当你爬取了大量的网页,里面肯定有很多重复的内容,这些重复的内容需要去重来解决。
一个著名的算法就是SimHash算法。
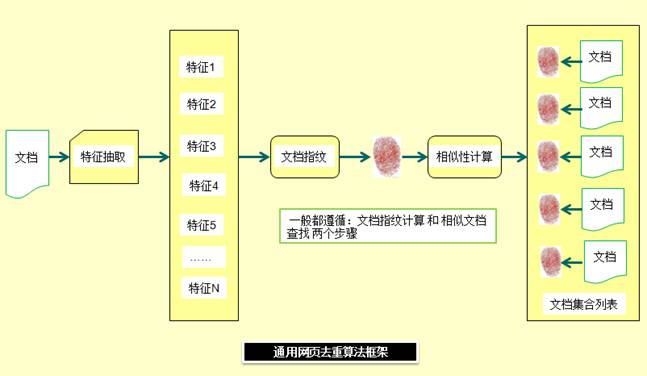
通用的去重算法框架如图所示(图来自互联网)
对于一篇文档,首先要抽取出能代表这篇文章内容的特征,当然特征数目肯定是很多的,如果比较两篇文章的所有特征,太费时间了,所以要对特征进行一定的运算,称为文档指纹,指纹就像人的指纹一样,虽然信息量不大,相对比较容易相互比较,但是能够代表区分不同人的信息。最后就是基于指纹进行相似度计算,相似度大的,则为文档重复,相似度小的,则文档不重复。
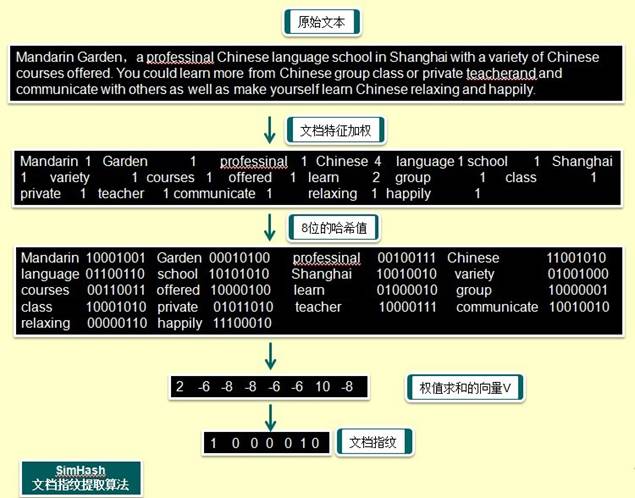
对于SimHash来讲,计算方法如下:
1、分词
,讲文本分词形成这个文章的特征单词。最后形成去掉停词之类的单词序列,并统计每个词出现的数目tf作为权重
2、hash
,通过hash算法把每个词变成hash值,这里以8位hash值为例子。
3、加权合并
,通过 2步骤的hash生成结果中的每一位,乘以权重,然后加起来,形成权值求和的向量
4、降维
,把3步算出来的 向量变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。
上面的指纹数目使用8位做简单的演示,真实的使用中往往使用64bits指纹, <= 3bit 不同算相似。
然而在64位中逐个比较,直到找出3个不同位来,计算量还是很大的,所以就有了如下的SimHash的索引结构。
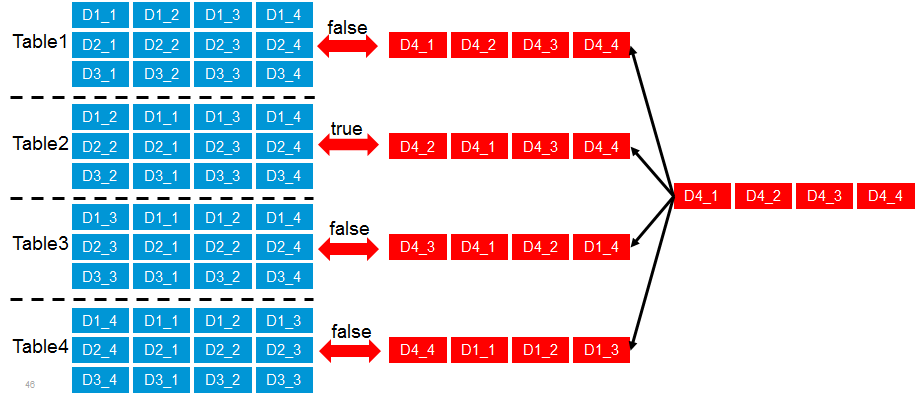
将64位的二进制串等分成四块,每块16位,将所有的文章的simhash保存四份,分别保存在四个Table里面,在第一个Table里面,第一个16位在前面,第二个Table里面,第二个16位在前面,以此类推。
来了一篇新的文档的时候,也将64位分成四份,变成如图红色的四个序列。
首先采用精确匹配的方式查找前16位,如果在四个Table中都匹配不中,则说明至少有四位是不同的,已经不相似。
如果和其中一个Table比较中了,然后在Table中再进行比较。
下面我们来看如何使用Map-Reduce来解决这个问题。




