暑期Stata培训班招生啦!!!
接力线上的网课培训,我们在今夏又开始新一轮的线下培训啦!8月4日至12日,爬虫俱乐部期待与您的相遇!培训具体内容详见推文
《
暑期Stata编程技术定制培训班
》
。
有问题,不要怕!点击推文底部“
阅读原文
”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱
[email protected]
,我们会及时为您解答哟~
喜大普奔~爬虫俱乐部的github主站正式上线了!我们的网站地址是:
https://stata-club.github.io
,粉丝们可以通过该网站访问过去的推文哟~
好消息:爬虫俱乐部即将推出研究助理供需平台,如果您需要招聘研究助理(Research Assistant or Research Associate),可以将您的需求通过我们的公众号发布;如果您想成为一个RA,可以将您的简历发给我们,进入我们的研究助理数据库。帮我们写优质的推文可以提升您被知名教授雇用的胜算呀!
又到一年毕业季,想起去年毕业的师兄师姐们进入券商做分析师的可不少。他们的研报“建议”你们想不想看一看?今天笔者帮大家把他们“搬”出来。
我们打开和讯网一个公司研报查询页面
(http://yanbao.stock.hexun.com/listnews1_1.shtml)
,我们看到网址中
1.shtml
中的
1
代表的就是页数,页面如下所示。大家可以尝试一下,换一个数字,即到其他页。
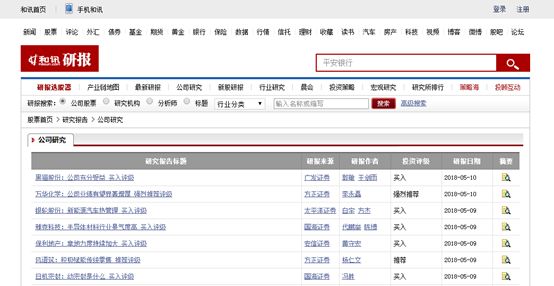
如何获取这样一个网页的研报的各项信息(标题、来源、作者、评级、日期)呢?现在我们一步一步进行分析:
我们以抓取第一页研报为例。
clear
cap mkdir E:/爬虫
cd E:/爬虫
copy "http://yanbao.stock.hexun.com/listnews1_1.shtml" temp.txt,replace
unicode encoding set gb18030
unicode translate temp.txt, transutf8
unicode erasebackups, badidea
以第一页为例,我们打开其网页源代码,通过分析发现标签“
”仅存在于我们所需信息所在行。

因此,我们读入数据并保留含有标签
“
”
的行。
infix strL v 1-50000 using temp.txt, clear
keep if index(v,"")

接下来,我们用
“
”
做分隔,然后将
HTML
标签(尖括号以及尖括号里边的内容)替换为
#
。
split v,parse("")
drop v
sxpose,clear
ren _var1 v
replace v = ustrregexra(v,"<.>","#")
分隔替换后的数据见下图:

其次,我们打算将这些信息按#分割,但是发现部分研报的作者是2名及2名以上的,为了避免后续把多个姓名分开,我们把姓名间的
#
替换为“
;
”。此外,由于分隔信息的#个数不一(见上图),为了简化处理,我们将多个#替换为一个
#
:
replace v = ustrregexra(v,"#\s+#"
,";")
replace v = ustrregexra(v,"#+","#")
结果如下:

最后,把v中信息按
#
分开并命名。
split v,p(drop v v1
rename v* (报告标题 研报来源 研报作者 投资评级 研报日期)
save 分析师,replace
如下图所示:

附完整程序:
clear
cap mkdir E:/爬虫
cd E:/爬虫
forvalue i = 1(1)10 {
clear
cap copy "http://yanbao.stock.hexun.com/listnews1_`i'.shtml" temp.txt,replace
while _rc != 0 {
sleep 10000
cap copy "http://yanbao.stock.hexun.com/listnews1_`i'.shtml" temp.txt,replace
}
unicode encoding set gb18030
unicode translate temp.txt, transutf8
unicode erasebackups, badidea
infix strL v 1-50000 using temp.txt, clear
keep if index(v,"")
split v,parse("")
drop v
sxpose,clear
ren _var1 v
replace v =ustrregexra(v,"<.>","#")
replace v =ustrregexra(v,"#\s+#",";")
replace v =ustrregexra(v,"#+","#")
split v,p(#)
drop v v1
rename v* (报告标题 研报来源 研报作者 投资评级 研报日期)
save `i'.dta,replace
}
openall
save 分析师,replace
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~
往期推文推荐:
1.爬虫俱乐部新版块--和我们一起学习Python
2.hello,MySQL--Stata连接MySQL数据库
3.hello,MySQL--odbcload读取MySQL数据
4.再爬俱乐部网站,推文目录大放送!
5.用Stata生成二维码—我的心思你来扫
6.
Hello,MySQL-odbc exec查询与更新










