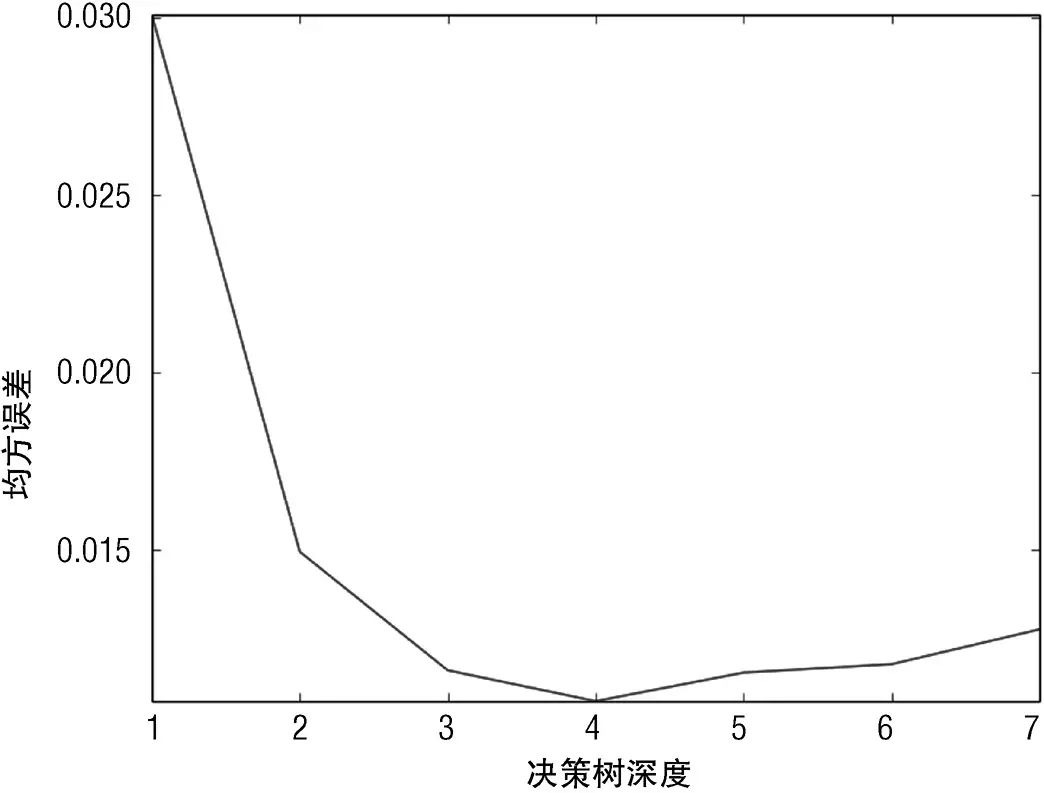
图6-10 1 000个数据点时,测试数据均方误差与决策树深度关系
可以修改代码清单6-3中的变量nPoints为1000,然后运行代码。增加数据时,会发生两件事情:第一件事是最佳决策树深度会从3增加到4。增加的数据支持更复杂的模型。另外一件事是均方误差有轻微的下降。增加的决策树深度允许在逼近真实模型时提供更精细的“台阶”,面向真实的大规模数据场景也可以提供更好的保真度。
1.5 针对分类问题和类别特征所做的修改
为了提供关于决策树是如何训练的完整场景,还有一些细节问题需要讨论。一个问题就是:如何应用决策树解决分类问题?上述判断分割点的均方误差只对回归问题有意义。正如你在本书其他部分看到的,分类问题与回归问题有不同的评价标准。分类问题在判断分割点时可以使用多个评价标准来代替均方误差。一个是很熟悉的misclassification
error(误分类错误)。另外两个比较通用的是基尼不纯性度量(Gini impurity measure)和信息增益(information
gain)。详细内容可以参考http://en.wikipedia.org/wiki/Decision_tree_learning#Gini_impurity。这两个度量指标与误分类错误有一些不同特性,但在概念上没有差别。
最后一个部分是当属性是类别属性而非数值属性时,如何训练决策树。决策树中的非终止节点提出一个yes/no的问题。对应数值属性,问题是判断属性是否小于某一值的这种形式。把一个类别属性(变量)分割成两个子集需要尝试所有分成2个子集的可能性。假设一个类别属性包含A、B、C三类,可能的分割方式是:A在一个子集,B、C在另外一个子集,或者B在一个子集,A、C在另外一个子集,诸如此类。在某些环境下,可以直接使用相关数学结果简化这个过程。
本节了提供二元决策树的背景知识,二元决策树本身就是一个很好的预测工具,值得深入研究。但是这里提出的目的是将其作为集成方法的背景。集成方法包含了大量的二元决策树。在当成千上万个决策树组合到一起时,使用单个决策树时出现的问题(如需要调整多个参数、结果的不稳定性、决策树深度加深导致的过拟合等)就会减弱。这也是提出集成方法的原因,集成方法更加鲁棒、易于训练、更加准确。
数据挖掘入门与实战
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注
公众号: weic2c
据分析入门与实战

长按图片,识别二维码,点关注









