0. 论文信息
标题:3D Shape Tokenization
作者:Jen-Hao Rick Chang, Yuyang Wang, Miguel Angel Bautista Martin, Jiatao Gu, Josh Susskind, Oncel Tuzel
机构:Apple
原文链接:https://arxiv.org/abs/2412.15618
官方主页:https://machinelearning.apple.com/research/3d-shape-tokenization
1. 导读
我们引入了形状表征,这是一种连续、紧凑且易于整合到机器学习模型中的3D表示。形状表征充当表示3D流动匹配模型中的形状信息的条件向量。流动匹配模型被训练成近似对应于集中在3D形状表面上的δ函数的概率密度函数。通过将形状标记附加到各种机器学习模型,我们可以生成新的形状,将图像转换为3D,将3D形状与文本和图像对齐,并以可变的、用户指定的分辨率直接呈现形状。此外,形状表征使得能够对诸如法线、密度和变形场的几何属性进行系统分析。在所有的任务和实验中,与现有的基线相比,使用形状表征表现出很强的性能。
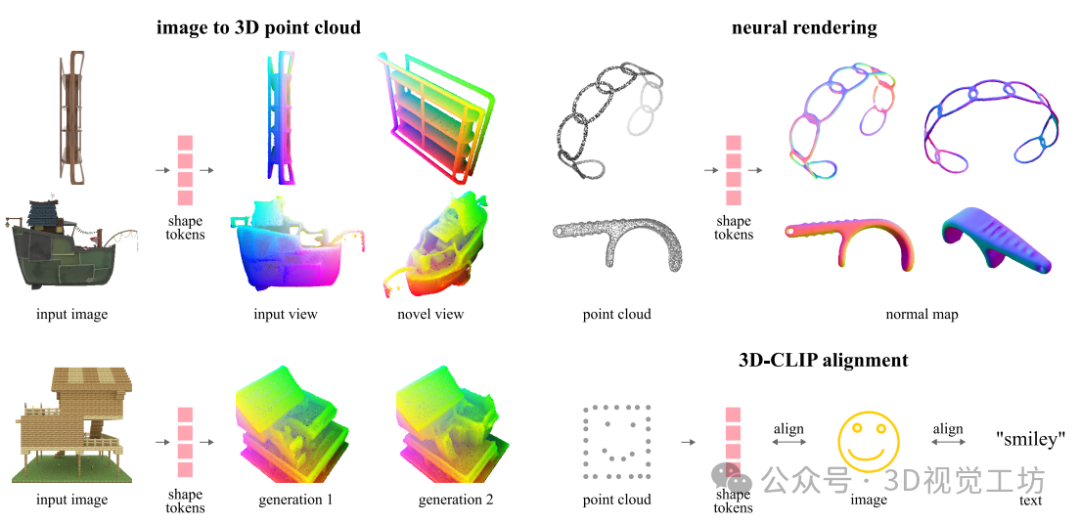
2. 效果展示
我们的shape Tokens表示可以方便地用作各种应用中的机器学习模型的输入/输出,包括单图像到3D(左图)、正常映射的神经渲染(右上角)和3D-CLIP对齐(右下角)。与基线相比,所得到的模型在单个任务上取得了强大的性能。
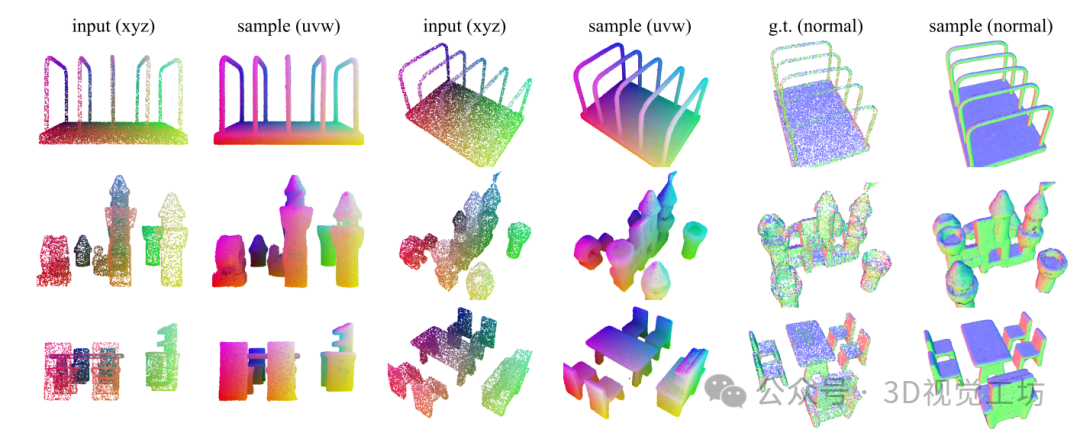
GSO数据集中的不可见点云的重建、致密化和法线估计。对于每一行,我们得到一个包含16,384个点(仅xyz)的点云,我们计算ST并独立地采样262,144个点的p(xs)。不同的列表示从不同角度输入和采样的点云。括号中的标签指示我们根据xyz坐标对输入点进行着色,根据初始噪声的uvw坐标和对估计法线的估计对采样点进行着色(最后两列)。注意,我们不向形状标记器提供普通字符作为输入。
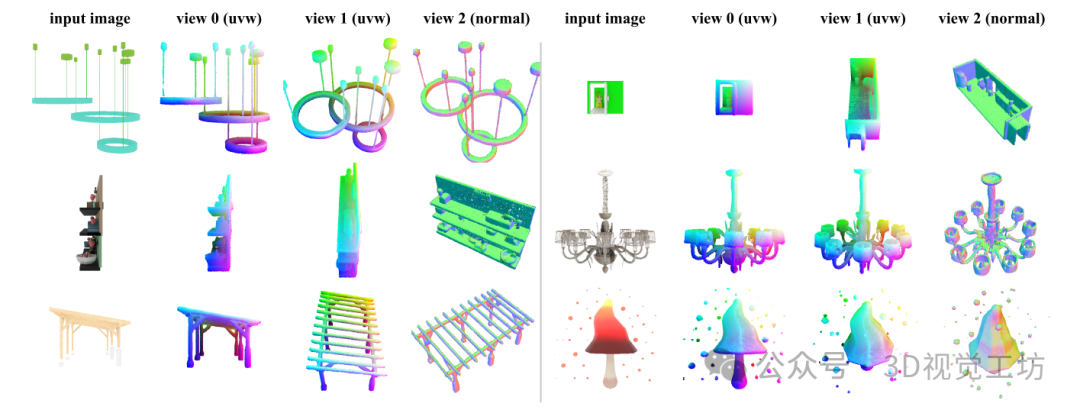
在Objaverse上对未见的网格进行单图像到3D点云结果。我们使用RGB颜色对点进行着色,表示点在初始噪声空间中的原始位置。
3. 引言
在学习系统中,应如何表示3D形状?
有许多可用选项:体素、网格、点云、(无)符号距离场、辐射/占据场3D高斯溅射等。在典型设置中,表示的选择取决于感兴趣的下游任务。例如,在图形或渲染场景中,可能会选择网格或3D高斯表示。在科学或物理模拟设置中,像场这样的连续表示可能能够编码细粒度信息。然而,在训练机器学习模型时,对于何种表示构成3D形状的良好表示,似乎没有明确的共识。由于计算和内存限制,大多数机器学习模型需要连续且紧凑的表示。由于点状表示的连续性和与近期架构(如Transformer)的兼容性,点状表示经常被选中。然而,要高精度地表示3D形状,通常需要成千上万的点,这使得点云难以在大规模系统中使用。
推荐课程:
聊一聊经典三维点云方法,包括:点云拼接、聚类、表面重建、QT+VTK等
。
我们的假设是,可以学习一种3D形状的连续且紧凑的表示,该表示能为许多不同的机器学习下游任务编码有用信息。特别是,我们将形状视为3D空间中的概率密度函数,并使用流匹配生成模型,通过对每个密度函数的样本(即形状表面上的采样点)进行训练,来学习这些密度的表示。我们将这种表示称为形状标记(Shape Tokens,ST),它具有以下几个理想特性:
ST是连续且紧凑的。它们不是用离散网格或成千上万的点来表示场景,而是用1,024个16维的连续向量来表示各种形状,使其成为下游机器学习任务的有效表示。
4. 主要贡献
我们的方法对3D形状的底层结构所做的假设最少。我们仅假设可以从3D形状的表面采样独立同分布(i.i.d.)的点(即从3D对象获取点云)。这与大多数3D表示(如符号距离函数(假设形状是水密的)和3D高斯(假设体积渲染))不同。
在训练时,我们的方法仅需要点云。这与现有的神经3D表示不同,后者在训练期间通常需要网格或符号距离函数。这一要求大大简化了我们的训练流程,使我们能够轻松扩展训练集,因为大规模数据集(如Objaverse)中的大多数网格都不是水密的,且难以处理。
值得注意的是,ST能够对形状进行系统分析,包括表面法线估计、去噪和形状间的变形。
我们通过一系列下游任务实证证明了我们的表示的有效性。首先,我们通过在ShapeNet上学习无条件流匹配模型和在Objaverse上学习图像条件流匹配模型,解决了3D生成问题。其次,我们通过学习一个多层感知器(MLP),将ST与图像和文本CLIP嵌入对齐,展示了3D形状的零样本文本分类。第三,我们通过学习一个神经网络,该网络以射线和ST为输入,输出交点及其法线,展示了图形用例(射线-表面交互估计)。在所有这些任务中,我们都取得了与为特定任务设计的基线相当的性能。
最后,我们发现阻碍进展的一个重大挑战是,缺乏在广泛数据集(如Objaverse)上训练的现有神经3D表示方法的现成代码和预训练模型。为了解决这个问题并推动未来工作的进步,我们将公开发布预训练的形状分词器、图像条件潜在流匹配模型、3D-CLIP模型、我们的数据渲染管道和完整的训练代码。
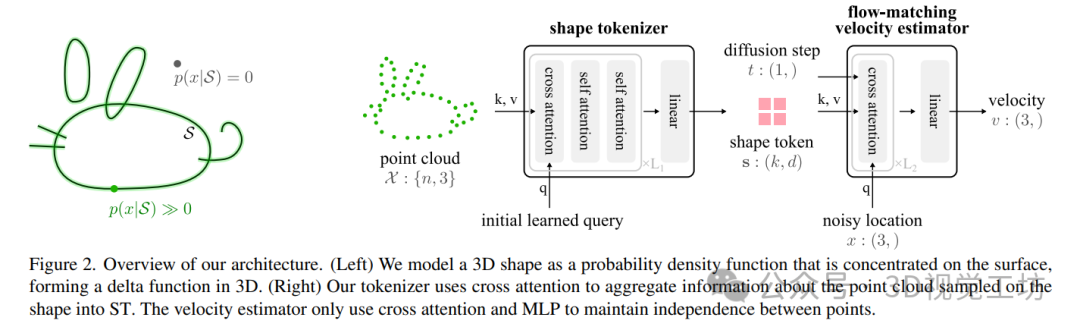
5. 方法
我们的架构概述。(左)我们将3D形状建模为集中在表面上的概率密度函数,在3D中形成δ函数。(右)我们的分词器使用交叉注意力来聚合关于在形状上采样的点云的信息,以生成ST。速度估计器仅使用交叉注意力和MLP来保持点之间的独立性。
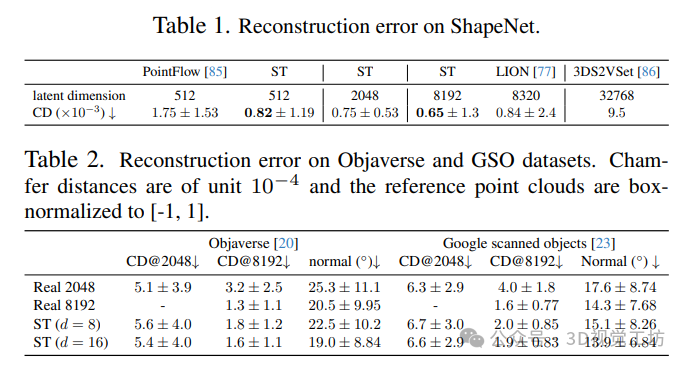
6. 实验结果
7. 总结 & 未来工作
形状分词是一种新颖的数据驱动3D形状表示方法它与大多数现有3D表示方法处于光谱的相反端这些方法明确建模几何(例如网格、SDF)或渲染公式(例如3D高斯、NeRF)。尽管受到机器学习的启发,但我们表明Shape Tokens具有与3D几何紧密相关的属性,例如表面法向量和UVW映射。形状分词和流匹配与3D几何之间的连接为3D表示提供了一种有趣且新的观点。在许多下游任务中,Shape Tokens通过特定任务表示展示了竞争性能。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。


3D视觉交流群,成立啦!
目前我们已经建立了3D视觉方向多个社群,包括
2D计算机视觉
、
最前沿
、
工业3D视觉
、
SLAM
、
自动驾驶
、
三维重建
、
无人机
等方向,细分群包括:
工业3D视觉
:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM
:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶
:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建
:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机
:四旋翼建模、无人机飞控等
2D计算机视觉
:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿
:具身智能、大模型、Mamba、扩散模型、图像/视频生成等
除了这些,还有
求职
、
硬件选型
、
视觉产品落地、产品、行业新闻
等交流群
添加小助理: cv3d001,备注:
研究方向+学校/公司+昵称
(如
3D点云+清华+小草莓
), 拉你入群。
 ▲长按扫码添加助理:cv3d001
▲长按扫码添加助理:cv3d001
3D视觉工坊知识星球
「3D视觉从入门到精通」知识星球
(
点开有惊喜
)
,已沉淀6年,星球内资料包括:
秘制视频课程近20门
(包括
结构光三维重建、相机标定、SLAM、深度估计、3D目标检测、3DGS顶会带读课程、三维点云
等)、
项目对接
、
3D视觉学习路线总结
、
最新顶会论文&代码
、
3D视觉行业最新模组
、
3D视觉优质源码汇总
、
书籍推荐
、
编程基础&学习工具
、
实战项目&作业
、
求职招聘&面经&面试题
等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

▲长按扫码加入星球
3D视觉工坊官网:
www.3dcver.com
大模型、扩散模型、具身智能、3DGS、NeRF
、
结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测
、
BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制
、
无人机仿真
、
C++、三维视觉python、dToF、相机标定、ROS2
、
机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap
、线面结构光、硬件结构光扫描仪等。
 ▲
长按扫码学习3D视觉精品课程
▲
长按扫码学习3D视觉精品课程
3D视觉模组选型:www.3dcver.com

点这里
👇
关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~





