正文

昨日“人机对决”的硝烟还未散尽,今天上午 9 点 30 分DeepMind的掌门人哈萨比斯就在乌镇发表了
《 AlphaGo 研发介绍, AlphaGo 意味着什么?》
的主题演讲
,将“怪兽”AlphaGo背后的重大升级细节和盘托出。不得不说,在经历了几番和人类选手的比拼之后,人工智能的力量已经进化的了难以想象的层次。
除此以外,在这次的论坛上,
AlphaGo的主要开发者大卫·席尔瓦(David Silver)和谷歌大脑(Google Brain)团队负责人杰夫·迪恩(Jeff Dean)
同时进一步揭秘了脱胎换骨之后的全新AlphaGo。
据悉,相较于之前12层卷积神经网络的AlphaGo,此次出战的AlphaGo已经达到的
40层神经网络
,性能较上次和人类大战60回合的Master也有了增强,更是比李世石的那一版强了三子的优势。正是在这种不断自我训练的情况下,AlphaGo已经生成了一代强过一代的神经网络。
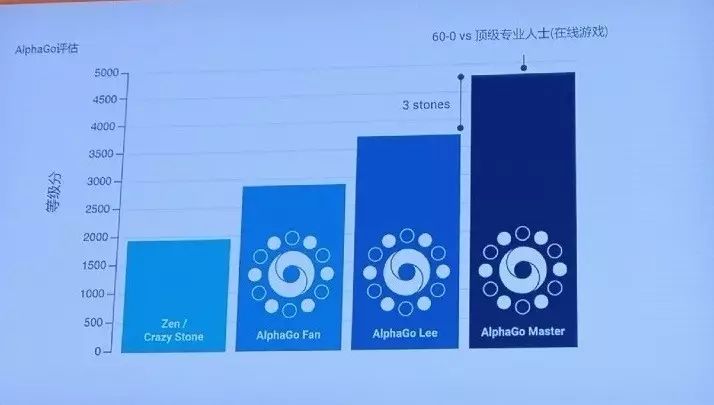
图丨DeepMind团队预测,Master版本比李世石版本提升了三子
如今的AlphaGo无论从哪个角度看都更像是一台独立的高性能秘密武器。凭借着十个谷歌自研的TPU,它摆脱了对外界的依赖;使用自己所积累的数据;更强大的策略网络和价值网络提高了的反应速度和判断的准确性……强化学习的优势在AlphaGo身上表现得淋漓尽致,并且还将结出更加丰硕的成果。
以下是DT君在现场的编辑整理后哈萨比斯今日主题演讲的内容精选:
我先简单介绍一下 DeepMind。2010 年,DeepMind 创立于英国伦敦,2014年我们加入 Google。我们想要做的就是攻克人工智能。
对于 DeepMind 而言,我们希望网络全世界的机器学习科学家,能够结合计算能力,尽快解决人工智能的问题。另外,DeepMind 为了更好的进行研发,创新了我们的组织方式。

可以说,Deep Mind的任务可以分两步走:
第一步是要从根本上了解智能是什么,然后用人工方法去创造它。
接下来就是要通过这种智能去尝试解决其他所有问题。我们认为,AI会是人类历史上最重要的技术发明之一。
具体来说我们会怎么做?在DeepMind,我们常会提到要建立通用型学习系统。最核心的概念就是“学习”,我们开发的所有系统都有学习相关的内核,这种学习系统从实践经验和数据中学习,而不需要预先输入程序化的解决方案。
第二步是要解决AI的通用性问题。
我们认为,单一系统或者算法组合并不能直接解决各种问题,更不用说以前没遇到过的问题。这种系统最好的例子就是人脑,我们从某一任务中学习,并相关经验应用于其他未遇到过的问题,即所谓的举一反三。而机器在这方面是有很大问题的,DeepMind就是想赋予机器这种能力。
打造这种通用型学习系统涉及到几项关键技术。首先是深度学习,即层叠的神经网络,这个大家都很熟悉了;然后是强化学习,即让机器自己学习,以达到最大化的收益。
我们将这种具有通用目标的学习系统称为通用型人工智能,这与目前所谓的人工智能是不一样的,因为目前的人工智能主要还是预先写入的程序而已。
实际上,打造通用型学习系统,最重要的是要学习。所有算法都会自动学习,更多的数据和更多的体验不依赖于预设。
通用型的强人工智能与弱人工智能不一样。最好的例子就是,在90年代末IBM开发的“深蓝”系统,击败了当时顶尖的国际象棋高手卡斯帕罗夫——这在当时是很大的成就,但“深蓝”终究是一套预先写入程序的系统,相当于一位顶级程序员在和卡斯帕罗夫对弈,这位程序员尝试揣摩卡斯帕罗夫脑子里在想什么,并把相应的对策全部编写到程序里。这个技术了不起,但它不能解答人工智能之路在哪,只是在执行预先写入的命令,而不是自己来学习、决策。

然而,人类的大脑学到新的知识后却可以举一反三,我们可以用习得的现有经验解决新的问题,这是机器所不擅长的。
所以说,与之前的相比,我们想要的是能够自我学习的系统,而这种系统需要在强化学习的框架下来开发。有必要先稍微解释一下到底什么是所谓的强化学习。
在人工智能系统中,有一个我们称之为Agent的主体,Agent发现它身处某种环境下,并需要完成某些任务。如果周围的环境是真是世界,Agent可能会是一个机器人;但如果周围环境是诸如游戏这类虚拟环境,Agent就可能是一个虚拟形象(Avatar)。
要完成某个任务,Agent会通过两种方式与环境互动。首先是传感器,DeepMind更多会使用视觉传感器让机器与环境互动,当然,如果你愿意,也可以使用语音、触觉等方式。所以这类Agent通常通过自己的观察来对环境建模。但是这里有个问题,真是环境通常是充满噪声、干扰、不完整的,所以需要Agent尽最大努力去预测周围到底是什么样的。
一旦这个环境模型建立,就要开始第二步了:如何在这个环境中做出最好的行为决策。当然,行为与环境间的互动可能是成功的,也可能是失败的,这写结果都会被实时纳入Agent的观察过程,这也就是强化学习的过程。
这两年来,AlphaGo团队专注于围棋项目。与象棋相比,围棋更加复杂。对于象棋来说,写一个评价函数是非常简单的。另外,围棋更需要直觉,伟大的旗手往往难以解释他们为什么下了这一步棋,象棋选手则可以给一个明确的答案,回答这么走的原因,有时候也许不尽如人意,但是起码选手心中是有清晰的计划的。
为什么围棋的评估方程式这么难?相比象棋,围棋是因为没有物质性的概念,每一个棋子是等值的,而象棋有由估值的高低的。第二,围棋是建设性的,围棋是空的,你需要填充棋盘。特殊位点的评估,期盼在你心中,不断摸索,围棋手是建设性的,一切情况不得而知,需要棋手预测未来,进行布局,而象棋往往讲究当下的时局。
另一个原因,一个棋子怎么走,一步输步步输,一发全身。围棋更具有直觉性,历史中我们觉得这是神的旨意,由灵感指导行为。
那么我们怎么写出这个方程式呢?策略网络……缩小范围……价值网络。我们曾经在《Nature》上发布了相关的论文,论文帮助一些国家和公司打造了他们自己版本的AlphaGo。
接下来,我们用比赛来测试更新的系统,比如上一次的李世石,昨天的柯洁,这两次比赛都引起了很大的关注。在和李世石的比赛中,AlphaGo赢了。但其实,我们十年磨一剑。胜利是很难的,也是很了不起,在AI领域更是这样,十年磨一剑是常事。
我们赢了,最重要的是我们激发了更多的灵感,AlphaGo打出了好局,和李的比赛中,第二局第37不起令人惊叹。这是专业人员都难以想象的,已经触及到下棋的直觉方面。
AlphaGo把围棋看做客观的艺术,每下一步旗子都会产生客观影响,而且它还能下得非常有创意。李世石在比赛中也受到了启发,他在第四局的第78着也很美妙,因此他赢了一局。
毫无疑问,AlphaGo对战李世石的影响很大,全世界28亿人在关注,35000多篇关于此的报道。西方世界开始更多地感受到围棋这种东方游戏的魅力,当时围棋的销量还涨了10倍。我们很乐意看到西方世界也学习这种游戏。而李世石也有新的发现,他在赛后表示,和狗比赛是其人生最美的体验,狗也为创造了围棋的新范式,李表示他对围棋的兴趣更大了,我开心他这么说。
回到直觉和创意上。什么是直觉?人们通过各种体验获得经验,这是无法继承,人们接受测试来检验他们直觉。AlphaGo已经能模仿直觉。而创造力上,它的一个定义是,整合新的知并创造新的点子或知识,阿狗显然是有创造力,但这种创造力仍然仅局限于围棋。
在过去一年中,DeepMind不断打造AlphaGo,希望能解决科学问题并弥补它的知识空白,我们还将继续完善它。之后,Master出现了,我们在今年一月对他进行上线测试,他取得了60连胜,还诞生了很好的点子,它的棋谱被全世界的棋手们研究。例如,AlphaGo打了右下角三三目,这种举措在之前是不可想象的。
柯洁也说,人类3000年围棋历史,至今没有一人曾经接近过到围棋真理的彼岸。但是,人和AI的结合可以解决这个问题。古力也说,人类和AI共同探索围棋世界的脚步开始了。

昨晚晚宴上,我了解到了围棋大师吴清源的故事。可能AlphaGo也能带来围棋的新篇章,就像吴当年为围棋贡献的革命性力量一样。象棋的下发都是策略性的,而AlphaGo能想出非常有战略性的点子,也给棋手们带来新点子。
曾经和DeepBlue(深蓝)对战的象棋世界冠军GarryKasparov出过一本书,描述了他的一个观点:深蓝的时代已经结束了,狗的时代才刚开始。没错,AlphaGo是通用人工智能,未来我们能看到人机结合的愿景,人类是如此有创意的生物,我们可以能在AI的帮助下变得更强大。
AlphaGo是人类的新工具。就像天文学家利用哈勃望远镜观察宇宙一样,通过AlphaGo,棋手们可以去探索围棋的未知世界和奥秘。我们发明AlphaGo,也希望能够推动人类文明进步,更好地了解这个世界。
我们的愿景是最优化他,最完美他。就像围棋3000年以来都没有答案,科学、技术、工程等领域也正面临着同样的瓶颈,但是,现在有了AI,我们迎来了新的探索机会。
围棋比赛是我们测试人工智能的有效平台,但我们的最终目的是把这些算法应用到更多的领域中。人工智能(特别是强人工智能)将是人们探索世界的终极工具。
当今世界面临着很多挑战,不少领域本身有着过量的信息和复杂的系统,例如医疗、气候变化和经济,即使是领域内的专家也无法应对这些问题。
我们需要解决不同领域的问题,人工智能是解决这些问题的一个潜在方式,从发现新的材料到新药物研制治愈疾病,人工智能可以和各种领域进行排列组合。
当然,人工智能必须在人类道德基准范围内被开发和利用。
我的理想就是让AI科学成为可能。另外,我对人类的大脑运作非常感兴趣,开发AI的同时,我也了解自己的大脑运作,例如大脑如何产生创意等,这个过程中我也更深入地了解了我自己。
哈萨比斯的青年传奇人生:从研究海马体开始
“AlphaGo 之父”、DeepMind 的创始人,现年 40 岁的哈萨比斯如今应成为了人工智能领域最为炙手可热的明星,伴随着 AlphaGo 的爆红,
这位被英国《卫报》称为是“人工智能英雄”的天才显然已经成为了 AI 的代名词。
在 2014 年年初,他将自己当时还名不见经传的伦敦初创公司 DeepMind 以
4 亿英镑(约合 6.5 亿美元)
的价格卖给了 Google,成为了迄今为止 Google 在欧洲范围内最大的一笔收购。
在 2014 年的温哥华 TED 大会上,Google 的执行总裁拉里·佩奇(Larry Page)不仅对哈萨比斯赞不绝口,更将其公司的技术称为“长久以来我见过的最令人兴奋的事件之一”。

哈萨比斯也表示,DeepMind 正在开发一种面对几乎任何问题都能学习的人工智能软件,这可以帮助人们处理一些世界上最为棘手的问题。他说:“人工智能有巨大的潜力,它会让人类大吃一惊。”
事实上,这位出生于 1976 年 7 月 27 日的知名 AI 科学家也是从小出名的“神童”。
4 岁的时候,仅用两个星期就国际象棋大赛中击败成年人;8 岁开始接触计算机,用他从国际象棋比赛中赢的 200 英镑买了人生中第一台计算机 ZX Spectrum;16 岁的时候被剑桥大学录取;17 岁的时候就和别人共同制作了经典模拟游戏“Theme Park”,并成立了自己的电子游戏公司。这样的人生不可谓不传奇。
但开发计算机游戏限制了哈萨比斯践行自己的真正的使命。最后,他决定,是时候该做一些以人工智能为首要任务的事情了。
在 2005 年,哈萨比斯开始在伦敦大学学院进修神经系统科学博士学位,希望通过研究真正的大脑来发现对研究人工智能有用的线索。
他选择了海马体做研究对象——海马体主要负责记忆以及空间导向,至今人类对它的认知还很少。
哈萨比斯说:“我挑选的这些大脑区域的功能目前尚没有好的运算法则与之对应。”
作为一个没有学习过高中生物课程的计算机科学家和游戏企业家,哈萨比斯的表现超过了同一院系中的医学博士和心理学家。他说:“我经常开玩笑说我对大脑的唯一认知是,它是在头盖骨里面的。”
但哈萨比斯很快就取得了成就。
2007 年,他的一项研究被《科学》杂志评为“年度突破奖(Breakthrough of the Year)”。
在这项研究中,他发现 5 位失忆症患者因为海马体受损而很难想象未来事件。从而证明了大脑中以往被认为只与过去有关的部分对于规划未来也至关重要。

发现了记忆与预先规划的交错关系后,哈萨比斯进入下一阶段的冒险――他在
2011 年终止了自己的博士研究,开始创立以“解决智能”为经营理念的DeepMind 科技公司。
哈萨比斯与人工智能专家谢恩·莱格(Shane Legg)和连续创业家穆斯塔·法苏莱曼(Mustafa Suleyman)一起创立了 DeepMind。公司雇用了机器学习方面的顶尖研究人员,并吸引到一些著名的投资者,包括彼得·泰尔(Peter Thiel)的 Founders Fund 公司、以及特斯拉和 SpaceX 的创始人埃隆·马斯克(Elon Musk)。
但 DeepMind 一直保持低调,直到 2013 年 12 月,他们在一次业界领先的机器学习研究大会上上演了自己的处子秀。
在太浩湖畔的哈拉斯赌场酒店里(Harrah’s Casino),DeepMind的研究人员演示的软件令人惊艳。该软件不仅可以玩雅达利的三款经典游戏――乒乓、打砖块和摩托大战,而且比任何人玩得都好。更关键的是,这款软件并没有获得任何有关如何玩游戏的信息,提供给软件的只有控制器、显示器、得分规则,并告诉它尽可能得高分。
程序通过不断的试错,最后成了专家级的玩家。
此前从未有人演示过具备这种能力的软件,可以从零开始学习和掌握如此复杂的任务。事实上,DeepMind利用了一种机器学习技术――深度学习,这种技术通过模拟神经元网络来处理数据。
但它将深度学习与其他技巧结合,达到了不可思议的智能水平。

加州大学的人工智能专家斯图亚特·拉塞尔(Stuart Russell)教授表示:“人们有点震惊,因为他们并未料想到我们能在现阶段技术水平下做到这种程度。我想,人们惊呆了吧。”
DeepMind 将深度学习与另一种叫做“强化学习”的技术相结合,强化学习的灵感来自于斯金纳(B.F. Skinner)等动物心理学家研究成果。










