

作者 |
hzyido
来源 | 简书

糖豆贴心提醒,本文阅读时间6分钟,文末有秘密!
这篇文章介绍了Python机器学习环境的搭建,我用的机器学习开源工具是scikit-learn。
下面具体介绍环境搭建以及遇到的一些问题。所有可能需要的软件都可在官网下载,或者在我的百度网盘下载:
http://pan.baidu.com/share/linkshareid=1273581610&uk=3510054274
。这里介绍的在windows下搭建的,同时我也在ubuntu 13.04下搭建成功,之前也一直在ubuntu下办公,但是后来发现风扇一直开启,还经常卡死,看电子书和视频也不太方便。于是后来又回到了windows下,如果只在Linux下学习那么应该选择ubuntu 13.04。
scikit-learn是一个开源机器学习软件包。其用户手册在这里下载:
http://pan.baidu.com/share/link?shareid=1332146121&uk=3510054274
。scikit-learn是用python开发的。于是整个环境的第一步要安装python,这里用的是python 2.7,也建议使用这个版本,我已经包含在我的网盘里了,大家看名字可以明白是哪一个。
安装过程比较简单,鼠标直接一路(可改变以下路径,默认是装在C盘的)点下来即可。之后我们需要分别安装的是Numpy,Scipy,Matplotlib,前两者是科学计算的,比如说矩阵处理,后者是用来画图的,作数据可视化的。关于它们的教程可在这里下载:
http://pan.baidu.com/share/link?shareid=1374756503&uk=3510054274
。
它们的安装都比较简单,安装的时候会自动检测之前安装的python,所以基本也就是一路点击下来。最后安装scikit-learn 0.15,安装之前首先需要安装numpy-MKL.整个过程是比较简单的。
下面介绍使用过程,构建第一个机器学习的例子,其中需要的数据我放在这里了:
http://pan.baidu.com/share/link?shareid=1399332518&uk=3510054274
。我们的数据的格式是这样的:
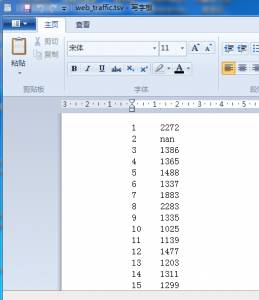
总共有743条,用word的写字板打开我网盘里的文件:web_traffic.tsv。这里数据的第一列表示时间(小时),第二列表示在这个小时内网站点击量(比如说第一行1 2272,表示第1个小时的点击量为2272次)。
而我们所要做的工作便是通过这些数据去预测未来的点击量,从而未我们的网站建设提供一些指导,比如说我们需要多少服务器来支撑这样的点击量,如果我们能够提前知道就可以节省很多钱,总比事先买很多服务器好哈。
首先,我们要做的是把这些数据读到我们的程序里去。方法是使用SciPy的genfromtxt(),首先打开开始菜单中的所有应用程序找到Python 2.7,选择第一个IDLE(Python GUI):
然后输入:
import scipy as sp
data=sp.genfromtxt(“web_traffic.tsv”,delimiter=”\t”)

前者表示路径名,要注意在自己电脑上设置成相应的路径名,然后第二个参数是分隔符,由于原文件中使用的制表符隔开数据的,所以这里是\t。为了查看以下是否已经成功将数据读取到相应变量中,我们可以用如下的方法检验:
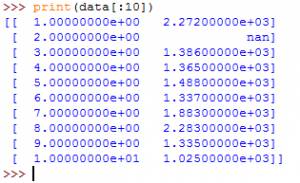
其中观察到第二行数据的第二列nan,它表示无效数据。然后,我们再敲入:
>>>print(data.shape),显式如下:

它的意思表示一共有743行数据,每行数据有2个属性。到这里,我们已经成功把数据读到程序里去了。接下来需要对数据进行一些预处理,比如说上面显示的无效数据。
我们需要把数据分成两个向量也许更好。它们分别是向量x和向量y。使得它们可以对应监督学习中的输入和输出。第一个向量x表示第一列时间,向量y表示第二列点击量。操作如下:

刚才提到了无效数据,首先看看有多少个无效数据,也就是有多少行含有“nan”。敲入:

看来不多,只有8行。我们能够手动删除它们?那如果很多无效数据了呢,所以我们还是借助SciPy的强大功能吧。敲入:

学过程序的人应该都能看得明白,~表示取反,这里就表示取有效的数据,当然具体细节我们暂时不需要明白,只要知道它的功能即可。好的,现在来检测一下是不是已经剔除了无效数据呢?

发现原来的2被我们剔除了,再来看下y吧:

原来那个nan没了。好的,数据处理好了,接下来想可视化以下,我们把它展示在一张图中,这就要借助工具Matplotlib.把下图中的>>>后面的命令敲入:
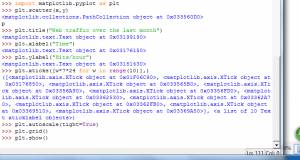
可以看到图:





