
陈运文:
达观数据创始人,
复旦大学计算机博士,科技部“万人计划”专家,国际计算机学会(ACM)、电子电器工程师学会(IEEE)、中国计算机学会(CCF)、中国人工智能学会(CAAI)高级会员;第九届上海青年科技英才。
在人工智能领域拥有丰富研究成果,
是复旦大学、上海财经大学聘任的校外研究生导师,在IEEE Transactions、SIGKDD等国际顶级学术期刊和会议上发表数十篇高水平科研成果论文,译有人工智能经典著作《智能Web 算法》(第2 版),并参与撰写《数据实践之美》等论著;曾多次摘取ACM KDD CUP、CIKM、EMI Hackathon等世界最顶尖的大数据竞赛的冠亚军荣誉。
人类经过漫长的历史发展,在世界各地形成了很多不同的语言分支,其中
汉藏语系
和
印欧语系
是使用人数最多的两支。
英语
是印欧语系的代表,而
汉语
则是汉藏语系的代表。中英文语言的差异十分鲜明,英语以表音(字音)构成,汉语以表义(字形)构成,印欧和汉藏两大语系有很大的区别。

尽管全世界语言多达
5600
种,但大部数人类使用的语言集中在图中的前
15
种(覆盖全球
90%
以上人群)。其中英语为母语和第二语的人数最多,近
14
亿人,是事实上的世界通用语。其次是汉语,约占世界人口的
23%
。英语和汉语相加的人数占世界总人数的近一半,因此处理中英文两种语言非常关键。

人工智能时代,让计算机自动化进行文字语义理解非常重要,广泛应用于社会的方方面面,而语言本身的复杂性又给计算机技术带来了很大的挑战,攻克文本语义对实现
AI
全面应用有至关重要的意义。相应的
自然语言处理(
Natural Language Processing
,
NLP
)
技术因而被称为是“人工智能皇冠上的明珠”。
中国和美国作为
AI
应用的两个世界大国,在各自语言的自动化处理方面有一些独特之处。接下来笔者对中文和英文语言特点的角度出发,结合自己的从业经验来归纳下两种语言下
NLP
的异同点。(达观数据陈运文)
分词是中英文
NLP
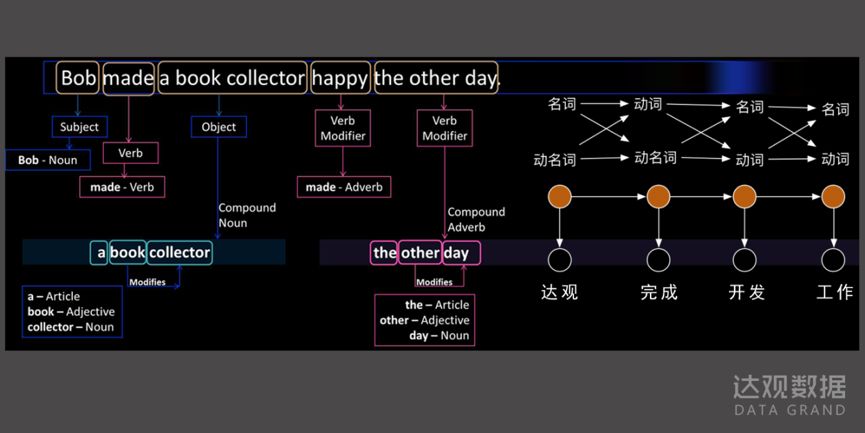
差异最广为人知的一点。我们都知道英文的单词之间天然存在空格来分隔,因此在进行英文文本处理时,可以非常容易的通过空格来切分单词。例如英文句子:
DataGrand is a Chinese company
可轻松切分为
DataGrand / is / a / Chinese / company
(文本用
/
表示词汇分隔符)。
中文在每句话中间是不存在分隔符的,而是由一串连续的汉字顺序连接构成了句子。现代汉语里表达意思的基本语素是词而不是字。例如“自然”,拆为“自”和“然”都不能单独表意,两个字合并组成的词才能有准确的意义,对应英文单词是
Nature
。因此在我们使用计算机技术对中文进行自动语义分析时,通常首要操作就是中文分词(
Chinese Word Segmentation
)。中文分词是指按人理解汉语的方式,将连续的汉字串切分为能单独表义的词汇。例如中文句子:
让计算机来处理,第一步需要切分为
“达观数据
/
是
/
一家
/
中国
/
公司”
这样的词串的形式,然后再进行后续的理解和处理。
如何正确的根据语义完成中文切分是一个挑战性的任务,一旦切词发生失误,会导致后续的文本处理产生连锁问题,给正确理解语义带来障碍。为了快速准确的切分好中文,学术界迄今有超过
50
年的研究,提出了很多方法。中文切词常见方法里既有经典的机械切分法(如正向
/
逆向最大匹配,双向最大匹配等),也有效果更好一些的统计切分方法(如隐马尔可夫
HMM
,条件随机场
CRF
),以及近年来兴起的采用深度神经网络的
RNN
,
LSTM
等方法。
由于汉语语法本身极为灵活,导致歧义语义时常发生,给正确完成中文分词带来了很多障碍。如例句
“严守一把手机关了
”所示,按照语义理解,正确切分方式为“
严守一
/
把
/
手机
/
关了
”,而算法有误时容易切分为“
严守
/
一把
/
手机
/
关了
”。
更困难的是,有些时候两种切词方法意思都对,例如“
乒乓球拍卖了
”,切分为“
乒乓
/
球拍
/
卖了
”和“
乒乓球
/
拍卖
/
了
”本身都可行,必须要依赖更多上下文来选择当前正确的切分方法。类似的还有“
南京市长江大桥
”、“
吉林省长春药店
”等等。如果把“市长”“省长”等切出来,整句话的理解就偏差很多了。常见歧义类型包括交叉歧义(
Cross Ambiguity
)和组合歧义(
Combination Ambiguity
)等,在语义消岐方面近年不断有国内外学者提出新的解决思路,来解决汉藏语系的这个特定问题。
此处顺便一提,和中文类似,日文句子内部同样缺乏天然的分隔符,因此日文也同样存在分词需求。日文受汉语语法的影响很深,但同时又受表音语法的影响,明治时代还曾兴起过废汉字兴拼音的运动,行文上汉字和假名混杂,好比中英文混血儿。业内比较知名的日文分词器有
MeCab
,其算法内核是条件随机场
CRF
。事实上,如果将
MeCab
的内部训练语料由日文更换为中文后,也同样可以用于切分中文。
随着深度学习技术近年来在
NLP
领域成功的应用,一些
seq2seq
学习过程可以不再使用分词,而是直接将字作为输入序列,让神经网络自动学习其中的特征,这在一些端到端的应用中(如自动摘要、机器翻译、文本分类等)确实省略了中文分词这一步骤,但是一方面还有很多的
NLP
应用离不开分词的结果,如关键词提取、命名实体识别、搜索引擎等;另一方面切分所得的词汇也可以和单字一起作为特征输入,用以增强效果。因此分词仍然是工程界进行中文处理时的一项重要技术。
英文单词的提取虽然比中文简单的多,通过空格就能完整的获取单词,但英文特有的现象是单词存在丰富的变形变换。为了应对这些复杂的变换,英文
NLP
相比中文存在一些独特的处理步骤,我们称为词形还原(
Lemmatization
)和词干提取(
Stemming
)。
词形还原是因为英文单词有丰富的单复数、主被动、时态变换(共
16
种)等情况,在语义理解时需要将单词“恢复”到原始的形态从而让计算机更方便的进行后续处理。例如“
does
,
done
,
doing
,
do
,
did
”这些单词,需要通过词性还原统一恢复为“
do
”这个词,方便后续计算机进行语义分析。类似的:“
potatoes
,
cities
,
children
,
teeth
”这些名词,需要通过
Lemmatization
转为“
potato
,
city
,
child
,
tooth
”这些基本形态;同样“
were
,
beginning
,
driven
”等要转为“
are
,
begin
,
drive
”。请注意词形还原通常还需要配合词性标注(
pos-tag
)一起来进行,以确保还原准确度,避免歧义发生。因为英文中存在一些多义词的情况,例如
calves
就是个多义词,即可以作为
calf
(名词,牛犊)的复数形式,也可以是
calve
(动词,生育小牛)的第三人称单数。所以词形还原也有两种选择,需要按实际所表示的词性来挑选合适的还原方法。
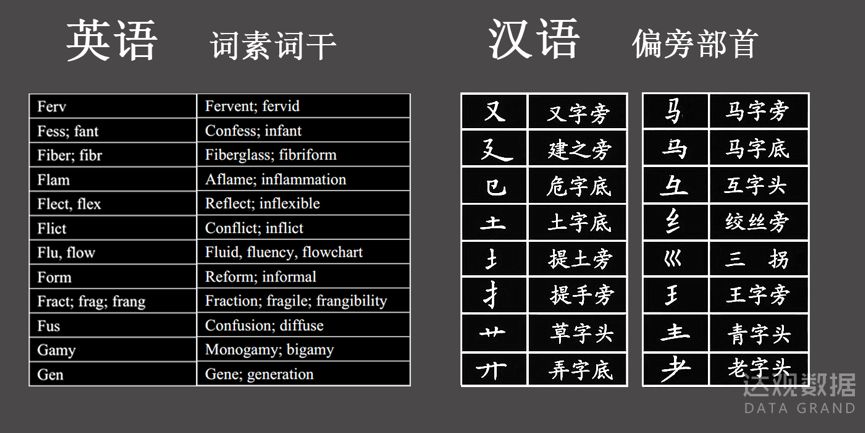
词干提取(
Stemming
)是英文中另一项独有的处理技术。英文单词虽然是句子中的基础表义单元,但并非是不可再分的。英文单词内部都是由若干个词素构成的。
词素
又分为词根(
roots
)和词缀(前缀
prefix
或后缀
suffix
),而词根的原形称为词干(
stems
)。例如单词
disability
,
dis-
就是表示否定意思的常用前缀,
-lity
是名词常用后缀,
able
是表示“能力”的词干,这些词素合并在一起就构成了单词的含义。
英文的词素种类非常多(最常用的有
300
多个),很多源自拉丁语和希腊文。提取词素对理解英文单词的含义起着非常重要的作用,例如
semiannually
这个单词,可能有的朋友并不认识,如果通过词素来看:前缀
semi-
表示“一半”的意思,词干
annul
表示年,
-ly
是副词后缀,
semiannually
这个单词的含义是“每半年进行一次的”。
Ambidextrous
,
heterophobia
,
interplanetary
,
extraterritorial
等这些看着很复杂的词汇,通过拆解词干的方法能很方便的把握单词含义,对人类和对计算机来说都是如此。常见
Stemming
方法包括
Porter Stemming Algorithm, Lovins Algorithm
和
Lancaster(Paice/Husk) Algorithm
。目前大部分英文
NLP
系统都包括词形还原(
Lemmatization
)和词干提取(
Stemming
)模块。(陈运文)
相比英文,中文里是没有词干的概念的,也无需进行词干提取,这是中文
NLP
中相对简便的一块。但在中文里有一个相近的概念是偏旁部首。和英文中“
单词不懂看词干
”类似,中文里“
汉字不识看偏旁
”。例如“
猴、狗、猪、猫、狼
”这些汉字,显然都是动物名词。当出现汉字“狁”时,即使不认识也能通过部首“犭”猜出这是一个动物名称,且发音类似“允”字。再比如“
木,林,森
”这些字都和树木相关,数量还递增。“
锁、锡、银、镜、铁、锹
”都和金属有关。“采”字和手抓植物有关。“囚”字和“孕”字就更直观形象了。
借鉴英文中词干提取的方法,很多人自然会立刻想到:是否我们拆分中文汉字的偏旁部首,作为特征输入,也能更好的帮助计算机理解中文语义呢?学术界确实也有人做过此类尝试,但是整体收益都不像英文词干分析那么明显,这背后的原因是什么呢?笔者认为,其原因首先是常用汉字的数量远比英文单词要少,相比英文单词数量动辄数万计,加上各种前后缀和词形变换数量更多,中文汉字最常用的才过千个。因为字少,每个汉字的意思多,这些汉字的含义通过上下文来获取的语义描述信息足够充分,拆分偏旁后额外再能添补的信息作用非常小。即便对罕见字来说偏旁确实能额外补充特征,但因为它们在日常文本中出现频次太少,对整体文本语义理解的作用很有限,只有在一些专业性文书的应用上可能起少量帮助。
其次是汉字经过数千年的演化,再加上简化字的使用,很多字形和含义已经发生了巨大变化,偏旁未必能准确表达字的意思,甚至使用偏旁可能还会引入一些噪声特征。第三是现代汉语里表义的基本单元是多个汉字构成的词,而不是单字。这和英文中表义单元是单词完全不同。因此对单个汉字的偏旁处理对整个中文
NLP
起到的作用非常轻微,并未成为中文
NLP
里常用的做法。
词性是语言学的一个概念,根据上下文将每个词根据性质划归为特定的类型,例如
n.
名词
v.
动词
adj.
形容词
adv.
副词等就是最常见的几类词性。中英文的词性尽管整体相似,例如表达一个物品(如苹果
Apple
,火车
Train
)通常是名词,而描述一个动作(如跑步
Run
,打开
Open
)一般是动词,但在很多细节上存在差异。如果计算机能够对每个词汇的词性进行正确的识别,无疑对增强语义分析的效果有帮助(注:同样在
seq2seq
里词性并不必须,但是对词性的正确理解仍然有其特定价值)。
在
NLP
里有技术分支称为词性标注(
Part-Of-Speech tagging, POS tagging
),中英文各自有其特点。
其一是英文中有一些中文所没有的词性。
这些词性大量存在,给语义理解带来了很好的指引作用。其中最典型的就是英文特有的两个词性:
一是冠词,二是助动词
。中文里没有冠词一说,在英文中冠词(
Article
,一般简称
art.
)也是词性最小的一类,只有三个:不定冠词(
Indefinite art.
)、定冠词(
Definite art.
)和零冠词(
Zero art.
)。如英文中无处不在的单词“
the
”就是定冠词,
the
后面通常会紧跟着出现句子的关键名词
+
介词短语。例如“
Show me the photo of your company
”,通过定冠词
the
的指示,很容易的定位本句话的关键实词是
photo
。类似的,前面例句“
DataGrand is a Chinese company
”里“
a
”这样的不定冠词也可以很好的指示出宾语“
company
”。这些大量出现的冠词虽然是虚词,本身并没有明确含义,但在
NLP
中用于定位句子中的关键实词,判断实词种类(是否可数,是否专有名词等),进而识别出句法结构(后面还会详细介绍)等,起到了很大的指示作用,也降低了计算机进行语义理解的难度,因而这方面英文比中文有先天优势。
助动词(
Auxiliary Verb
)也是英文特有的现象,助动词的作用是协助主要动词构成谓语词组,如
am, is, have, do, are, will, shall, would,should, be going to
等都是常见助动词,在英文句子中也大量存在,和冠词用于指示主语宾语类似,助动词对识别主要动词(
Main Verb
)和谓语会起帮助。
其次,英文在词性方面的划分和使用更严谨,词汇在变换词性的时候会在词尾形成丰富的变化
。例如
-ing
、
-able
、
-ful
、
-ment
、
-ness
等都对确认词性给出具体的提示。名词中还会进一步区分可数名词、不可数名词,在词尾用
-s
、
-es
来区分。动词也同样会存在发生时态的指示,过去式,现在时,未来时等非常明确,因此在英文语法中几乎没有词性混淆不清的情况发生。
而中文的词性则缺乏类似英文这样的明确规范。中国著名的语言学家沈家煊先生在著作《语法六讲》中就曾提出“
汉语动词和名词不分立
”的观点,将确认汉语词性的问题描述为“
词有定类
”则“
类无定职
”,而“
类有定职
”则“
词无定类
”。和英文中名词、动词、形容词三大类词汇相互独立的“分立模式”不同,中文更类似“包含模式”,即形容词作为一个次类包含在动词中,动词本身又作为次类被名词包含,而且这个词性的转换过程非常微妙,缺乏表音语言中的前后缀指示。例如“
他吃饭去了
”中“吃饭”是动词,只需要句式稍加变换为“
他吃饭不好
”,此时“吃饭”就摇身一变成名词了。“热爱编程”、“挖掘数据”中,“编程”、“挖掘”等词,既可以是名词也可以是动词。形容词也有类似的情况,如“活跃”是个常见的形容词,常用句为“他表现非常活跃”。但有时也可以变身为动词“他去活跃气氛”,还能变为名词“活跃是一种行为习惯”。可见汉语语境的变化给词性带来非常微妙的变化。(陈运文)
汉语没有英文的屈折变化的特点,不像英语能通过灵活的词尾变化来指示词性变化,汉语这种一词多性且缺乏指示的特点,给计算机词性标注带来了很大的困难,业界对词性的标准以及标准测试集也很不完善。很多具体词汇的词性甚至让人工来研读都模棱两可,让算法自动来识别就更难了。例如:
“他很开心”、“他逗她开心”、“他开心不起来”、“他开心的很”、“开心是他很重要的特点”
,这里“开心”的词性让人来判断都很难搞明白,甚至存在争议。而反观英语里一个词被标为动词还是名词几乎不存在争议。对这些模糊的情况,一些中文语料标注库里干脆用“动名词
vn
”、“形名词
an
”等来标记,搁置争议,模糊处理。
在目前中文
NLP
词性标注中,“名动形”糊在一起的特点仍然没有找到特别好的处理手段,也给后面的句法结构分析,词汇重要性判断,核心关键词提取等语义理解课题带来了干扰。
在自然语言处理应用中,很容易被忽略的是标点和字体等信息的利用。尤其学术界研究核心算法时一般都会忽略这些“次要”信息,大部分学术测试集合干脆是没有字体信息的,标点也不讲究。但是在实际工程应用中,这些信息能起不小的作用。而英汉语在其使用方面也存在一些差异。标点(如?!:——。等)和字体(字母大小写,斜体,粗体等)虽然本身没有具体语义,但在辨识内容时起重要的引导作用。不妨让我们想像一下,如果把我这篇文章里所有标点、分段、标题字体等都去掉,让人来阅读理解本文内容,难度是不是立刻会加大很多?若是换成计算机来读那就更麻烦了。
在英语中(尤其是书面语中),逗号和句号的使用有明确规范,一句话结尾要求必须用句号符“
.
”,并且下一句话的第一个单词的首字母要求大写。英文中从句非常多,从句之间要求用逗号“
,
”连接,以表示语义贯通。不仅如此,当一句话的主谓宾完整出现后,如果下一句话也同样是一个完整句子,则两句话中间或者需要用连词(如
and, or, therefore, but, so, yet, for, either
等)连接,或者必须用句号“
.
”分割,如果中间用“
,
”且没有连接词,则属于正式文书中的用法错误。如:
The algorithms and programs,which used on the website, are owned by the company called DataGrand, and are well known in China.
这里出现的标点和大小写字体是良好的句子语义指示符,既分割不同句子,也在句子内部分割不同语义,这些规范给英文
NLP
处理创造了较好的环境。
中文标点的使用则没有这么强的规范。事实上中文标点在中国古代官方文书中一直不被采用,仅扮演民间阅读中的停顿辅助符的角色。直到
1919
年中华民国教育部在借鉴了西方各国标点规范后才第一次制定了汉语的
12
中符号和使用方法,建国后在
1951
年和
1990
年两次修订后逐步成型。因为历史沿革的原因,这些对标点的使用规范更多偏向于指导意见,而不是一套强制标准。例如对逗号和句号何时使用,并不像英语中有特别严格的界定。汉语的分句较为模糊,意思表达完以后虽通常用句号,但用逗号继续承接后面的句子也并不算错,只要整篇文章不是极端的“一逗到底”,即使语文老师在批阅作文时也都不会过分对标点较真,而日常文章中标点的使用更是随心所欲了。
与此同时,英文里专有名词用大写或者斜体字体来区分,首字母大写等用法,在中文中也不存在。
NLP
处理中,中文标点和字体使用的相对随意给句法分析也带来了巨大的挑战,尤其在句子级别的计算机语义理解方面中文比英文要困难很多。
除了上述不利因素,中文也有一些独特的标点带来有利的因素。例如
书名号
《》就是中文所独有的符号,感谢这个符号!书名号能非常方便的让计算机程序来
自动识别专有名词
(如书名、电影名、电视剧、表演节目名等),这些名词往往都是未登录词,如果没有书名号的指引,让计算机程序自动识别这些中文专名的难度将加大很多,而这些专名词汇恰恰都体现了文章的关键语义。例如下面这段新闻如果让计算机来阅读:“
由于流浪地球的内容很接近好莱坞大片,因此影评人比较后认为不仅达到了
2012
的水平,而且对比星际穿越也毫不逊色。
”。要求计算机自动提取上面这句话的关键词会非常困难,因为里面有很多未登录词,对“
2012
”的理解也会有歧义(时间词?
or
电影名?)
而正因为我们中文有书名号,迎刃而解:
“
由于《流浪地球》的内容很接近好莱坞大片,因此影评人比较后认为不仅达到了《
2012
》的水平,而且对比《星际穿越》也毫不逊色。
”
。除了书名号,汉语的顿号(、)也能很好的指示并列关系的内容,“达观每天下午的水果餐很丰富,有桃子、葡萄、西瓜和梨”,这些并列的内容可以很方便的被计算机解读。
英文则没有书名号和顿号等,而是采用特殊字体(例如加粗、斜体、大写,各不相同,没有强制约定)等形式来标识出这些专有名词。因此在处理英文时,这些字体信息起很重要的作用,一旦丢失会带来麻烦。
值得一提的是,在日常聊天文字中,标点符号和字母使用的含义产生了很多新的变化。例如对话文本中“。。。。。”往往表达出“无语”的情绪。“?”和“???”前者是疑问,后者更多表达震惊。还有
:) \^o^/ ORZ
等各类的符号的变换使用,给开发对话机器人的工程师们带来了很多新的挑战。
词汇粒度问题虽然在
NLP
学界被讨论的不多,但的的确确
NLP
实战应用中的一个关键要点,尤其在搜索引擎进行结果召回和排序时,词汇粒度在其中扮演关键角色,如果对其处理不恰当,很容易导致搜索质量低下的问题。
我们先看中文,词汇粒度和分词机制有很大关系,先看个例子:
“中华人民共和国”
这样一个词,按不同粒度来切,既可大粒度切为:“中华人民,人民共和国”,也可进一步切出“中华,人民,共和国”,而“共和国”还可以进一步切为“共和,国”。一般我们把按最小粒度切分所得的词称为“基本粒度词”。在这个例子中,基本粒度词为“中华,人民,共和,国”
4
个词。甚至“中华”还能继续切出“中
/
华”也有表义能力(这个后面还会详细分析)
为什么分词需要有不同的粒度呢?因为各有作用。大粒度词的表义能力更强,例如“中华人民共和国”这样的大粒度词,能完整准确的表达一个概念,适合作为文章关键词或标签提取出来。在搜索引擎中直接用大粒度词去构建倒排索引并搜索,一般可得到相关性(准确率)更好的结果。
但从事过信息检索的朋友们想必清楚召回率(
Recall
)和准确率(
Precision
)永远是天平两端互相牵制的两个因素。大粒度词在搜索时会带来召回不足的问题。例如一篇写有“人民共和国在中华大地上诞生了起来”的文章,如果用“中华人民共和国”这个词去倒排索引中搜索,是无法匹配召回的,但拆分为“中华人民
共和国”三个词进行搜索就能找出来。所以一个成熟的分词器,需要因地制宜的设置不同粒度的分词策略,并且最好还能确保在检索词处理(
Query Analysis
)和索引构建(
Index Building
)两端的切分策略保持一致(陈运文)。目前学术界公开的分词测试集合,往往都是只有一种粒度,而且粒度划分标准也并不一致,导致很多评测结果的高低离实际使用效果好坏有一定距离。
在中文分词粒度里,有一个非常令人头疼的问题是
“基本粒度词”是否可继续拆分的问题
。就好比在化学中,通常约定原子(
atom
)是不可再分的基本微粒,由原子来构成各类化学物质。但如果进一步考虑原子可分,那么整个化学的根基就会动摇。同样在中文
NLP
领域,虽然学术界通常都默认基本粒度词不再可分,但在实际工程界,基本词不可再分会导致很多召回不足的问题,引入难以解决的
bad case
。
不要小看这个问题,这是目前限制中文语义理解的一个特别常见的难题
。
要解释清楚来龙去脉,笔者还得从汉语的发展历程说起。
中国古代汉语的表义基本单位是字而不是词
。我从《论语》中拿一句话来举例:“
己所不欲,勿施于人
”。古代汉语一字一词,这句话拿来分词的话结果应该是“
己
/
所
/
不
/
欲,勿
/
施
/
于
/
人
”,可见全部切散为单字了。如果用现代白话文把这句话翻译过来,则意思是“自己都不愿意的方式,不要拿来对待别人”。现代汉语的特点是一般喜欢把单字都双音节化,“
己
-->
自己,欲
-->
愿意,勿
-->
不要,施
-->
对待,人
-->
别人
”。可以看出这些双音节(或多音节)词汇中部分蕴含着来源单字的意义。这种现象在现代汉语词汇中比比皆是,例如
“狮子”,“老虎”,“花儿”,“图钉”,“水果”,“红色”
等,对应“狮,虎,花,钉,果,红”等有意义的单字。而如果把这些双音节词作为不可再切分的基本粒度词的话,当用户搜“狮”的时候,即使文章中出现了词汇“狮子”,也是无法被搜到的。
那么如果将这些基本粒度词再进一步切分呢?会切出“子,老,儿,图,水,色”这样存在转义风险的词汇(即这些单字对应的含义并未体现在原文中),带来很多“副作用”。例如用户搜“老”的时候,当然不希望把介绍“老虎”的文章给找出来。
与此同时,还有另一类的情况是有一些词汇切为单字后,两个单字都分别有表义能力,如“北欧”切为“北
/
欧”,对应“北部,欧洲”两方面的意思。“俄语”切为“俄
/
语”,对应“俄国,语言”,“苦笑”,切为“苦
/
笑”,对应“痛苦,笑容”,以及“海洋”,“图书”,“亲友”,“时空”等都是可细分的。
还有第三类情况是,词汇切分后单字都不能体现原词含义,例如“自然”,如果切分为“自
/
然”,两个字都没有意义。类似的还有“萝卜”,“点心”,“巧克力”等,外来语为多。
之所以前面提到如今中文语义分析时,基本粒度问题是一个关键难题,原因是在现代汉语写作时,既有现代双音节
/
多音节词汇,也夹杂很多源于古代汉语的单字,
半文半白
的现象很常见,这就一下给语义理解带来很大的挑战。不管是切分粒度的选择,还是单字和词汇间关联关系的提取,标题和正文语义的匹配,当面临
文白间杂
时都会遇到难关。常见的情况为:新闻标题为了精炼,经常喜欢采用源自古汉语习惯的单字简称或缩略语。例如“




